 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatthew D. Zeiler
Stochastic Pooling for Regularization of Deep Convolutional Neural Networks
Jan 16, 2013
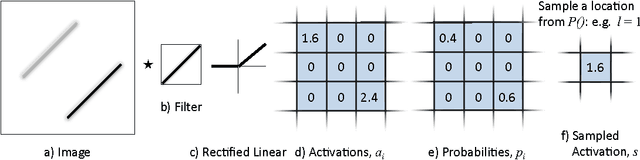



We introduce a simple and effective method for regularizing large convolutional neural networks. We replace the conventional deterministic pooling operations with a stochastic procedure, randomly picking the activation within each pooling region according to a multinomial distribution, given by the activities within the pooling region. The approach is hyper-parameter free and can be combined with other regularization approaches, such as dropout and data augmentation. We achieve state-of-the-art performance on four image datasets, relative to other approaches that do not utilize data augmentation.
ADADELTA: An Adaptive Learning Rate Method
Dec 22, 2012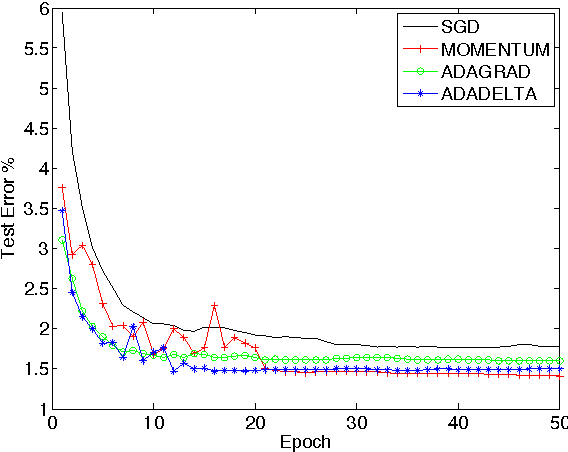
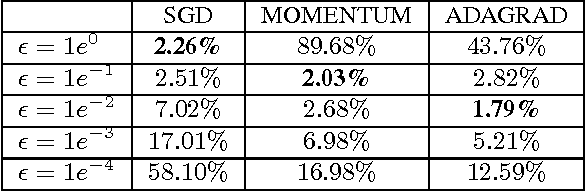
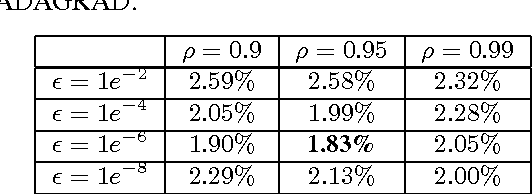
We present a novel per-dimension learning rate method for gradient descent called ADADELTA. The method dynamically adapts over time using only first order information and has minimal computational overhead beyond vanilla stochastic gradient descent. The method requires no manual tuning of a learning rate and appears robust to noisy gradient information, different model architecture choices, various data modalities and selection of hyperparameters. We show promising results compared to other methods on the MNIST digit classification task using a single machine and on a large scale voice dataset in a distributed cluster environment.
Differentiable Pooling for Hierarchical Feature Learning
Jun 30, 2012
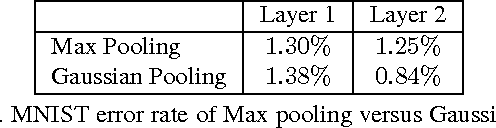

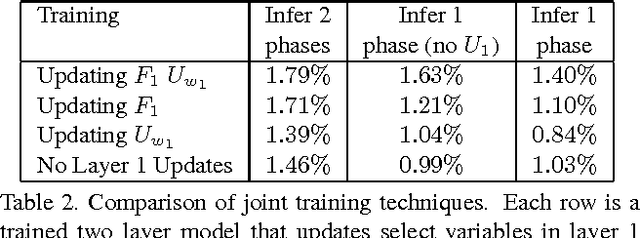
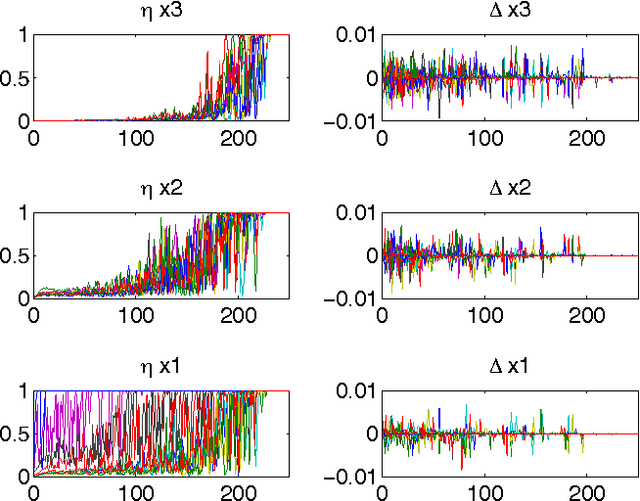
We introduce a parametric form of pooling, based on a Gaussian, which can be optimized alongside the features in a single global objective function. By contrast, existing pooling schemes are based on heuristics (e.g. local maximum) and have no clear link to the cost function of the model. Furthermore, the variables of the Gaussian explicitly store location information, distinct from the appearance captured by the features, thus providing a what/where decomposition of the input signal. Although the differentiable pooling scheme can be incorporated in a wide range of hierarchical models, we demonstrate it in the context of a Deconvolutional Network model (Zeiler et al. ICCV 2011). We also explore a number of secondary issues within this model and present detailed experiments on MNIST digits.