 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMateja Jamnik
Sphere Neural-Networks for Rational Reasoning
Mar 22, 2024
The success of Large Language Models (LLMs), e.g., ChatGPT, is witnessed by their planetary popularity, their capability of human-like question-answering, and also by their steadily improved reasoning performance. However, it remains unclear whether LLMs reason. It is an open problem how traditional neural networks can be qualitatively extended to go beyond the statistic paradigm and achieve high-level cognition. Here, we present a minimalist qualitative extension by generalising computational building blocks from vectors to spheres. We propose Sphere Neural Networks (SphNNs) for human-like reasoning through model construction and inspection, and develop SphNN for syllogistic reasoning, a microcosm of human rationality. Instead of training data, SphNN uses a neuro-symbolic transition map of neighbourhood spatial relations to guide transformations from the current sphere configuration towards the target. SphNN is the first neural model that can determine the validity of long-chained syllogistic reasoning in one epoch by constructing sphere configurations as Euler diagrams, with the worst computational complexity of O(N^2). SphNN can evolve into various types of reasoning, such as spatio-temporal reasoning, logical reasoning with negation and disjunction, event reasoning, neuro-symbolic reasoning, and humour understanding (the highest level of cognition). All these suggest a new kind of Herbert A. Simon's scissors with two neural blades. SphNNs will tremendously enhance interdisciplinary collaborations to develop the two neural blades and realise deterministic neural reasoning and human-bounded rationality and elevate LLMs to reliable psychological AI. This work suggests that the non-zero radii of spheres are the missing components that prevent traditional deep-learning systems from reaching the realm of rational reasoning and cause LLMs to be trapped in the swamp of hallucination.
Do Concept Bottleneck Models Obey Locality?
Jan 02, 2024Concept-based learning improves a deep learning model's interpretability by explaining its predictions via human-understandable concepts. Deep learning models trained under this paradigm heavily rely on the assumption that neural networks can learn to predict the presence or absence of a given concept independently of other concepts. Recent work, however, strongly suggests that this assumption may fail to hold in Concept Bottleneck Models (CBMs), a quintessential family of concept-based interpretable architectures. In this paper, we investigate whether CBMs correctly capture the degree of conditional independence across concepts when such concepts are localised both spatially, by having their values entirely defined by a fixed subset of features, and semantically, by having their values correlated with only a fixed subset of predefined concepts. To understand locality, we analyse how changes to features outside of a concept's spatial or semantic locality impact concept predictions. Our results suggest that even in well-defined scenarios where the presence of a concept is localised to a fixed feature subspace, or whose semantics are correlated to a small subset of other concepts, CBMs fail to learn this locality. These results cast doubt upon the quality of concept representations learnt by CBMs and strongly suggest that concept-based explanations may be fragile to changes outside their localities.
HEALNet -- Hybrid Multi-Modal Fusion for Heterogeneous Biomedical Data
Nov 20, 2023Technological advances in medical data collection such as high-resolution histopathology and high-throughput genomic sequencing have contributed to the rising requirement for multi-modal biomedical modelling, specifically for image, tabular, and graph data. Most multi-modal deep learning approaches use modality-specific architectures that are trained separately and cannot capture the crucial cross-modal information that motivates the integration of different data sources. This paper presents the Hybrid Early-fusion Attention Learning Network (HEALNet): a flexible multi-modal fusion architecture, which a) preserves modality-specific structural information, b) captures the cross-modal interactions and structural information in a shared latent space, c) can effectively handle missing modalities during training and inference, and d) enables intuitive model inspection by learning on the raw data input instead of opaque embeddings. We conduct multi-modal survival analysis on Whole Slide Images and Multi-omic data on four cancer cohorts of The Cancer Genome Atlas (TCGA). HEALNet achieves state-of-the-art performance, substantially improving over both uni-modal and recent multi-modal baselines, whilst being robust in scenarios with missing modalities.
Multilingual Mathematical Autoformalization
Nov 09, 2023Autoformalization is the task of translating natural language materials into machine-verifiable formalisations. Progress in autoformalization research is hindered by the lack of a sizeable dataset consisting of informal-formal pairs expressing the same essence. Existing methods tend to circumvent this challenge by manually curating small corpora or using few-shot learning with large language models. But these methods suffer from data scarcity and formal language acquisition difficulty. In this work, we create $\texttt{MMA}$, a large, flexible, multilingual, and multi-domain dataset of informal-formal pairs, by using a language model to translate in the reverse direction, that is, from formal mathematical statements into corresponding informal ones. Experiments show that language models fine-tuned on $\texttt{MMA}$ produce $16-18\%$ of statements acceptable with minimal corrections on the $\texttt{miniF2F}$ and $\texttt{ProofNet}$ benchmarks, up from $0\%$ with the base model. We demonstrate that fine-tuning on multilingual formal data results in more capable autoformalization models even when deployed on monolingual tasks.
Learning to Receive Help: Intervention-Aware Concept Embedding Models
Sep 29, 2023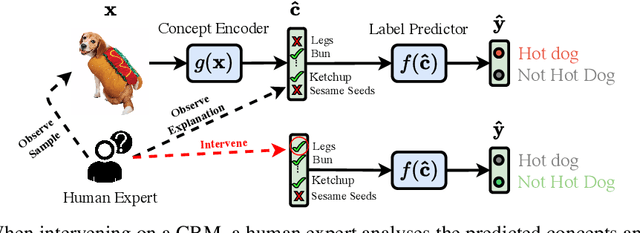
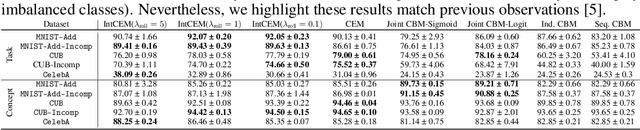
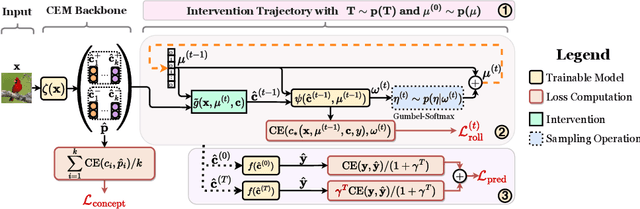
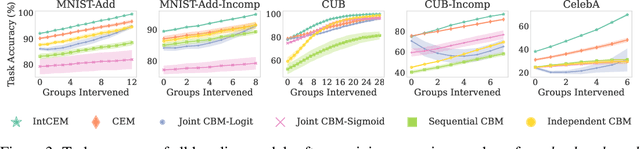
Concept Bottleneck Models (CBMs) tackle the opacity of neural architectures by constructing and explaining their predictions using a set of high-level concepts. A special property of these models is that they permit concept interventions, wherein users can correct mispredicted concepts and thus improve the model's performance. Recent work, however, has shown that intervention efficacy can be highly dependent on the order in which concepts are intervened on and on the model's architecture and training hyperparameters. We argue that this is rooted in a CBM's lack of train-time incentives for the model to be appropriately receptive to concept interventions. To address this, we propose Intervention-aware Concept Embedding models (IntCEMs), a novel CBM-based architecture and training paradigm that improves a model's receptiveness to test-time interventions. Our model learns a concept intervention policy in an end-to-end fashion from where it can sample meaningful intervention trajectories at train-time. This conditions IntCEMs to effectively select and receive concept interventions when deployed at test-time. Our experiments show that IntCEMs significantly outperform state-of-the-art concept-interpretable models when provided with test-time concept interventions, demonstrating the effectiveness of our approach.
Enhancing Representation Learning on High-Dimensional, Small-Size Tabular Data: A Divide and Conquer Method with Ensembled VAEs
Jun 27, 2023



Variational Autoencoders and their many variants have displayed impressive ability to perform dimensionality reduction, often achieving state-of-the-art performance. Many current methods however, struggle to learn good representations in High Dimensional, Low Sample Size (HDLSS) tasks, which is an inherently challenging setting. We address this challenge by using an ensemble of lightweight VAEs to learn posteriors over subsets of the feature-space, which get aggregated into a joint posterior in a novel divide-and-conquer approach. Specifically, we present an alternative factorisation of the joint posterior that induces a form of implicit data augmentation that yields greater sample efficiency. Through a series of experiments on eight real-world datasets, we show that our method learns better latent representations in HDLSS settings, which leads to higher accuracy in a downstream classification task. Furthermore, we verify that our approach has a positive effect on disentanglement and achieves a lower estimated Total Correlation on learnt representations. Finally, we show that our approach is robust to partial features at inference, exhibiting little performance degradation even with most features missing.
ProtoGate: Prototype-based Neural Networks with Local Feature Selection for Tabular Biomedical Data
Jun 21, 2023



Tabular biomedical data poses challenges in machine learning because it is often high-dimensional and typically low-sample-size. Previous research has attempted to address these challenges via feature selection approaches, which can lead to unstable performance on real-world data. This suggests that current methods lack appropriate inductive biases that capture patterns common to different samples. In this paper, we propose ProtoGate, a prototype-based neural model that introduces an inductive bias by attending to both homogeneity and heterogeneity across samples. ProtoGate selects features in a global-to-local manner and leverages them to produce explainable predictions via an interpretable prototype-based model. We conduct comprehensive experiments to evaluate the performance of ProtoGate on synthetic and real-world datasets. Our results show that exploiting the homogeneous and heterogeneous patterns in the data can improve prediction accuracy while prototypes imbue interpretability.
Evaluating Language Models for Mathematics through Interactions
Jun 02, 2023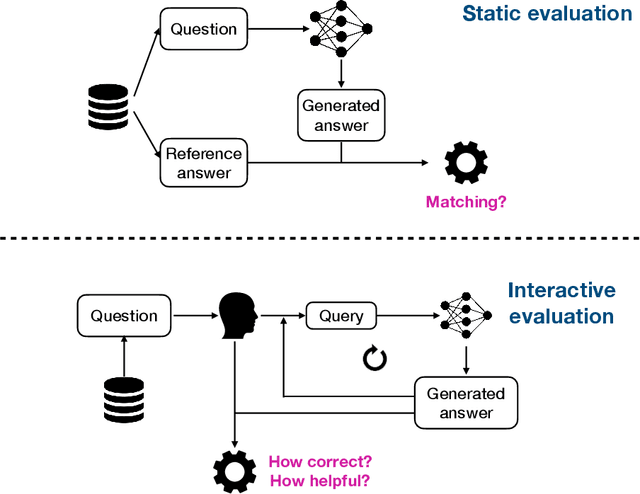
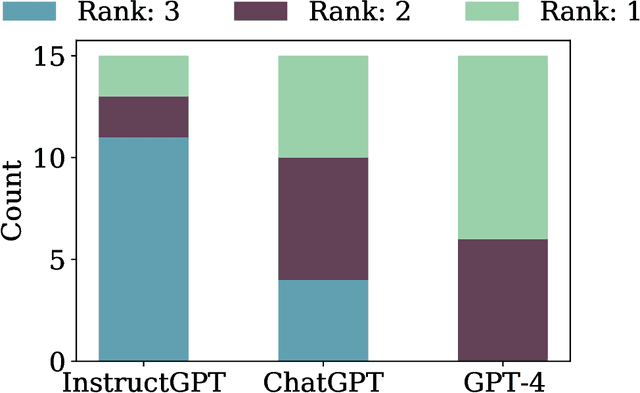
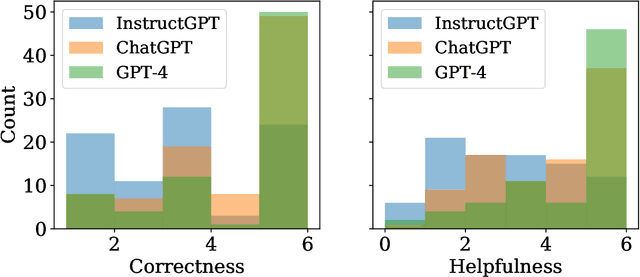
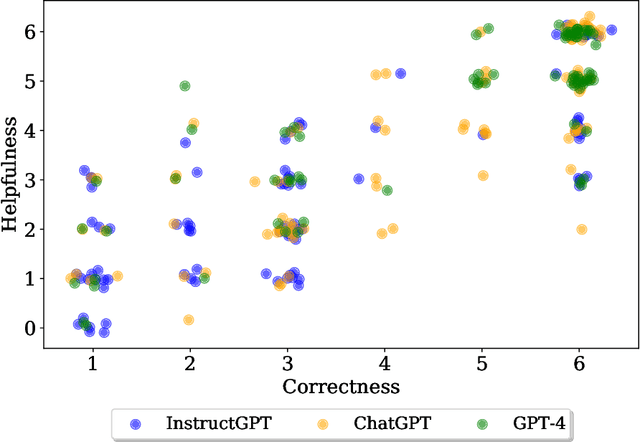
The standard methodology of evaluating large language models (LLMs) based on static pairs of inputs and outputs is insufficient for developing assistants: this kind of assessments fails to take into account the essential interactive element in their deployment, and therefore limits how we understand language model capabilities. We introduce CheckMate, an adaptable prototype platform for humans to interact with and evaluate LLMs. We conduct a study with CheckMate to evaluate three language models~(InstructGPT, ChatGPT, and GPT-4) as assistants in proving undergraduate-level mathematics, with a mixed cohort of participants from undergraduate students to professors of mathematics. We release the resulting interaction and rating dataset, MathConverse. By analysing MathConverse, we derive a preliminary taxonomy of human behaviours and uncover that despite a generally positive correlation, there are notable instances of divergence between correctness and perceived helpfulness in LLM generations, amongst other findings. Further, we identify useful scenarios and existing issues of GPT-4 in mathematical reasoning through a series of case studies contributed by expert mathematicians. We conclude with actionable takeaways for ML practitioners and mathematicians: models which communicate uncertainty, respond well to user corrections, are more interpretable and concise may constitute better assistants; interactive evaluation is a promising way to continually navigate the capability of these models; humans should be aware of language models' algebraic fallibility, and for that reason discern where they should be used.
Interpretable Neural-Symbolic Concept Reasoning
Apr 27, 2023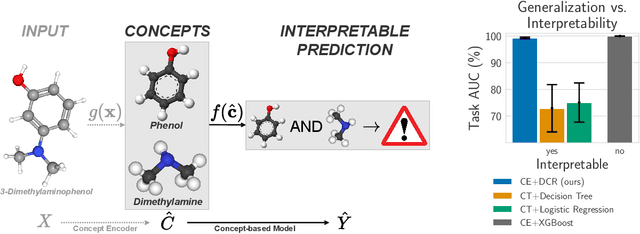
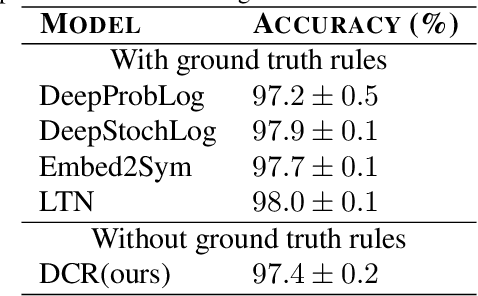

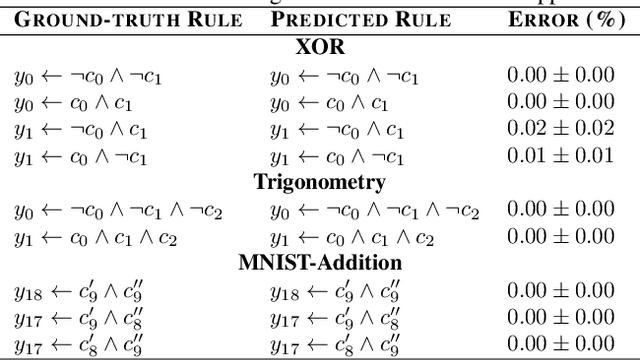
Deep learning methods are highly accurate, yet their opaque decision process prevents them from earning full human trust. Concept-based models aim to address this issue by learning tasks based on a set of human-understandable concepts. However, state-of-the-art concept-based models rely on high-dimensional concept embedding representations which lack a clear semantic meaning, thus questioning the interpretability of their decision process. To overcome this limitation, we propose the Deep Concept Reasoner (DCR), the first interpretable concept-based model that builds upon concept embeddings. In DCR, neural networks do not make task predictions directly, but they build syntactic rule structures using concept embeddings. DCR then executes these rules on meaningful concept truth degrees to provide a final interpretable and semantically-consistent prediction in a differentiable manner. Our experiments show that DCR: (i) improves up to +25% w.r.t. state-of-the-art interpretable concept-based models on challenging benchmarks (ii) discovers meaningful logic rules matching known ground truths even in the absence of concept supervision during training, and (iii), facilitates the generation of counterfactual examples providing the learnt rules as guidance.
CGXplain: Rule-Based Deep Neural Network Explanations Using Dual Linear Programs
Apr 11, 2023


Rule-based surrogate models are an effective and interpretable way to approximate a Deep Neural Network's (DNN) decision boundaries, allowing humans to easily understand deep learning models. Current state-of-the-art decompositional methods, which are those that consider the DNN's latent space to extract more exact rule sets, manage to derive rule sets at high accuracy. However, they a) do not guarantee that the surrogate model has learned from the same variables as the DNN (alignment), b) only allow to optimise for a single objective, such as accuracy, which can result in excessively large rule sets (complexity), and c) use decision tree algorithms as intermediate models, which can result in different explanations for the same DNN (stability). This paper introduces the CGX (Column Generation eXplainer) to address these limitations - a decompositional method using dual linear programming to extract rules from the hidden representations of the DNN. This approach allows to optimise for any number of objectives and empowers users to tweak the explanation model to their needs. We evaluate our results on a wide variety of tasks and show that CGX meets all three criteria, by having exact reproducibility of the explanation model that guarantees stability and reduces the rule set size by >80% (complexity) at equivalent or improved accuracy and fidelity across tasks (alignment).