 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasato Hagiwara
Project MOSLA: Recording Every Moment of Second Language Acquisition
Mar 26, 2024
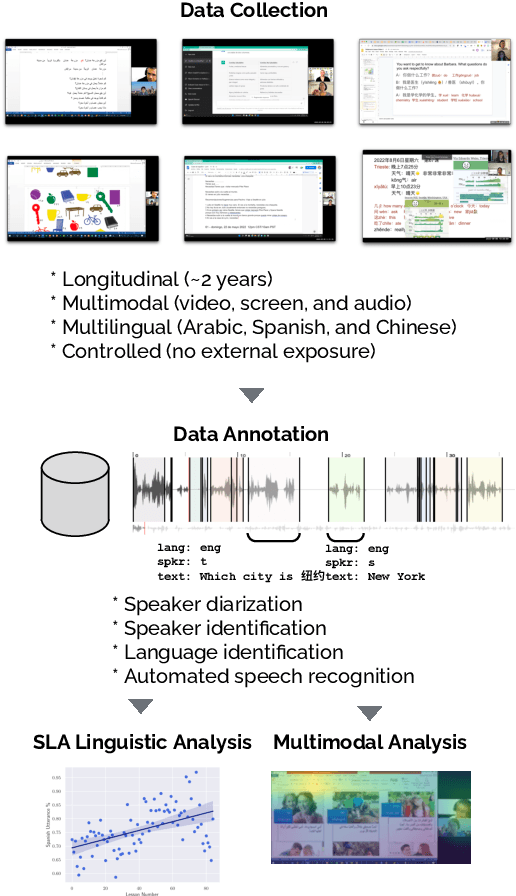
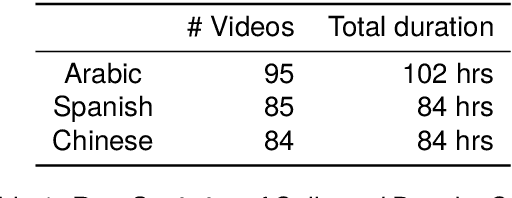
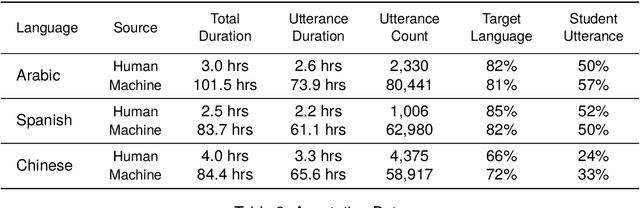
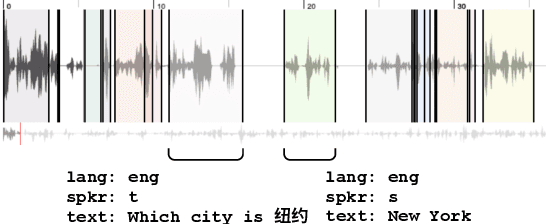
Second language acquisition (SLA) is a complex and dynamic process. Many SLA studies that have attempted to record and analyze this process have typically focused on a single modality (e.g., textual output of learners), covered only a short period of time, and/or lacked control (e.g., failed to capture every aspect of the learning process). In Project MOSLA (Moments of Second Language Acquisition), we have created a longitudinal, multimodal, multilingual, and controlled dataset by inviting participants to learn one of three target languages (Arabic, Spanish, and Chinese) from scratch over a span of two years, exclusively through online instruction, and recording every lesson using Zoom. The dataset is semi-automatically annotated with speaker/language IDs and transcripts by both human annotators and fine-tuned state-of-the-art speech models. Our experiments reveal linguistic insights into learners' proficiency development over time, as well as the potential for automatically detecting the areas of focus on the screen purely from the unannotated multimodal data. Our dataset is freely available for research purposes and can serve as a valuable resource for a wide range of applications, including but not limited to SLA, proficiency assessment, language and speech processing, pedagogy, and multimodal learning analytics.
ISPA: Inter-Species Phonetic Alphabet for Transcribing Animal Sounds
Feb 05, 2024Traditionally, bioacoustics has relied on spectrograms and continuous, per-frame audio representations for the analysis of animal sounds, also serving as input to machine learning models. Meanwhile, the International Phonetic Alphabet (IPA) system has provided an interpretable, language-independent method for transcribing human speech sounds. In this paper, we introduce ISPA (Inter-Species Phonetic Alphabet), a precise, concise, and interpretable system designed for transcribing animal sounds into text. We compare acoustics-based and feature-based methods for transcribing and classifying animal sounds, demonstrating their comparable performance with baseline methods utilizing continuous, dense audio representations. By representing animal sounds with text, we effectively treat them as a "foreign language," and we show that established human language ML paradigms and models, such as language models, can be successfully applied to improve performance.
AVES: Animal Vocalization Encoder based on Self-Supervision
Oct 26, 2022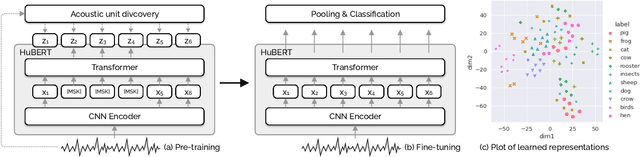

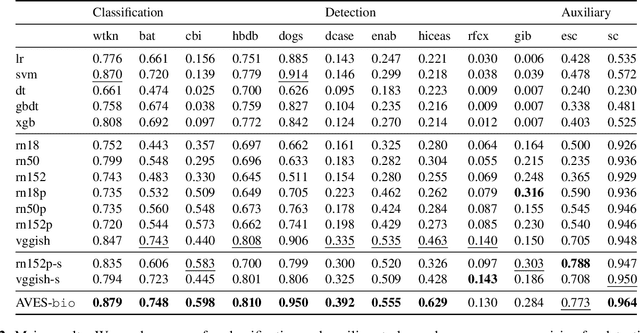

The lack of annotated training data in bioacoustics hinders the use of large-scale neural network models trained in a supervised way. In order to leverage a large amount of unannotated audio data, we propose AVES (Animal Vocalization Encoder based on Self-Supervision), a self-supervised, transformer-based audio representation model for encoding animal vocalizations. We pretrain AVES on a diverse set of unannotated audio datasets and fine-tune them for downstream bioacoustics tasks. Comprehensive experiments with a suite of classification and detection tasks have shown that AVES outperforms all the strong baselines and even the supervised "topline" models trained on annotated audio classification datasets. The results also suggest that curating a small training subset related to downstream tasks is an efficient way to train high-quality audio representation models. We open-source our models at \url{https://github.com/earthspecies/aves}.
Modeling Animal Vocalizations through Synthesizers
Oct 19, 2022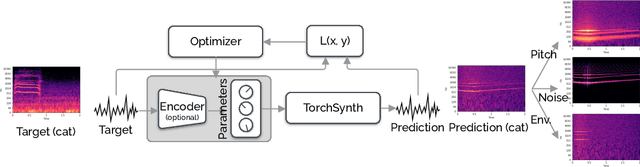
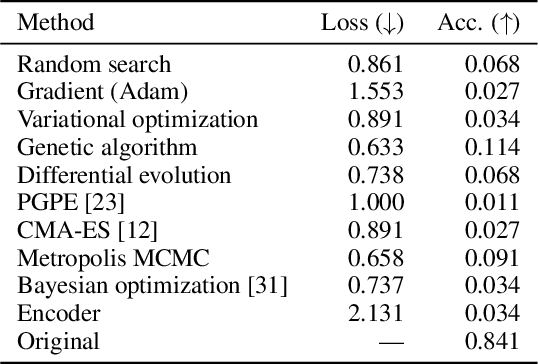
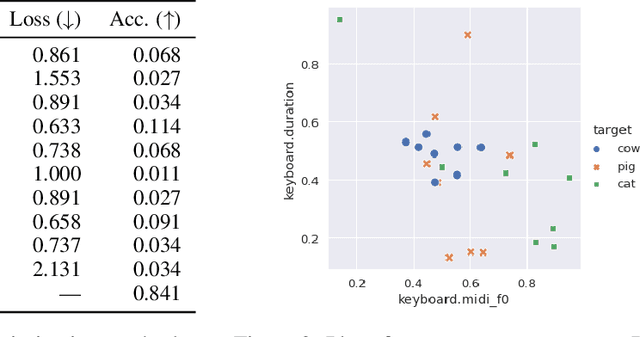
Modeling real-world sound is a fundamental problem in the creative use of machine learning and many other fields, including human speech processing and bioacoustics. Transformer-based generative models and some prior work (e.g., DDSP) are known to produce realistic sound, although they have limited control and are hard to interpret. As an alternative, we aim to use modular synthesizers, i.e., compositional, parametric electronic musical instruments, for modeling non-music sounds. However, inferring synthesizer parameters given a target sound, i.e., the parameter inference task, is not trivial for general sounds, and past research has typically focused on musical sound. In this work, we optimize a differentiable synthesizer from TorchSynth in order to model, emulate, and creatively generate animal vocalizations. We compare an array of optimization methods, from gradient-based search to genetic algorithms, for inferring its parameters, and then demonstrate how one can control and interpret the parameters for modeling non-music sounds.
Towards Automated Document Revision: Grammatical Error Correction, Fluency Edits, and Beyond
May 23, 2022


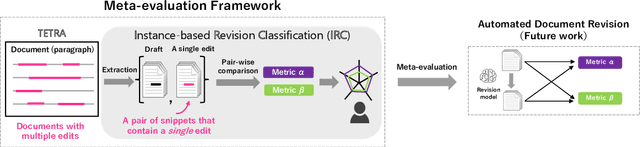
Natural language processing technology has rapidly improved automated grammatical error correction tasks, and the community begins to explore document-level revision as one of the next challenges. To go beyond sentence-level automated grammatical error correction to NLP-based document-level revision assistant, there are two major obstacles: (1) there are few public corpora with document-level revisions being annotated by professional editors, and (2) it is not feasible to elicit all possible references and evaluate the quality of revision with such references because there are infinite possibilities of revision. This paper tackles these challenges. First, we introduce a new document-revision corpus, TETRA, where professional editors revised academic papers sampled from the ACL anthology which contain few trivial grammatical errors that enable us to focus more on document- and paragraph-level edits such as coherence and consistency. Second, we explore reference-less and interpretable methods for meta-evaluation that can detect quality improvements by document revision. We show the uniqueness of TETRA compared with existing document revision corpora and demonstrate that a fine-tuned pre-trained language model can discriminate the quality of documents after revision even when the difference is subtle. This promising result will encourage the community to further explore automated document revision models and metrics in future.
Semi-Supervised Joint Estimation of Word and Document Readability
Apr 27, 2021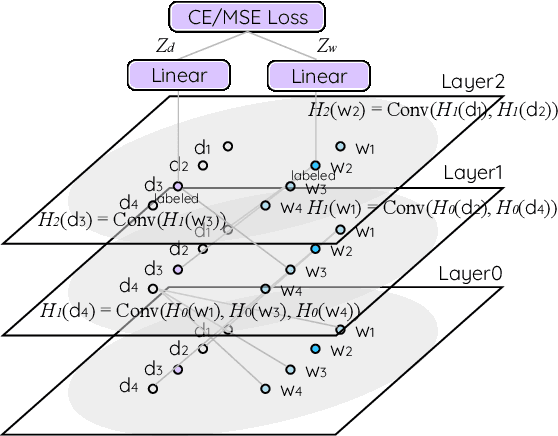
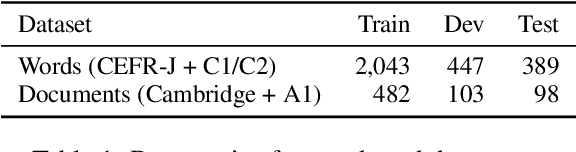

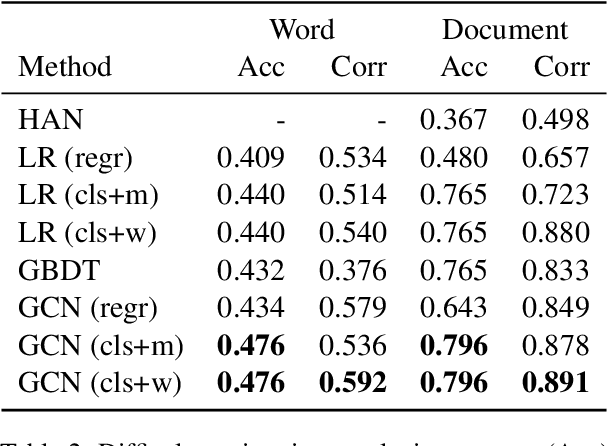
Readability or difficulty estimation of words and documents has been investigated independently in the literature, often assuming the existence of extensive annotated resources for the other. Motivated by our analysis showing that there is a recursive relationship between word and document difficulty, we propose to jointly estimate word and document difficulty through a graph convolutional network (GCN) in a semi-supervised fashion. Our experimental results reveal that the GCN-based method can achieve higher accuracy than strong baselines, and stays robust even with a smaller amount of labeled data.
EXPATS: A Toolkit for Explainable Automated Text Scoring
Apr 07, 2021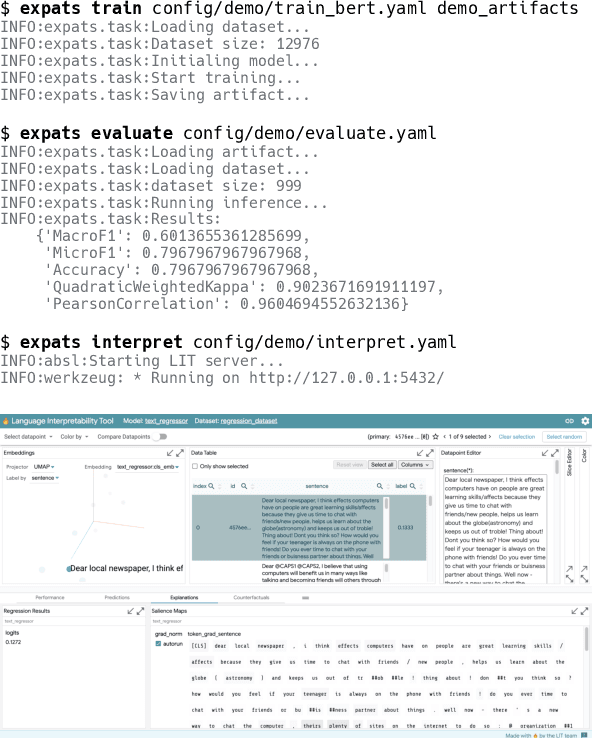

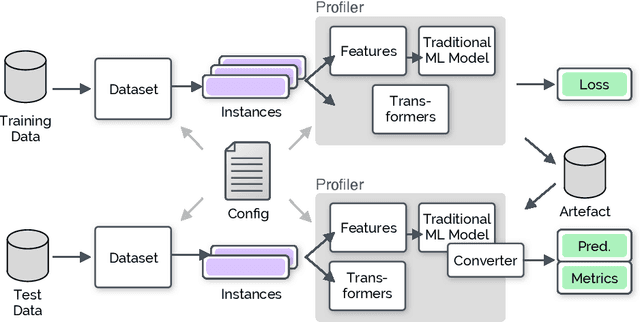
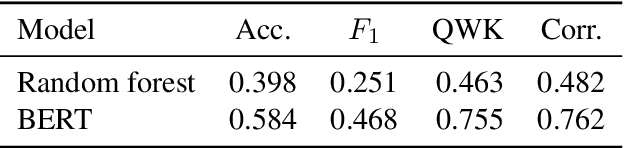
Automated text scoring (ATS) tasks, such as automated essay scoring and readability assessment, are important educational applications of natural language processing. Due to their interpretability of models and predictions, traditional machine learning (ML) algorithms based on handcrafted features are still in wide use for ATS tasks. Practitioners often need to experiment with a variety of models (including deep and traditional ML ones), features, and training objectives (regression and classification), although modern deep learning frameworks such as PyTorch require deep ML expertise to fully utilize. In this paper, we present EXPATS, an open-source framework to allow its users to develop and experiment with different ATS models quickly by offering flexible components, an easy-to-use configuration system, and the command-line interface. The toolkit also provides seamless integration with the Language Interpretability Tool (LIT) so that one can interpret and visualize models and their predictions. We also describe two case studies where we build ATS models quickly with minimal engineering efforts. The toolkit is available at \url{https://github.com/octanove/expats}.
GrammarTagger: A Multilingual, Minimally-Supervised Grammar Profiler for Language Education
Apr 07, 2021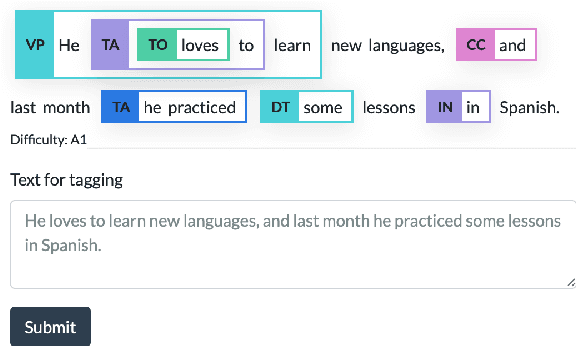


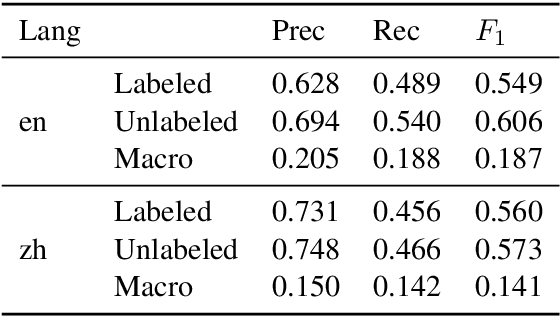
We present GrammarTagger, an open-source grammar profiler which, given an input text, identifies grammatical features useful for language education. The model architecture enables it to learn from a small amount of texts annotated with spans and their labels, which 1) enables easier and more intuitive annotation, 2) supports overlapping spans, and 3) is less prone to error propagation, compared to complex hand-crafted rules defined on constituency/dependency parses. We show that we can bootstrap a grammar profiler model with $F_1 \approx 0.6$ from only a couple hundred sentences both in English and Chinese, which can be further boosted via learning a multilingual model. With GrammarTagger, we also build Octanove Learn, a search engine of language learning materials indexed by their reading difficulty and grammatical features. The code and pretrained models are publicly available at \url{https://github.com/octanove/grammartagger}.
GitHub Typo Corpus: A Large-Scale Multilingual Dataset of Misspellings and Grammatical Errors
Nov 28, 2019


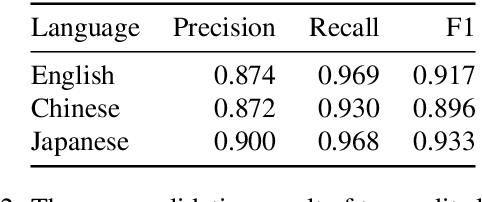
The lack of large-scale datasets has been a major hindrance to the development of NLP tasks such as spelling correction and grammatical error correction (GEC). As a complementary new resource for these tasks, we present the GitHub Typo Corpus, a large-scale, multilingual dataset of misspellings and grammatical errors along with their corrections harvested from GitHub, a large and popular platform for hosting and sharing git repositories. The dataset, which we have made publicly available, contains more than 350k edits and 65M characters in more than 15 languages, making it the largest dataset of misspellings to date. We also describe our process for filtering true typo edits based on learned classifiers on a small annotated subset, and demonstrate that typo edits can be identified with F1 ~ 0.9 using a very simple classifier with only three features. The detailed analyses of the dataset show that existing spelling correctors merely achieve an F-measure of approx. 0.5, suggesting that the dataset serves as a new, rich source of spelling errors that complement existing datasets.
Diamonds in the Rough: Generating Fluent Sentences from Early-Stage Drafts for Academic Writing Assistance
Oct 21, 2019



The writing process consists of several stages such as drafting, revising, editing, and proofreading. Studies on writing assistance, such as grammatical error correction (GEC), have mainly focused on sentence editing and proofreading, where surface-level issues such as typographical, spelling, or grammatical errors should be corrected. We broaden this focus to include the earlier revising stage, where sentences require adjustment to the information included or major rewriting and propose Sentence-level Revision (SentRev) as a new writing assistance task. Well-performing systems in this task can help inexperienced authors by producing fluent, complete sentences given their rough, incomplete drafts. We build a new freely available crowdsourced evaluation dataset consisting of incomplete sentences authored by non-native writers paired with their final versions extracted from published academic papers for developing and evaluating SentRev models. We also establish baseline performance on SentRev using our newly built evaluation dataset.