 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarlou Rasenberg
Leveraging Speech for Gesture Detection in Multimodal Communication
Apr 23, 2024
Gestures are inherent to human interaction and often complement speech in face-to-face communication, forming a multimodal communication system. An important task in gesture analysis is detecting a gesture's beginning and end. Research on automatic gesture detection has primarily focused on visual and kinematic information to detect a limited set of isolated or silent gestures with low variability, neglecting the integration of speech and vision signals to detect gestures that co-occur with speech. This work addresses this gap by focusing on co-speech gesture detection, emphasising the synchrony between speech and co-speech hand gestures. We address three main challenges: the variability of gesture forms, the temporal misalignment between gesture and speech onsets, and differences in sampling rate between modalities. We investigate extended speech time windows and employ separate backbone models for each modality to address the temporal misalignment and sampling rate differences. We utilize Transformer encoders in cross-modal and early fusion techniques to effectively align and integrate speech and skeletal sequences. The study results show that combining visual and speech information significantly enhances gesture detection performance. Our findings indicate that expanding the speech buffer beyond visual time segments improves performance and that multimodal integration using cross-modal and early fusion techniques outperforms baseline methods using unimodal and late fusion methods. Additionally, we find a correlation between the models' gesture prediction confidence and low-level speech frequency features potentially associated with gestures. Overall, the study provides a better understanding and detection methods for co-speech gestures, facilitating the analysis of multimodal communication.
Co-Speech Gesture Detection through Multi-phase Sequence Labeling
Aug 21, 2023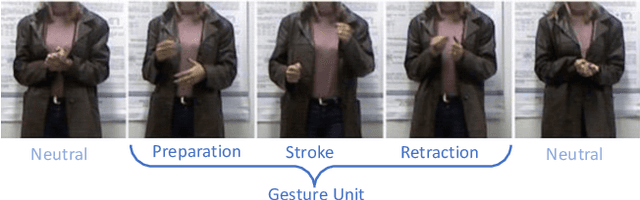
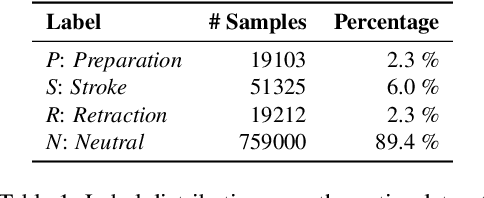

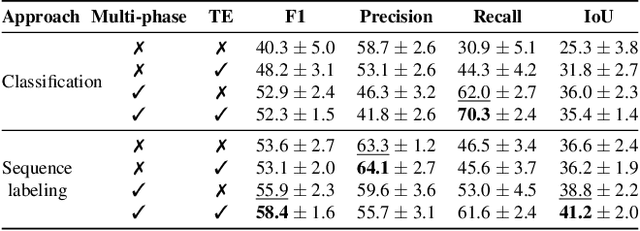
Gestures are integral components of face-to-face communication. They unfold over time, often following predictable movement phases of preparation, stroke, and retraction. Yet, the prevalent approach to automatic gesture detection treats the problem as binary classification, classifying a segment as either containing a gesture or not, thus failing to capture its inherently sequential and contextual nature. To address this, we introduce a novel framework that reframes the task as a multi-phase sequence labeling problem rather than binary classification. Our model processes sequences of skeletal movements over time windows, uses Transformer encoders to learn contextual embeddings, and leverages Conditional Random Fields to perform sequence labeling. We evaluate our proposal on a large dataset of diverse co-speech gestures in task-oriented face-to-face dialogues. The results consistently demonstrate that our method significantly outperforms strong baseline models in detecting gesture strokes. Furthermore, applying Transformer encoders to learn contextual embeddings from movement sequences substantially improves gesture unit detection. These results highlight our framework's capacity to capture the fine-grained dynamics of co-speech gesture phases, paving the way for more nuanced and accurate gesture detection and analysis.