 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarco Pistoia
Privacy-preserving quantum federated learning via gradient hiding
Dec 07, 2023
Distributed quantum computing, particularly distributed quantum machine learning, has gained substantial prominence for its capacity to harness the collective power of distributed quantum resources, transcending the limitations of individual quantum nodes. Meanwhile, the critical concern of privacy within distributed computing protocols remains a significant challenge, particularly in standard classical federated learning (FL) scenarios where data of participating clients is susceptible to leakage via gradient inversion attacks by the server. This paper presents innovative quantum protocols with quantum communication designed to address the FL problem, strengthen privacy measures, and optimize communication efficiency. In contrast to previous works that leverage expressive variational quantum circuits or differential privacy techniques, we consider gradient information concealment using quantum states and propose two distinct FL protocols, one based on private inner-product estimation and the other on incremental learning. These protocols offer substantial advancements in privacy preservation with low communication resources, forging a path toward efficient quantum communication-assisted FL protocols and contributing to the development of secure distributed quantum machine learning, thus addressing critical privacy concerns in the quantum computing era.
Blind quantum machine learning with quantum bipartite correlator
Oct 19, 2023
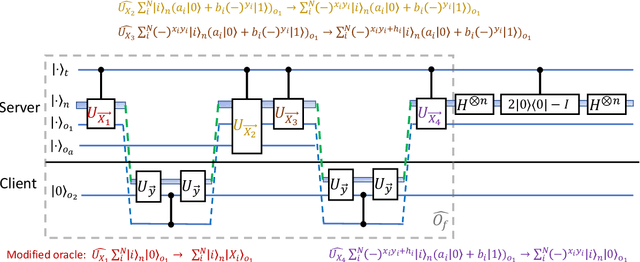
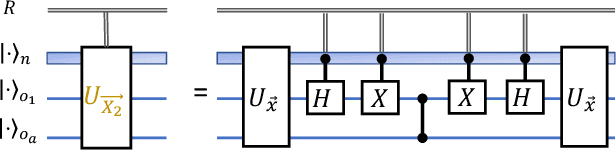
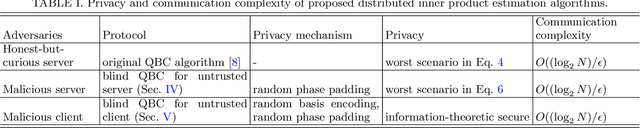
Distributed quantum computing is a promising computational paradigm for performing computations that are beyond the reach of individual quantum devices. Privacy in distributed quantum computing is critical for maintaining confidentiality and protecting the data in the presence of untrusted computing nodes. In this work, we introduce novel blind quantum machine learning protocols based on the quantum bipartite correlator algorithm. Our protocols have reduced communication overhead while preserving the privacy of data from untrusted parties. We introduce robust algorithm-specific privacy-preserving mechanisms with low computational overhead that do not require complex cryptographic techniques. We then validate the effectiveness of the proposed protocols through complexity and privacy analysis. Our findings pave the way for advancements in distributed quantum computing, opening up new possibilities for privacy-aware machine learning applications in the era of quantum technologies.
Expressive variational quantum circuits provide inherent privacy in federated learning
Sep 25, 2023Federated learning has emerged as a viable distributed solution to train machine learning models without the actual need to share data with the central aggregator. However, standard neural network-based federated learning models have been shown to be susceptible to data leakage from the gradients shared with the server. In this work, we introduce federated learning with variational quantum circuit model built using expressive encoding maps coupled with overparameterized ans\"atze. We show that expressive maps lead to inherent privacy against gradient inversion attacks, while overparameterization ensures model trainability. Our privacy framework centers on the complexity of solving the system of high-degree multivariate Chebyshev polynomials generated by the gradients of quantum circuit. We present compelling arguments highlighting the inherent difficulty in solving these equations, both in exact and approximate scenarios. Additionally, we delve into machine learning-based attack strategies and establish a direct connection between overparameterization in the original federated learning model and underparameterization in the attack model. Furthermore, we provide numerical scaling arguments showcasing that underparameterization of the expressive map in the attack model leads to the loss landscape being swamped with exponentially many spurious local minima points, thus making it extremely hard to realize a successful attack. This provides a strong claim, for the first time, that the nature of quantum machine learning models inherently helps prevent data leakage in federated learning.
Des-q: a quantum algorithm to construct and efficiently retrain decision trees for regression and binary classification
Sep 22, 2023Decision trees are widely used in machine learning due to their simplicity in construction and interpretability. However, as data sizes grow, traditional methods for constructing and retraining decision trees become increasingly slow, scaling polynomially with the number of training examples. In this work, we introduce a novel quantum algorithm, named Des-q, for constructing and retraining decision trees in regression and binary classification tasks. Assuming the data stream produces small increments of new training examples, we demonstrate that our Des-q algorithm significantly reduces the time required for tree retraining, achieving a poly-logarithmic time complexity in the number of training examples, even accounting for the time needed to load the new examples into quantum-accessible memory. Our approach involves building a decision tree algorithm to perform k-piecewise linear tree splits at each internal node. These splits simultaneously generate multiple hyperplanes, dividing the feature space into k distinct regions. To determine the k suitable anchor points for these splits, we develop an efficient quantum-supervised clustering method, building upon the q-means algorithm of Kerenidis et al. Des-q first efficiently estimates each feature weight using a novel quantum technique to estimate the Pearson correlation. Subsequently, we employ weighted distance estimation to cluster the training examples in k disjoint regions and then proceed to expand the tree using the same procedure. We benchmark the performance of the simulated version of our algorithm against the state-of-the-art classical decision tree for regression and binary classification on multiple data sets with numerical features. Further, we showcase that the proposed algorithm exhibits similar performance to the state-of-the-art decision tree while significantly speeding up the periodic tree retraining.
Quantum Deep Hedging
Mar 29, 2023
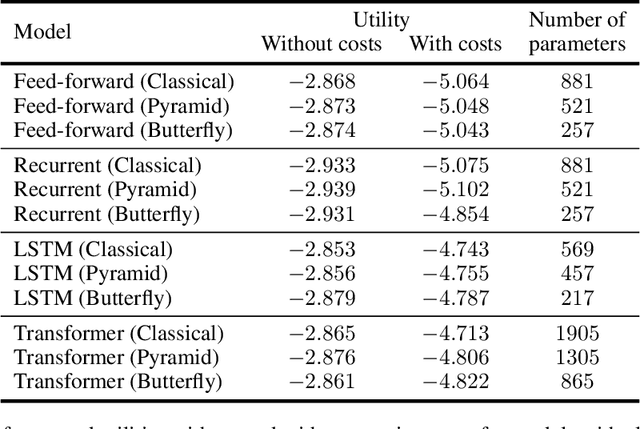
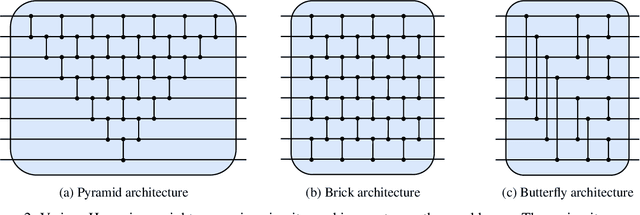
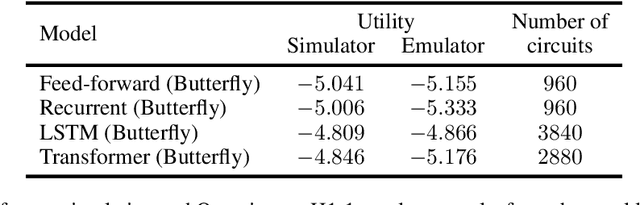
Quantum machine learning has the potential for a transformative impact across industry sectors and in particular in finance. In our work we look at the problem of hedging where deep reinforcement learning offers a powerful framework for real markets. We develop quantum reinforcement learning methods based on policy-search and distributional actor-critic algorithms that use quantum neural network architectures with orthogonal and compound layers for the policy and value functions. We prove that the quantum neural networks we use are trainable, and we perform extensive simulations that show that quantum models can reduce the number of trainable parameters while achieving comparable performance and that the distributional approach obtains better performance than other standard approaches, both classical and quantum. We successfully implement the proposed models on a trapped-ion quantum processor, utilizing circuits with up to $16$ qubits, and observe performance that agrees well with noiseless simulation. Our quantum techniques are general and can be applied to other reinforcement learning problems beyond hedging.
Numerical evidence against advantage with quantum fidelity kernels on classical data
Nov 29, 2022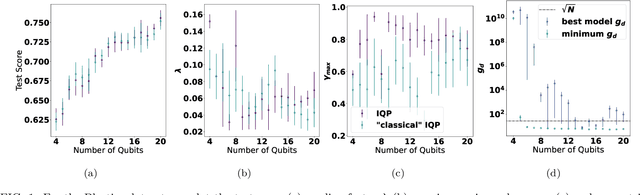

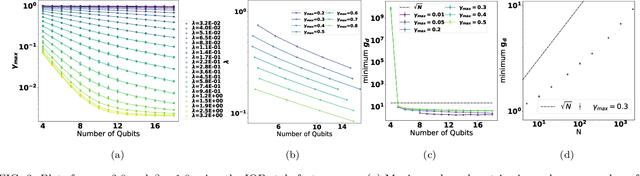

Quantum machine learning techniques are commonly considered one of the most promising candidates for demonstrating practical quantum advantage. In particular, quantum kernel methods have been demonstrated to be able to learn certain classically intractable functions efficiently if the kernel is well-aligned with the target function. In the more general case, quantum kernels are known to suffer from exponential "flattening" of the spectrum as the number of qubits grows, preventing generalization and necessitating the control of the inductive bias by hyperparameters. We show that the general-purpose hyperparameter tuning techniques proposed to improve the generalization of quantum kernels lead to the kernel becoming well-approximated by a classical kernel, removing the possibility of quantum advantage. We provide extensive numerical evidence for this phenomenon utilizing multiple previously studied quantum feature maps and both synthetic and real data. Our results show that unless novel techniques are developed to control the inductive bias of quantum kernels, they are unlikely to provide a quantum advantage on classical data.
MaSS: Multi-attribute Selective Suppression
Oct 18, 2022



The recent rapid advances in machine learning technologies largely depend on the vast richness of data available today, in terms of both the quantity and the rich content contained within. For example, biometric data such as images and voices could reveal people's attributes like age, gender, sentiment, and origin, whereas location/motion data could be used to infer people's activity levels, transportation modes, and life habits. Along with the new services and applications enabled by such technological advances, various governmental policies are put in place to regulate such data usage and protect people's privacy and rights. As a result, data owners often opt for simple data obfuscation (e.g., blur people's faces in images) or withholding data altogether, which leads to severe data quality degradation and greatly limits the data's potential utility. Aiming for a sophisticated mechanism which gives data owners fine-grained control while retaining the maximal degree of data utility, we propose Multi-attribute Selective Suppression, or MaSS, a general framework for performing precisely targeted data surgery to simultaneously suppress any selected set of attributes while preserving the rest for downstream machine learning tasks. MaSS learns a data modifier through adversarial games between two sets of networks, where one is aimed at suppressing selected attributes, and the other ensures the retention of the rest of the attributes via general contrastive loss as well as explicit classification metrics. We carried out an extensive evaluation of our proposed method using multiple datasets from different domains including facial images, voice audio, and video clips, and obtained promising results in MaSS' generalizability and capability of suppressing targeted attributes without negatively affecting the data's usability in other downstream ML tasks.
Quantum Machine Learning for Finance
Sep 09, 2021Quantum computers are expected to surpass the computational capabilities of classical computers during this decade, and achieve disruptive impact on numerous industry sectors, particularly finance. In fact, finance is estimated to be the first industry sector to benefit from Quantum Computing not only in the medium and long terms, but even in the short term. This review paper presents the state of the art of quantum algorithms for financial applications, with particular focus to those use cases that can be solved via Machine Learning.
More Is Less: Learning Efficient Video Representations by Big-Little Network and Depthwise Temporal Aggregation
Dec 02, 2019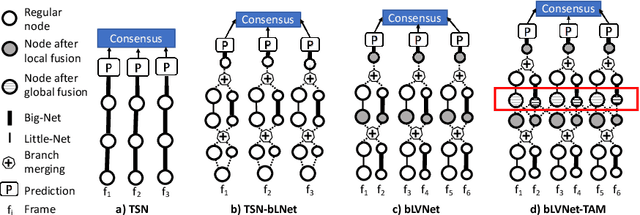
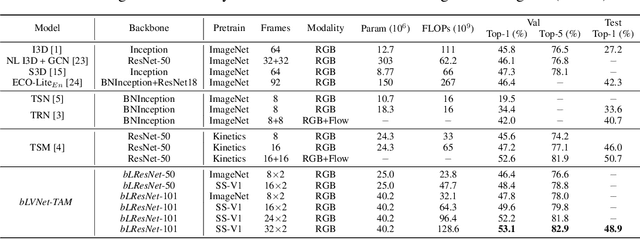

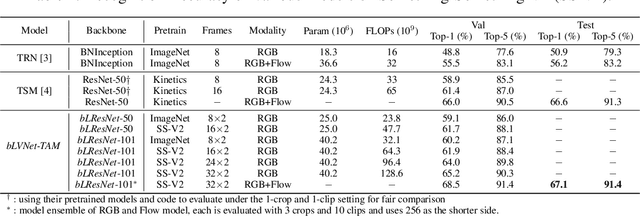
Current state-of-the-art models for video action recognition are mostly based on expensive 3D ConvNets. This results in a need for large GPU clusters to train and evaluate such architectures. To address this problem, we present a lightweight and memory-friendly architecture for action recognition that performs on par with or better than current architectures by using only a fraction of resources. The proposed architecture is based on a combination of a deep subnet operating on low-resolution frames with a compact subnet operating on high-resolution frames, allowing for high efficiency and accuracy at the same time. We demonstrate that our approach achieves a reduction by $3\sim4$ times in FLOPs and $\sim2$ times in memory usage compared to the baseline. This enables training deeper models with more input frames under the same computational budget. To further obviate the need for large-scale 3D convolutions, a temporal aggregation module is proposed to model temporal dependencies in a video at very small additional computational costs. Our models achieve strong performance on several action recognition benchmarks including Kinetics, Something-Something and Moments-in-time. The code and models are available at https://github.com/IBM/bLVNet-TAM.
A Domain-agnostic, Noise-resistant, Hardware-efficient Evolutionary Variational Quantum Eigensolver
Nov 18, 2019
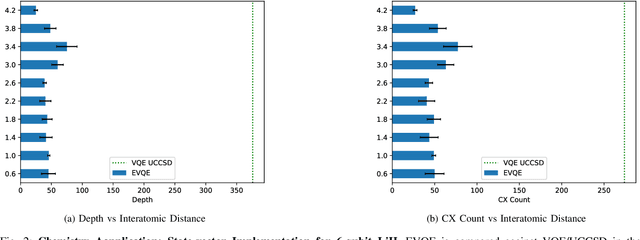
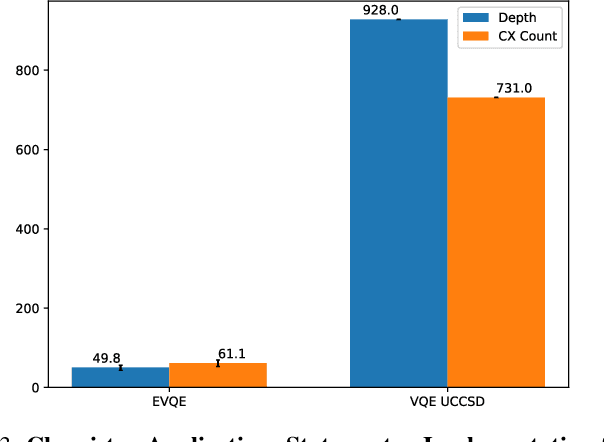

Variational quantum algorithms have shown promise in numerous fields due to their versatility in solving problems of scientific and commercial interest. However, leading algorithms for Hamiltonian simulation, such as the Variational Quantum Eigensolver (VQE), use fixed preconstructed ansatzes, limiting their general applicability and accuracy. Thus, variational forms---the quantum circuits that implement ansatzes ---are either crafted heuristically or by encoding domain-specific knowledge. In this paper, we present an Evolutionary Variational Quantum Eigensolver (EVQE), a novel variational algorithm that uses evolutionary programming techniques to minimize the expectation value of a given Hamiltonian by dynamically generating and optimizing an ansatz. The algorithm is equally applicable to optimization problems in all domains, obtaining accurate energy evaluations with hardware-efficient ansatzes. In molecular simulations, the variational forms generated by EVQE are up to $18.6\times$ shallower and use up to $12\times$ fewer CX gates than those obtained by VQE with a unitary coupled cluster ansatz. EVQE demonstrates significant noise-resistance properties, obtaining results in noisy simulation with at least $3.6\times$ less error than VQE using any tested ansatz configuration. We successfully evaluated EVQE on a real 5-qubit IBMQ quantum computer. The experimental results, which we obtained both via simulation and on real quantum hardware, demonstrate the effectiveness of EVQE for general-purpose optimization on the quantum computers of the present and near future.