 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarlon Nuske
Impact Assessment of Missing Data in Model Predictions for Earth Observation Applications
Mar 21, 2024

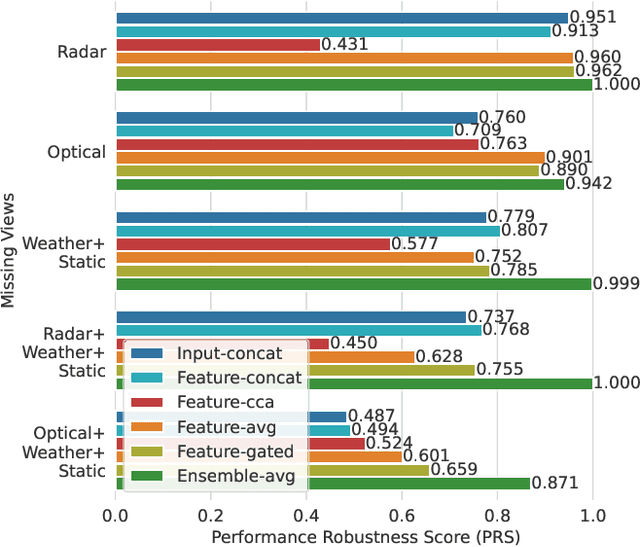

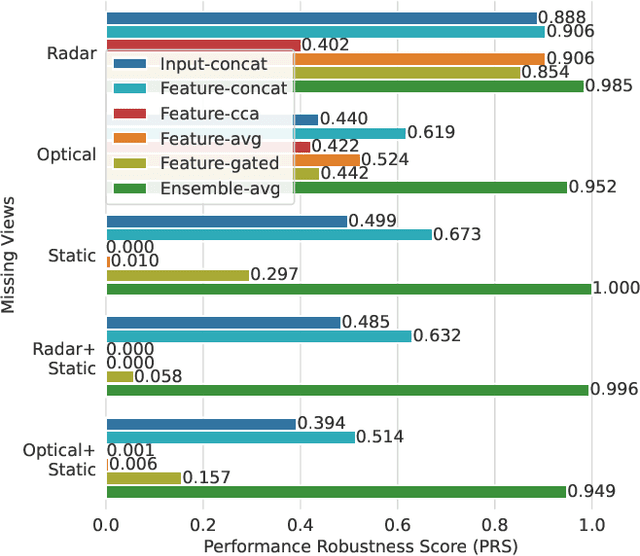
Earth observation (EO) applications involving complex and heterogeneous data sources are commonly approached with machine learning models. However, there is a common assumption that data sources will be persistently available. Different situations could affect the availability of EO sources, like noise, clouds, or satellite mission failures. In this work, we assess the impact of missing temporal and static EO sources in trained models across four datasets with classification and regression tasks. We compare the predictive quality of different methods and find that some are naturally more robust to missing data. The Ensemble strategy, in particular, achieves a prediction robustness up to 100%. We evidence that missing scenarios are significantly more challenging in regression than classification tasks. Finally, we find that the optical view is the most critical view when it is missing individually.
Adaptive Fusion of Multi-view Remote Sensing data for Optimal Sub-field Crop Yield Prediction
Jan 22, 2024Accurate crop yield prediction is of utmost importance for informed decision-making in agriculture, aiding farmers, and industry stakeholders. However, this task is complex and depends on multiple factors, such as environmental conditions, soil properties, and management practices. Combining heterogeneous data views poses a fusion challenge, like identifying the view-specific contribution to the predictive task. We present a novel multi-view learning approach to predict crop yield for different crops (soybean, wheat, rapeseed) and regions (Argentina, Uruguay, and Germany). Our multi-view input data includes multi-spectral optical images from Sentinel-2 satellites and weather data as dynamic features during the crop growing season, complemented by static features like soil properties and topographic information. To effectively fuse the data, we introduce a Multi-view Gated Fusion (MVGF) model, comprising dedicated view-encoders and a Gated Unit (GU) module. The view-encoders handle the heterogeneity of data sources with varying temporal resolutions by learning a view-specific representation. These representations are adaptively fused via a weighted sum. The fusion weights are computed for each sample by the GU using a concatenation of the view-representations. The MVGF model is trained at sub-field level with 10 m resolution pixels. Our evaluations show that the MVGF outperforms conventional models on the same task, achieving the best results by incorporating all the data sources, unlike the usual fusion results in the literature. For Argentina, the MVGF model achieves an R2 value of 0.68 at sub-field yield prediction, while at field level evaluation (comparing field averages), it reaches around 0.80 across different countries. The GU module learned different weights based on the country and crop-type, aligning with the variable significance of each data source to the prediction task.
Q-Seg: Quantum Annealing-based Unsupervised Image Segmentation
Nov 30, 2023



In this study, we present Q-Seg, a novel unsupervised image segmentation method based on quantum annealing, tailored for existing quantum hardware. We formulate the pixel-wise segmentation problem, which assimilates spectral and spatial information of the image, as a graph-cut optimization task. Our method efficiently leverages the interconnected qubit topology of the D-Wave Advantage device, offering superior scalability over existing quantum approaches and outperforming state-of-the-art classical methods. Our empirical evaluations on synthetic datasets reveal that Q-Seg offers better runtime performance against the classical optimizer Gurobi. Furthermore, we evaluate our method on segmentation of Earth Observation images, an area of application where the amount of labeled data is usually very limited. In this case, Q-Seg demonstrates near-optimal results in flood mapping detection with respect to classical supervised state-of-the-art machine learning methods. Also, Q-Seg provides enhanced segmentation for forest coverage compared to existing annotated masks. Thus, Q-Seg emerges as a viable alternative for real-world applications using available quantum hardware, particularly in scenarios where the lack of labeled data and computational runtime are critical.
Predicting Crop Yield With Machine Learning: An Extensive Analysis Of Input Modalities And Models On a Field and sub-field Level
Aug 17, 2023



We introduce a simple yet effective early fusion method for crop yield prediction that handles multiple input modalities with different temporal and spatial resolutions. We use high-resolution crop yield maps as ground truth data to train crop and machine learning model agnostic methods at the sub-field level. We use Sentinel-2 satellite imagery as the primary modality for input data with other complementary modalities, including weather, soil, and DEM data. The proposed method uses input modalities available with global coverage, making the framework globally scalable. We explicitly highlight the importance of input modalities for crop yield prediction and emphasize that the best-performing combination of input modalities depends on region, crop, and chosen model.
A Comparative Assessment of Multi-view fusion learning for Crop Classification
Aug 10, 2023



With a rapidly increasing amount and diversity of remote sensing (RS) data sources, there is a strong need for multi-view learning modeling. This is a complex task when considering the differences in resolution, magnitude, and noise of RS data. The typical approach for merging multiple RS sources has been input-level fusion, but other - more advanced - fusion strategies may outperform this traditional approach. This work assesses different fusion strategies for crop classification in the CropHarvest dataset. The fusion methods proposed in this work outperform models based on individual views and previous fusion methods. We do not find one single fusion method that consistently outperforms all other approaches. Instead, we present a comparison of multi-view fusion methods for three different datasets and show that, depending on the test region, different methods obtain the best performance. Despite this, we suggest a preliminary criterion for the selection of fusion methods.
On the Importance of Feature Representation for Flood Mapping using Classical Machine Learning Approaches
Mar 01, 2023



Climate change has increased the severity and frequency of weather disasters all around the world. Flood inundation mapping based on earth observation data can help in this context, by providing cheap and accurate maps depicting the area affected by a flood event to emergency-relief units in near-real-time. Building upon the recent development of the Sen1Floods11 dataset, which provides a limited amount of hand-labeled high-quality training data, this paper evaluates the potential of five traditional machine learning approaches such as gradient boosted decision trees, support vector machines or quadratic discriminant analysis. By performing a grid-search-based hyperparameter optimization on 23 feature spaces we can show that all considered classifiers are capable of outperforming the current state-of-the-art neural network-based approaches in terms of total IoU on their best-performing feature spaces. With total and mean IoU values of 0.8751 and 0.7031 compared to 0.70 and 0.5873 as the previous best-reported results, we show that a simple gradient boosting classifier can significantly improve over deep neural network based approaches, despite using less training data. Furthermore, an analysis of the regional distribution of the Sen1Floods11 dataset reveals a problem of spatial imbalance. We show that traditional machine learning models can learn this bias and argue that modified metric evaluations are required to counter artifacts due to spatial imbalance. Lastly, a qualitative analysis shows that this pixel-wise classifier provides highly-precise surface water classifications indicating that a good choice of a feature space and pixel-wise classification can generate high-quality flood maps using optical and SAR data. We make our code publicly available at: https://github.com/DFKI-Earth-And-Space-Applications/Flood_Mapping_Feature_Space_Importance
Common Practices and Taxonomy in Deep Multi-view Fusion for Remote Sensing Applications
Dec 20, 2022



The advances in remote sensing technologies have boosted applications for Earth observation. These technologies provide multiple observations or views with different levels of information. They might contain static or temporary views with different levels of resolution, in addition to having different types and amounts of noise due to sensor calibration or deterioration. A great variety of deep learning models have been applied to fuse the information from these multiple views, known as deep multi-view or multi-modal fusion learning. However, the approaches in the literature vary greatly since different terminology is used to refer to similar concepts or different illustrations are given to similar techniques. This article gathers works on multi-view fusion for Earth observation by focusing on the common practices and approaches used in the literature. We summarize and structure insights from several different publications concentrating on unifying points and ideas. In this manuscript, we provide a harmonized terminology while at the same time mentioning the various alternative terms that are used in literature. The topics covered by the works reviewed focus on supervised learning with the use of neural network models. We hope this review, with a long list of recent references, can support future research and lead to a unified advance in the area.