 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarcin Detyniecki
OptiGrad: A Fair and more Efficient Price Elasticity Optimization via a Gradient Based Learning
Apr 16, 2024
This paper presents a novel approach to optimizing profit margins in non-life insurance markets through a gradient descent-based method, targeting three key objectives: 1) maximizing profit margins, 2) ensuring conversion rates, and 3) enforcing fairness criteria such as demographic parity (DP). Traditional pricing optimization, which heavily lean on linear and semi definite programming, encounter challenges in balancing profitability and fairness. These challenges become especially pronounced in situations that necessitate continuous rate adjustments and the incorporation of fairness criteria. Specifically, indirect Ratebook optimization, a widely-used method for new business price setting, relies on predictor models such as XGBoost or GLMs/GAMs to estimate on downstream individually optimized prices. However, this strategy is prone to sequential errors and struggles to effectively manage optimizations for continuous rate scenarios. In practice, to save time actuaries frequently opt for optimization within discrete intervals (e.g., range of [-20\%, +20\%] with fix increments) leading to approximate estimations. Moreover, to circumvent infeasible solutions they often use relaxed constraints leading to suboptimal pricing strategies. The reverse-engineered nature of traditional models complicates the enforcement of fairness and can lead to biased outcomes. Our method addresses these challenges by employing a direct optimization strategy in the continuous space of rates and by embedding fairness through an adversarial predictor model. This innovation not only reduces sequential errors and simplifies the complexities found in traditional models but also directly integrates fairness measures into the commercial premium calculation. We demonstrate improved margin performance and stronger enforcement of fairness highlighting the critical need to evolve existing pricing strategies.
On the Fairness ROAD: Robust Optimization for Adversarial Debiasing
Oct 27, 2023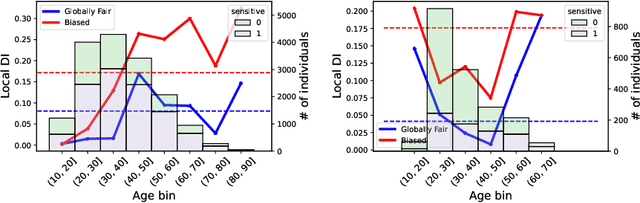
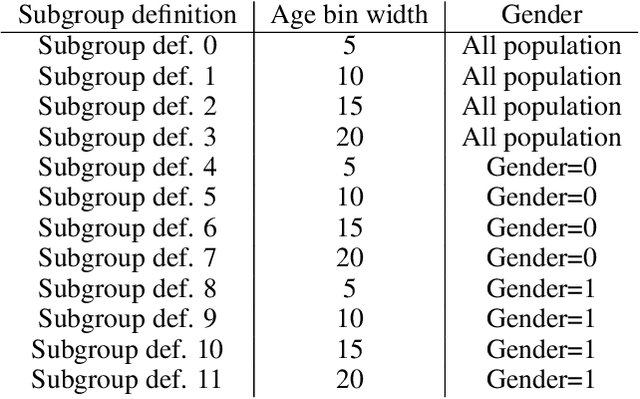
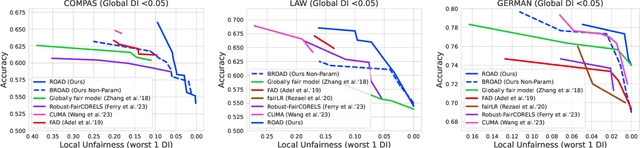
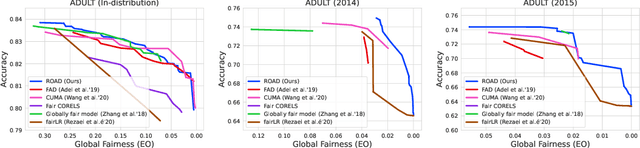
In the field of algorithmic fairness, significant attention has been put on group fairness criteria, such as Demographic Parity and Equalized Odds. Nevertheless, these objectives, measured as global averages, have raised concerns about persistent local disparities between sensitive groups. In this work, we address the problem of local fairness, which ensures that the predictor is unbiased not only in terms of expectations over the whole population, but also within any subregion of the feature space, unknown at training time. To enforce this objective, we introduce ROAD, a novel approach that leverages the Distributionally Robust Optimization (DRO) framework within a fair adversarial learning objective, where an adversary tries to infer the sensitive attribute from the predictions. Using an instance-level re-weighting strategy, ROAD is designed to prioritize inputs that are likely to be locally unfair, i.e. where the adversary faces the least difficulty in reconstructing the sensitive attribute. Numerical experiments demonstrate the effectiveness of our method: it achieves Pareto dominance with respect to local fairness and accuracy for a given global fairness level across three standard datasets, and also enhances fairness generalization under distribution shift.
Achieving Diversity in Counterfactual Explanations: a Review and Discussion
May 10, 2023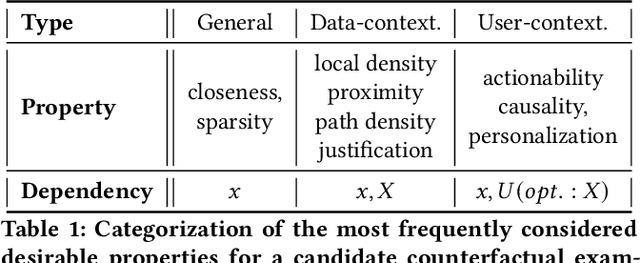
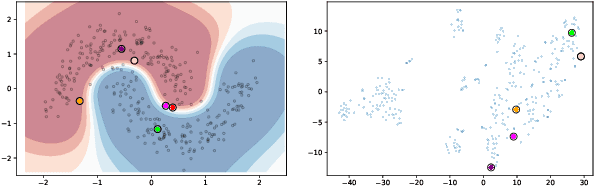
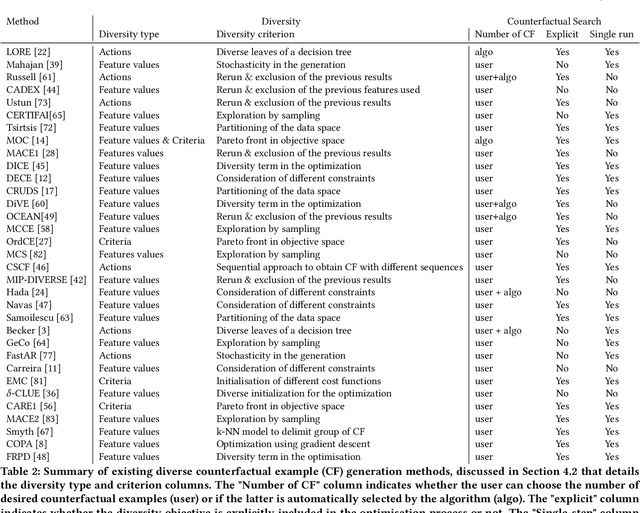
In the field of Explainable Artificial Intelligence (XAI), counterfactual examples explain to a user the predictions of a trained decision model by indicating the modifications to be made to the instance so as to change its associated prediction. These counterfactual examples are generally defined as solutions to an optimization problem whose cost function combines several criteria that quantify desiderata for a good explanation meeting user needs. A large variety of such appropriate properties can be considered, as the user needs are generally unknown and differ from one user to another; their selection and formalization is difficult. To circumvent this issue, several approaches propose to generate, rather than a single one, a set of diverse counterfactual examples to explain a prediction. This paper proposes a review of the numerous, sometimes conflicting, definitions that have been proposed for this notion of diversity. It discusses their underlying principles as well as the hypotheses on the user needs they rely on and proposes to categorize them along several dimensions (explicit vs implicit, universe in which they are defined, level at which they apply), leading to the identification of further research challenges on this topic.
When Mitigating Bias is Unfair: A Comprehensive Study on the Impact of Bias Mitigation Algorithms
Feb 14, 2023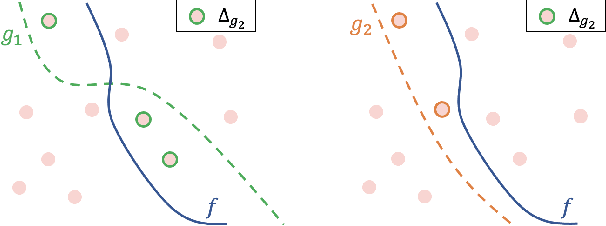
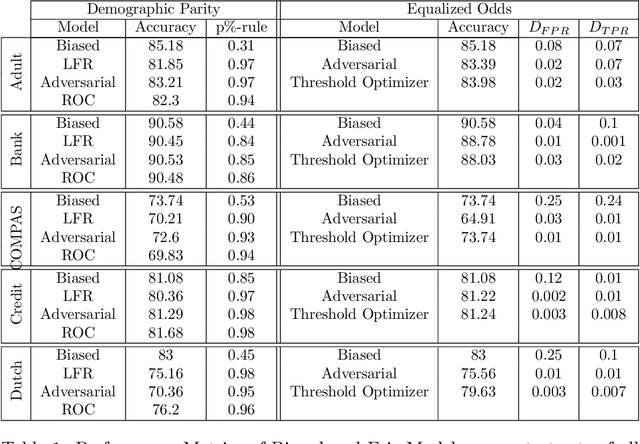
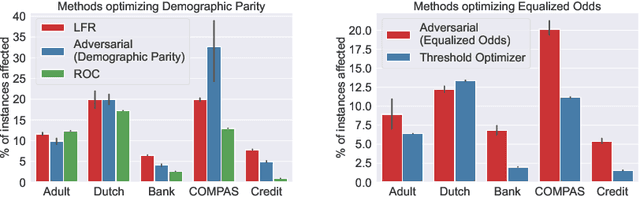

Most works on the fairness of machine learning systems focus on the blind optimization of common fairness metrics, such as Demographic Parity and Equalized Odds. In this paper, we conduct a comparative study of several bias mitigation approaches to investigate their behaviors at a fine grain, the prediction level. Our objective is to characterize the differences between fair models obtained with different approaches. With comparable performances in fairness and accuracy, are the different bias mitigation approaches impacting a similar number of individuals? Do they mitigate bias in a similar way? Do they affect the same individuals when debiasing a model? Our findings show that bias mitigation approaches differ a lot in their strategies, both in the number of impacted individuals and the populations targeted. More surprisingly, we show these results even apply for several runs of the same mitigation approach. These findings raise questions about the limitations of the current group fairness metrics, as well as the arbitrariness, hence unfairness, of the whole debiasing process.
Integrating Prior Knowledge in Post-hoc Explanations
Apr 25, 2022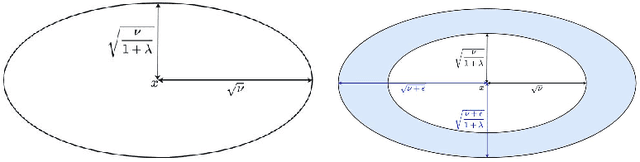
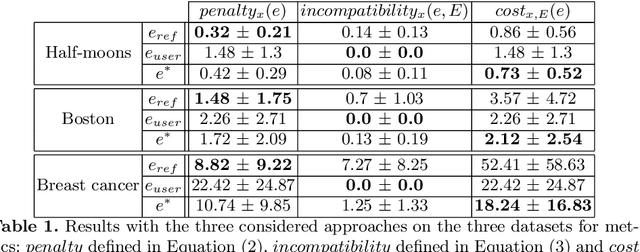
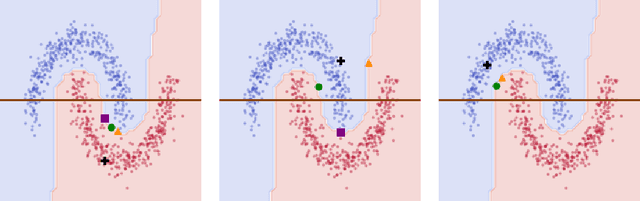
In the field of eXplainable Artificial Intelligence (XAI), post-hoc interpretability methods aim at explaining to a user the predictions of a trained decision model. Integrating prior knowledge into such interpretability methods aims at improving the explanation understandability and allowing for personalised explanations adapted to each user. In this paper, we propose to define a cost function that explicitly integrates prior knowledge into the interpretability objectives: we present a general framework for the optimization problem of post-hoc interpretability methods, and show that user knowledge can thus be integrated to any method by adding a compatibility term in the cost function. We instantiate the proposed formalization in the case of counterfactual explanations and propose a new interpretability method called Knowledge Integration in Counterfactual Explanation (KICE) to optimize it. The paper performs an experimental study on several benchmark data sets to characterize the counterfactual instances generated by KICE, as compared to reference methods.
A fair pricing model via adversarial learning
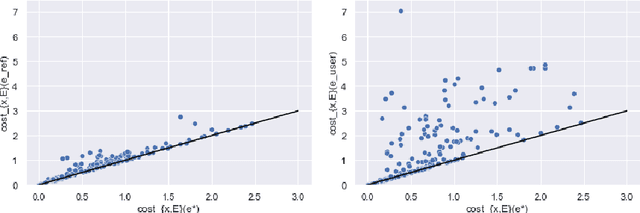
Mar 07, 2022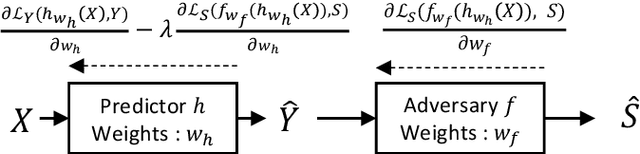
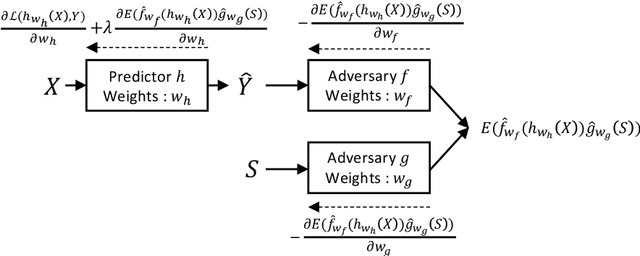
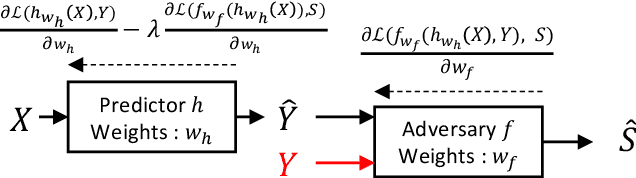
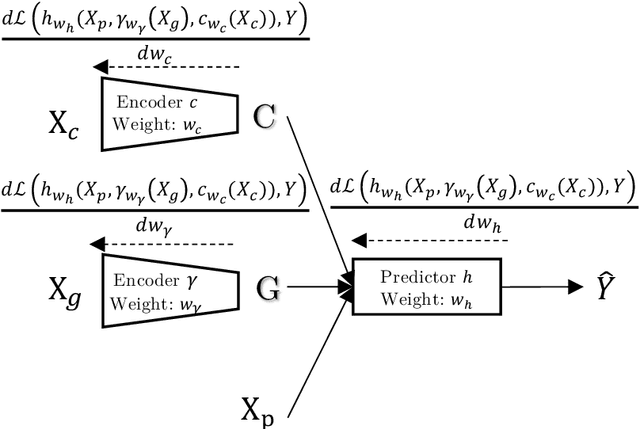
At the core of insurance business lies classification between risky and non-risky insureds, actuarial fairness meaning that risky insureds should contribute more and pay a higher premium than non-risky or less-risky ones. Actuaries, therefore, use econometric or machine learning techniques to classify, but the distinction between a fair actuarial classification and "discrimination" is subtle. For this reason, there is a growing interest about fairness and discrimination in the actuarial community Lindholm, Richman, Tsanakas, and Wuthrich (2022). Presumably, non-sensitive characteristics can serve as substitutes or proxies for protected attributes. For example, the color and model of a car, combined with the driver's occupation, may lead to an undesirable gender bias in the prediction of car insurance prices. Surprisingly, we will show that debiasing the predictor alone may be insufficient to maintain adequate accuracy (1). Indeed, the traditional pricing model is currently built in a two-stage structure that considers many potentially biased components such as car or geographic risks. We will show that this traditional structure has significant limitations in achieving fairness. For this reason, we have developed a novel pricing model approach. Recently some approaches have Blier-Wong, Cossette, Lamontagne, and Marceau (2021); Wuthrich and Merz (2021) shown the value of autoencoders in pricing. In this paper, we will show that (2) this can be generalized to multiple pricing factors (geographic, car type), (3) it perfectly adapted for a fairness context (since it allows to debias the set of pricing components): We extend this main idea to a general framework in which a single whole pricing model is trained by generating the geographic and car pricing components needed to predict the pure premium while mitigating the unwanted bias according to the desired metric.
Fairness without the sensitive attribute via Causal Variational Autoencoder
Sep 10, 2021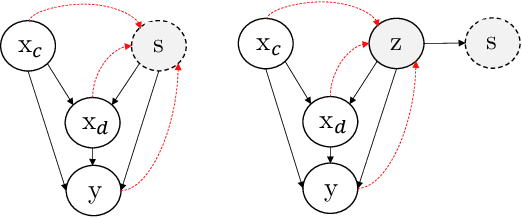
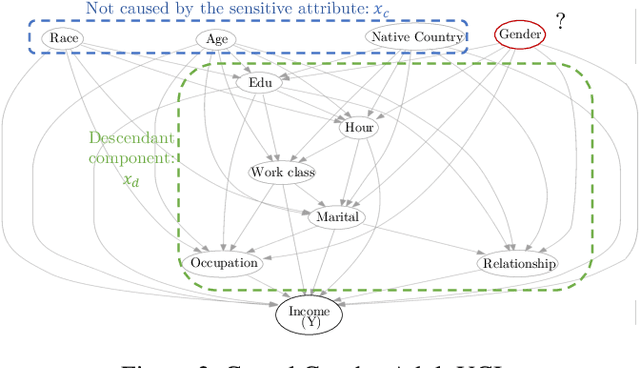
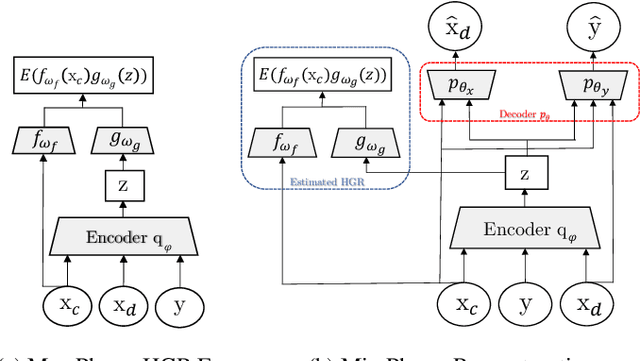
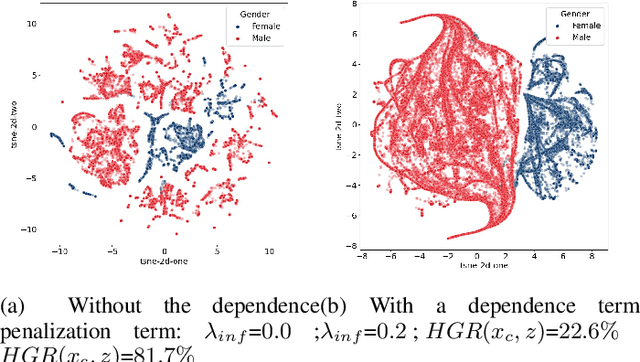
In recent years, most fairness strategies in machine learning models focus on mitigating unwanted biases by assuming that the sensitive information is observed. However this is not always possible in practice. Due to privacy purposes and var-ious regulations such as RGPD in EU, many personal sensitive attributes are frequently not collected. We notice a lack of approaches for mitigating bias in such difficult settings, in particular for achieving classical fairness objectives such as Demographic Parity and Equalized Odds. By leveraging recent developments for approximate inference, we propose an approach to fill this gap. Based on a causal graph, we rely on a new variational auto-encoding based framework named SRCVAE to infer a sensitive information proxy, that serve for bias mitigation in an adversarial fairness approach. We empirically demonstrate significant improvements over existing works in the field. We observe that the generated proxy's latent space recovers sensitive information and that our approach achieves a higher accuracy while obtaining the same level of fairness on two real datasets, as measured using com-mon fairness definitions.
How to choose an Explainability Method? Towards a Methodical Implementation of XAI in Practice
Jul 09, 2021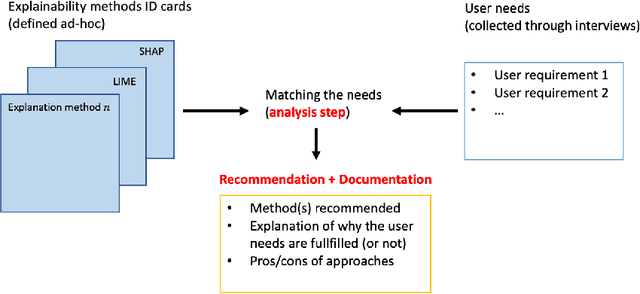
Explainability is becoming an important requirement for organizations that make use of automated decision-making due to regulatory initiatives and a shift in public awareness. Various and significantly different algorithmic methods to provide this explainability have been introduced in the field, but the existing literature in the machine learning community has paid little attention to the stakeholder whose needs are rather studied in the human-computer interface community. Therefore, organizations that want or need to provide this explainability are confronted with the selection of an appropriate method for their use case. In this paper, we argue there is a need for a methodology to bridge the gap between stakeholder needs and explanation methods. We present our ongoing work on creating this methodology to help data scientists in the process of providing explainability to stakeholders. In particular, our contributions include documents used to characterize XAI methods and user requirements (shown in Appendix), which our methodology builds upon.
Understanding surrogate explanations: the interplay between complexity, fidelity and coverage
Jul 09, 2021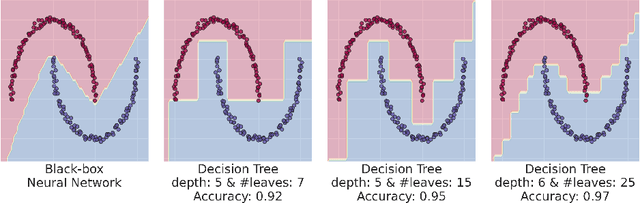
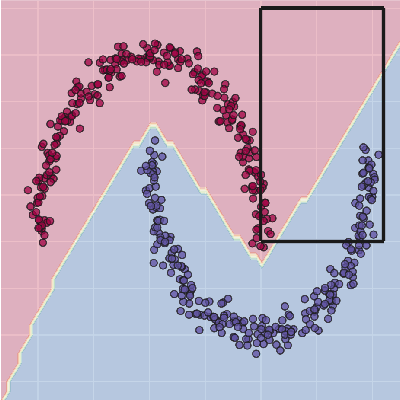
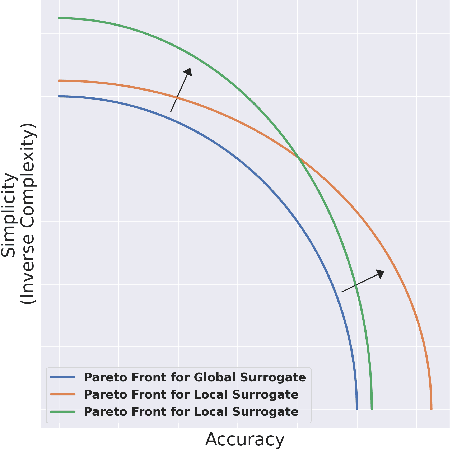
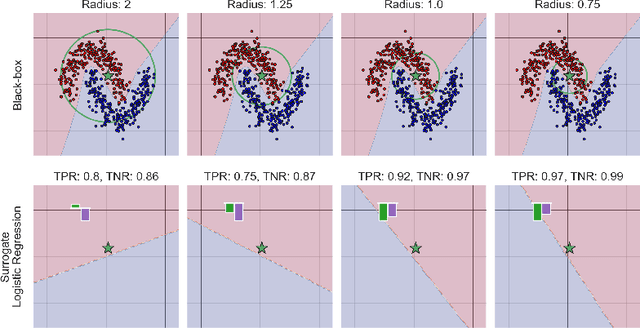
This paper analyses the fundamental ingredients behind surrogate explanations to provide a better understanding of their inner workings. We start our exposition by considering global surrogates, describing the trade-off between complexity of the surrogate and fidelity to the black-box being modelled. We show that transitioning from global to local - reducing coverage - allows for more favourable conditions on the Pareto frontier of fidelity-complexity of a surrogate. We discuss the interplay between complexity, fidelity and coverage, and consider how different user needs can lead to problem formulations where these are either constraints or penalties. We also present experiments that demonstrate how the local surrogate interpretability procedure can be made interactive and lead to better explanations.
On the overlooked issue of defining explanation objectives for local-surrogate explainers
Jun 10, 2021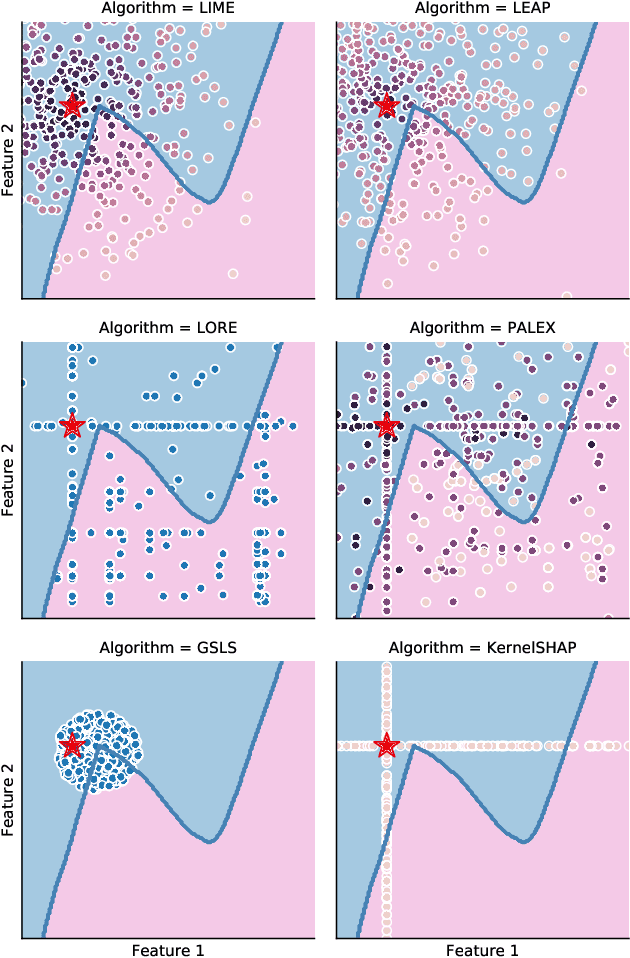

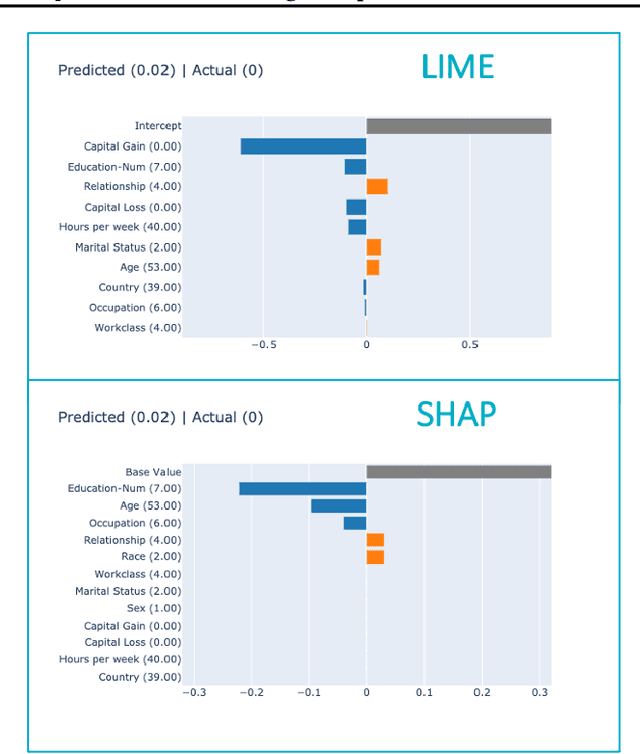
Local surrogate approaches for explaining machine learning model predictions have appealing properties, such as being model-agnostic and flexible in their modelling. Several methods exist that fit this description and share this goal. However, despite their shared overall procedure, they set out different objectives, extract different information from the black-box, and consequently produce diverse explanations, that are -- in general -- incomparable. In this work we review the similarities and differences amongst multiple methods, with a particular focus on what information they extract from the model, as this has large impact on the output: the explanation. We discuss the implications of the lack of agreement, and clarity, amongst the methods' objectives on the research and practice of explainability.