 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMark Woodward
Training an Interactive Helper
Jul 02, 2019
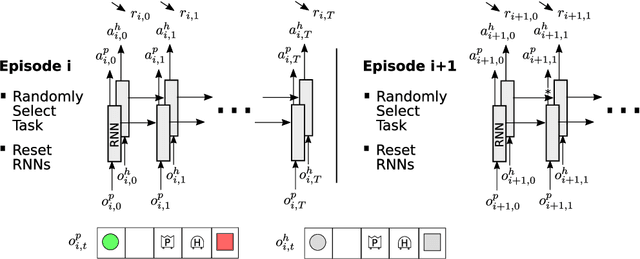
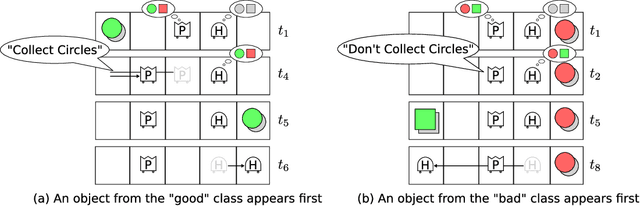
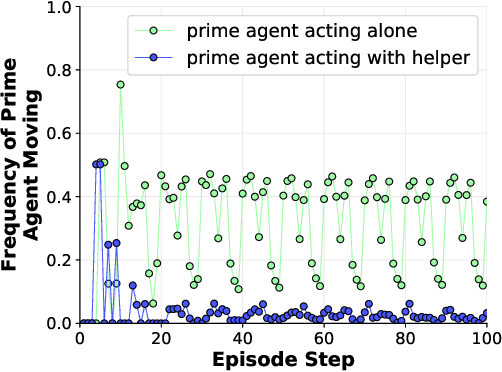
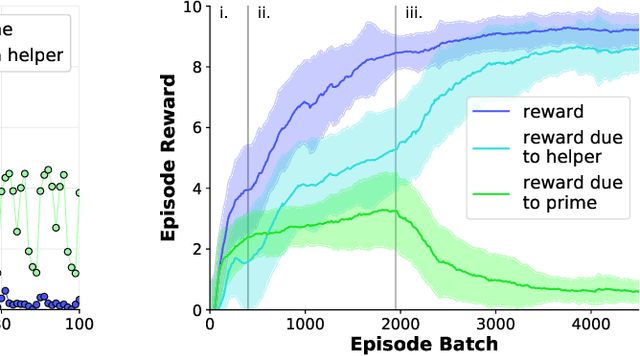
Developing agents that can quickly adapt their behavior to new tasks remains a challenge. Meta-learning has been applied to this problem, but previous methods require either specifying a reward function which can be tedious or providing demonstrations which can be inefficient. In this paper, we investigate if, and how, a "helper" agent can be trained to interactively adapt their behavior to maximize the reward of another agent, whom we call the "prime" agent, without observing their reward or receiving explicit demonstrations. To this end, we propose to meta-learn a helper agent along with a prime agent, who, during training, observes the reward function and serves as a surrogate for a human prime. We introduce a distribution of multi-agent cooperative foraging tasks, in which only the prime agent knows the objects that should be collected. We demonstrate that, from the emerged physical communication, the trained helper rapidly infers and collects the correct objects.
Learning to Interactively Learn and Assist
Jul 01, 2019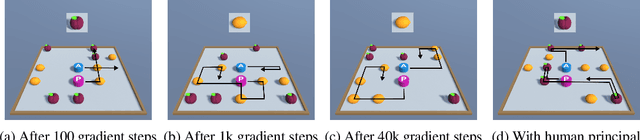

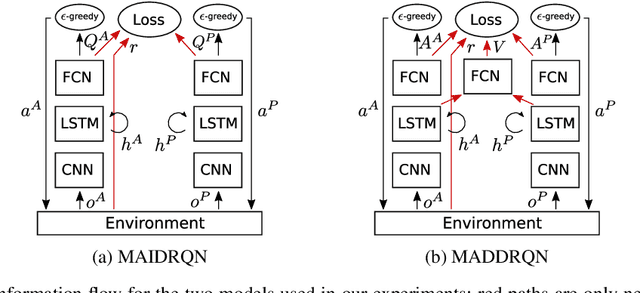

When deploying autonomous agents in the real world, we need effective ways of communicating objectives to them. Traditional skill learning has revolved around reinforcement and imitation learning, each with rigid constraints on the format of information exchanged between the human and the agent. While scalar rewards carry little information, demonstrations require significant effort to provide and may carry more information than is necessary. Furthermore, rewards and demonstrations are often defined and collected before training begins, when the human is most uncertain about what information would help the agent. In contrast, when humans communicate objectives with each other, they make use of a large vocabulary of informative behaviors, including non-verbal communication, and often communicate throughout learning, responding to observed behavior. In this way, humans communicate intent with minimal effort. In this paper, we propose such interactive learning as an alternative to reward or demonstration-driven learning. To accomplish this, we introduce a multi-agent training framework that enables an agent to learn from another agent who knows the current task. Through a series of experiments, we demonstrate the emergence of a variety of interactive learning behaviors, including information-sharing, information-seeking, and question-answering. Most importantly, we find that our approach produces an agent that is capable of learning interactively from a human user, without a set of explicit demonstrations or a reward function, and achieving significantly better performance cooperatively with a human than a human performing the task alone.
Active One-shot Learning
Feb 21, 2017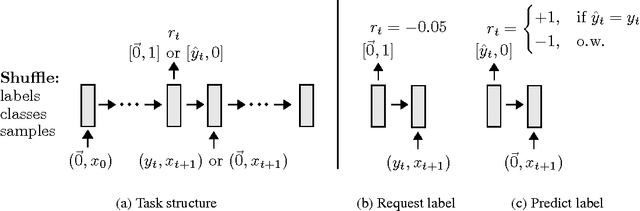

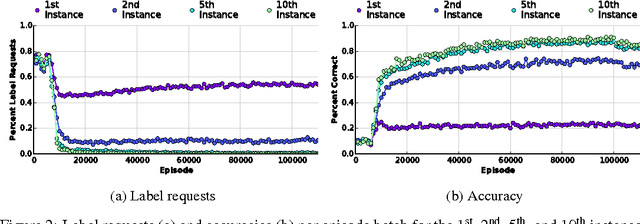
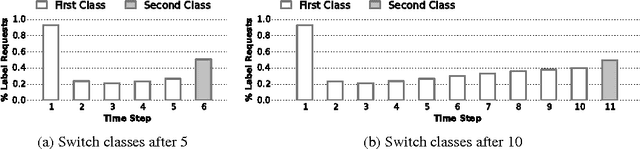
Recent advances in one-shot learning have produced models that can learn from a handful of labeled examples, for passive classification and regression tasks. This paper combines reinforcement learning with one-shot learning, allowing the model to decide, during classification, which examples are worth labeling. We introduce a classification task in which a stream of images are presented and, on each time step, a decision must be made to either predict a label or pay to receive the correct label. We present a recurrent neural network based action-value function, and demonstrate its ability to learn how and when to request labels. Through the choice of reward function, the model can achieve a higher prediction accuracy than a similar model on a purely supervised task, or trade prediction accuracy for fewer label requests.