 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaurice Fallon
AutoInspect: Towards Long-Term Autonomous Industrial Inspection
Apr 19, 2024
We give an overview of AutoInspect, a ROS-based software system for robust and extensible mission-level autonomy. Over the past three years AutoInspect has been deployed in a variety of environments, including at a mine, a chemical plant, a mock oil rig, decommissioned nuclear power plants, and a fusion reactor for durations ranging from hours to weeks. The system combines robust mapping and localisation with graph-based autonomous navigation, mission execution, and scheduling to achieve a complete autonomous inspection system. The time from arrival at a new site to autonomous mission execution can be under an hour. It is deployed on a Boston Dynamics Spot robot using a custom sensing and compute payload called Frontier. In this work we go into detail of the system's performance in two long-term deployments of 49 days at a robotics test facility, and 35 days at the Joint European Torus (JET) fusion reactor in Oxfordshire, UK.
Wild Visual Navigation: Fast Traversability Learning via Pre-Trained Models and Online Self-Supervision
Apr 10, 2024Natural environments such as forests and grasslands are challenging for robotic navigation because of the false perception of rigid obstacles from high grass, twigs, or bushes. In this work, we present Wild Visual Navigation (WVN), an online self-supervised learning system for visual traversability estimation. The system is able to continuously adapt from a short human demonstration in the field, only using onboard sensing and computing. One of the key ideas to achieve this is the use of high-dimensional features from pre-trained self-supervised models, which implicitly encode semantic information that massively simplifies the learning task. Further, the development of an online scheme for supervision generator enables concurrent training and inference of the learned model in the wild. We demonstrate our approach through diverse real-world deployments in forests, parks, and grasslands. Our system is able to bootstrap the traversable terrain segmentation in less than 5 min of in-field training time, enabling the robot to navigate in complex, previously unseen outdoor terrains. Code: https://bit.ly/498b0CV - Project page:https://bit.ly/3M6nMHH
Online Tree Reconstruction and Forest Inventory on a Mobile Robotic System
Mar 26, 2024Terrestrial laser scanning (TLS) is the standard technique used to create accurate point clouds for digital forest inventories. However, the measurement process is demanding, requiring up to two days per hectare for data collection, significant data storage, as well as resource-heavy post-processing of 3D data. In this work, we present a real-time mapping and analysis system that enables online generation of forest inventories using mobile laser scanners that can be mounted e.g. on mobile robots. Given incrementally created and locally accurate submaps-data payloads-our approach extracts tree candidates using a custom, Voronoi-inspired clustering algorithm. Tree candidates are reconstructed using an adapted Hough algorithm, which enables robust modeling of the tree stem. Further, we explicitly incorporate the incremental nature of the data collection by consistently updating the database using a pose graph LiDAR SLAM system. This enables us to refine our estimates of the tree traits if an area is revisited later during a mission. We demonstrate competitive accuracy to TLS or manual measurements using laser scanners that we mounted on backpacks or mobile robots operating in conifer, broad-leaf and mixed forests. Our results achieve RMSE of 1.93 cm, a bias of 0.65 cm and a standard deviation of 1.81 cm (averaged across these sequences)-with no post-processing required after the mission is complete.
Evaluation and Deployment of LiDAR-based Place Recognition in Dense Forests
Mar 21, 2024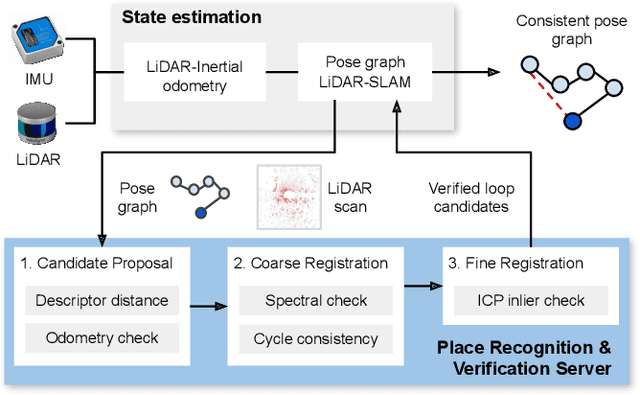
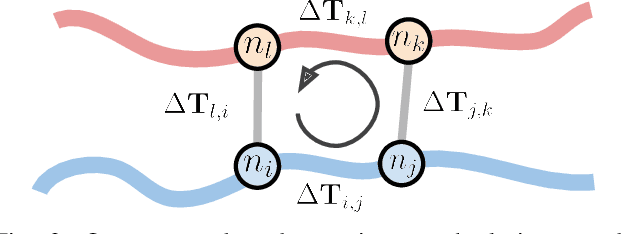
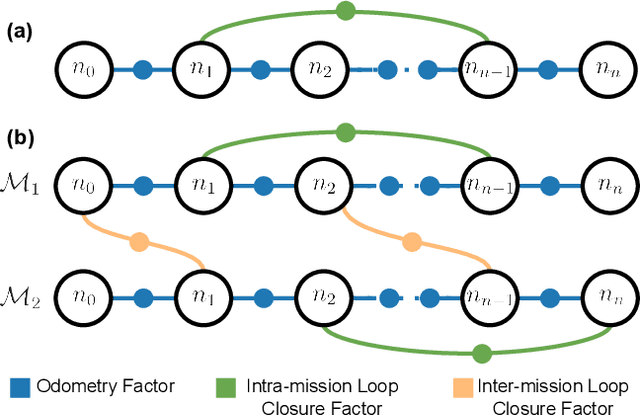
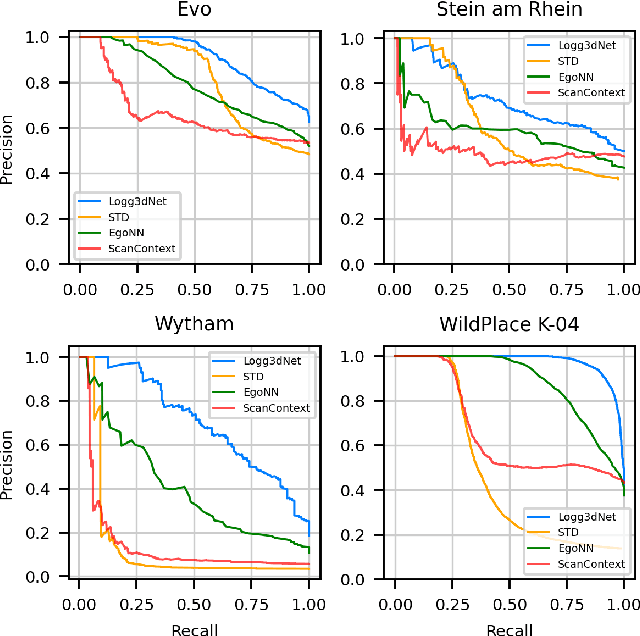
Many LiDAR place recognition systems have been developed and tested specifically for urban driving scenarios. Their performance in natural environments such as forests and woodlands have been studied less closely. In this paper, we analyzed the capabilities of four different LiDAR place recognition systems, both handcrafted and learning-based methods, using LiDAR data collected with a handheld device and legged robot within dense forest environments. In particular, we focused on evaluating localization where there is significant translational and orientation difference between corresponding LiDAR scan pairs. This is particularly important for forest survey systems where the sensor or robot does not follow a defined road or path. Extending our analysis we then incorporated the best performing approach, Logg3dNet, into a full 6-DoF pose estimation system -- introducing several verification layers for precise registration. We demonstrated the performance of our methods in three operational modes: online SLAM, offline multi-mission SLAM map merging, and relocalization into a prior map. We evaluated these modes using data captured in forests from three different countries, achieving 80% of correct loop closures candidates with baseline distances up to 5m, and 60% up to 10m.
Exosense: A Vision-Centric Scene Understanding System For Safe Exoskeleton Navigation
Mar 21, 2024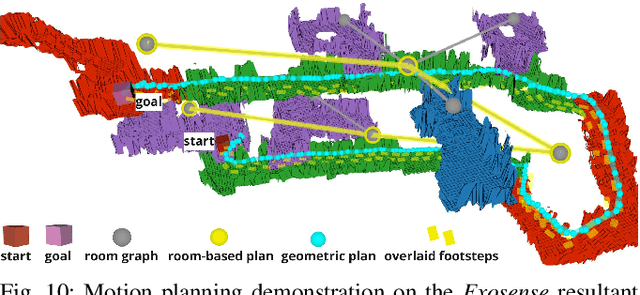

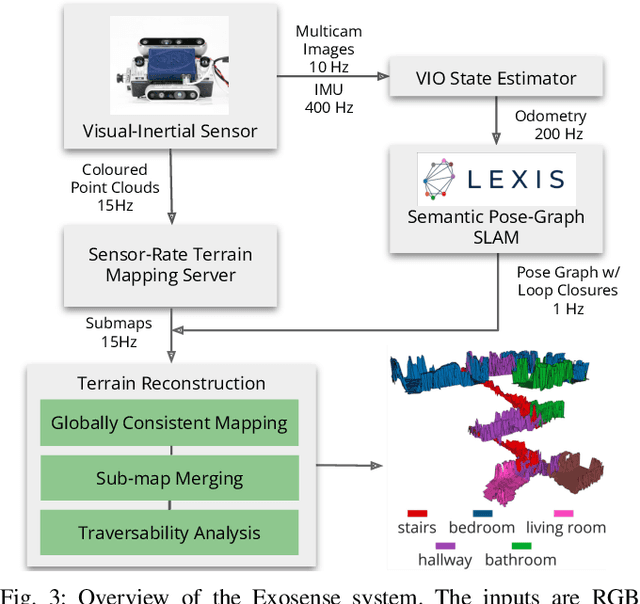
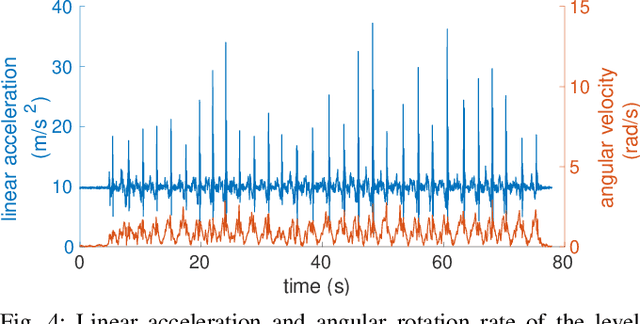
Exoskeletons for daily use by those with mobility impairments are being developed. They will require accurate and robust scene understanding systems. Current research has used vision to identify immediate terrain and geometric obstacles, however these approaches are constrained to detections directly in front of the user and are limited to classifying a finite range of terrain types (e.g., stairs, ramps and level-ground). This paper presents Exosense, a vision-centric scene understanding system which is capable of generating rich, globally-consistent elevation maps, incorporating both semantic and terrain traversability information. It features an elastic Atlas mapping framework associated with a visual SLAM pose graph, embedded with open-vocabulary room labels from a Vision-Language Model (VLM). The device's design includes a wide field-of-view (FoV) fisheye multi-camera system to mitigate the challenges introduced by the exoskeleton walking pattern. We demonstrate the system's robustness to the challenges of typical periodic walking gaits, and its ability to construct accurate semantically-rich maps in indoor settings. Additionally, we showcase its potential for motion planning -- providing a step towards safe navigation for exoskeletons.
SiLVR: Scalable Lidar-Visual Reconstruction with Neural Radiance Fields for Robotic Inspection
Mar 11, 2024
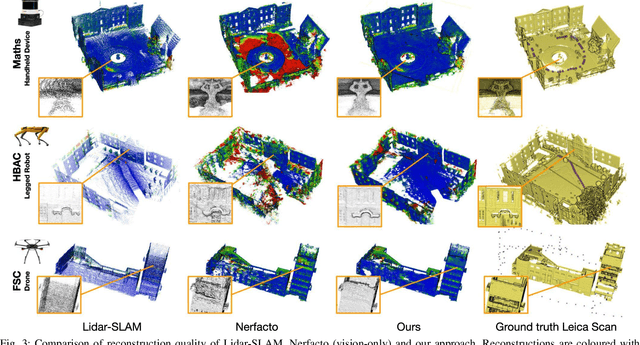


We present a neural-field-based large-scale reconstruction system that fuses lidar and vision data to generate high-quality reconstructions that are geometrically accurate and capture photo-realistic textures. This system adapts the state-of-the-art neural radiance field (NeRF) representation to also incorporate lidar data which adds strong geometric constraints on the depth and surface normals. We exploit the trajectory from a real-time lidar SLAM system to bootstrap a Structure-from-Motion (SfM) procedure to both significantly reduce the computation time and to provide metric scale which is crucial for lidar depth loss. We use submapping to scale the system to large-scale environments captured over long trajectories. We demonstrate the reconstruction system with data from a multi-camera, lidar sensor suite onboard a legged robot, hand-held while scanning building scenes for 600 metres, and onboard an aerial robot surveying a multi-storey mock disaster site-building. Website: https://ori-drs.github.io/projects/silvr/
LiSTA: Geometric Object-Based Change Detection in Cluttered Environments
Mar 05, 2024
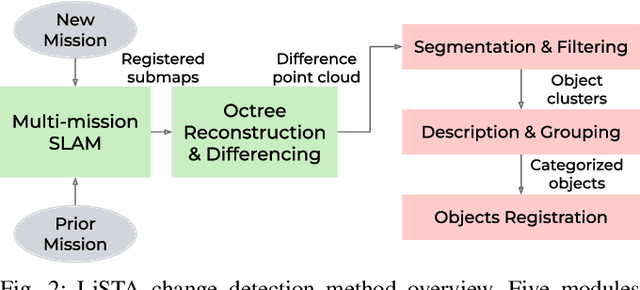
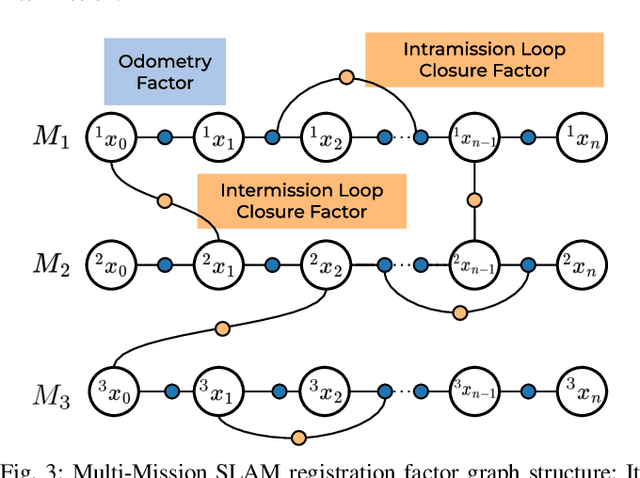

We present LiSTA (LiDAR Spatio-Temporal Analysis), a system to detect probabilistic object-level change over time using multi-mission SLAM. Many applications require such a system, including construction, robotic navigation, long-term autonomy, and environmental monitoring. We focus on the semi-static scenario where objects are added, subtracted, or changed in position over weeks or months. Our system combines multi-mission LiDAR SLAM, volumetric differencing, object instance description, and correspondence grouping using learned descriptors to keep track of an open set of objects. Object correspondences between missions are determined by clustering the object's learned descriptors. We demonstrate our approach using datasets collected in a simulated environment and a real-world dataset captured using a LiDAR system mounted on a quadruped robot monitoring an industrial facility containing static, semi-static, and dynamic objects. Our method demonstrates superior performance in detecting changes in semi-static environments compared to existing methods.
Osprey: Multi-Session Autonomous Aerial Mapping with LiDAR-based SLAM and Next Best View Planning
Nov 06, 2023Aerial mapping systems are important for many surveying applications (e.g., industrial inspection or agricultural monitoring). Semi-autonomous mapping with GPS-guided aerial platforms that fly preplanned missions is already widely available but fully autonomous systems can significantly improve efficiency. Autonomously mapping complex 3D structures requires a system that performs online mapping and mission planning. This paper presents Osprey, an autonomous aerial mapping system with state-of-the-art multi-session mapping capabilities. It enables a non-expert operator to specify a bounded target area that the aerial platform can then map autonomously, over multiple flights if necessary. Field experiments with Osprey demonstrate that this system can achieve greater map coverage of large industrial sites than manual surveys with a pilot-flown aerial platform or a terrestrial laser scanner (TLS). Three sites, with a total ground coverage of $7085$ m$^2$ and a maximum height of $27$ m, were mapped in separate missions using $112$ minutes of autonomous flight time. True colour maps were created from images captured by Osprey using pointcloud and NeRF reconstruction methods. These maps provide useful data for structural inspection tasks.
Language-EXtended Indoor SLAM (LEXIS): A Versatile System for Real-time Visual Scene Understanding
Sep 26, 2023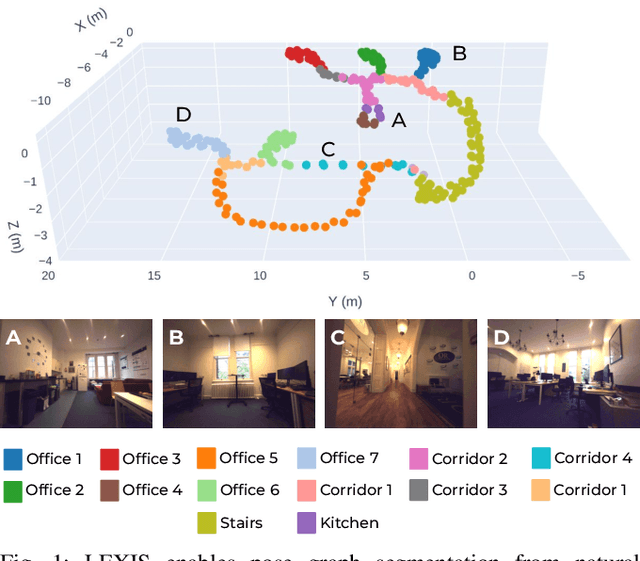
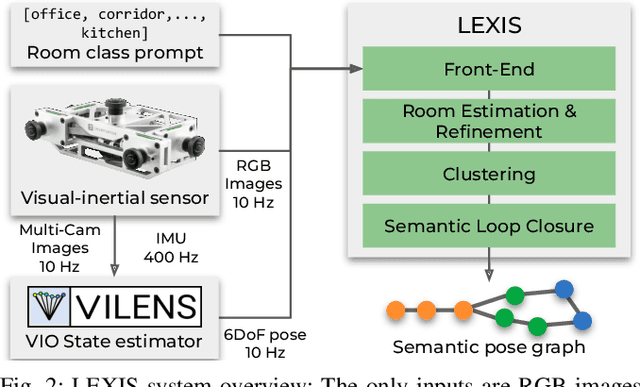
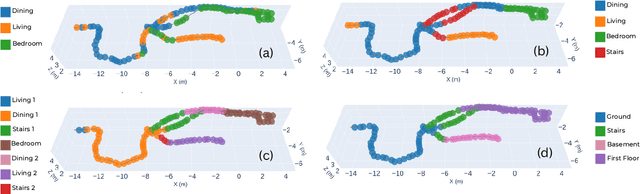
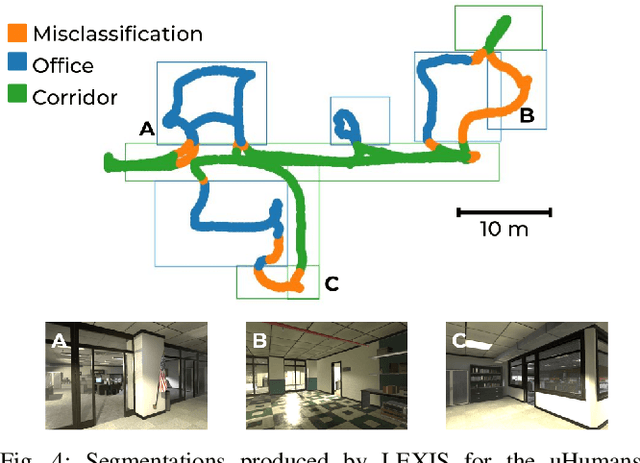
Versatile and adaptive semantic understanding would enable autonomous systems to comprehend and interact with their surroundings. Existing fixed-class models limit the adaptability of indoor mobile and assistive autonomous systems. In this work, we introduce LEXIS, a real-time indoor Simultaneous Localization and Mapping (SLAM) system that harnesses the open-vocabulary nature of Large Language Models (LLMs) to create a unified approach to scene understanding and place recognition. The approach first builds a topological SLAM graph of the environment (using visual-inertial odometry) and embeds Contrastive Language-Image Pretraining (CLIP) features in the graph nodes. We use this representation for flexible room classification and segmentation, serving as a basis for room-centric place recognition. This allows loop closure searches to be directed towards semantically relevant places. Our proposed system is evaluated using both public, simulated data and real-world data, covering office and home environments. It successfully categorizes rooms with varying layouts and dimensions and outperforms the state-of-the-art (SOTA). For place recognition and trajectory estimation tasks we achieve equivalent performance to the SOTA, all also utilizing the same pre-trained model. Lastly, we demonstrate the system's potential for planning.
InstaLoc: One-shot Global Lidar Localisation in Indoor Environments through Instance Learning
May 16, 2023

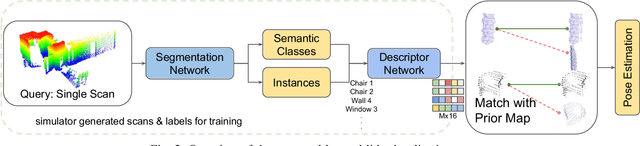
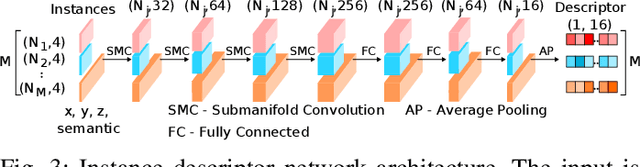
Localization for autonomous robots in prior maps is crucial for their functionality. This paper offers a solution to this problem for indoor environments called InstaLoc, which operates on an individual lidar scan to localize it within a prior map. We draw on inspiration from how humans navigate and position themselves by recognizing the layout of distinctive objects and structures. Mimicking the human approach, InstaLoc identifies and matches object instances in the scene with those from a prior map. As far as we know, this is the first method to use panoptic segmentation directly inferring on 3D lidar scans for indoor localization. InstaLoc operates through two networks based on spatially sparse tensors to directly infer dense 3D lidar point clouds. The first network is a panoptic segmentation network that produces object instances and their semantic classes. The second smaller network produces a descriptor for each object instance. A consensus based matching algorithm then matches the instances to the prior map and estimates a six degrees of freedom (DoF) pose for the input cloud in the prior map. The significance of InstaLoc is that it has two efficient networks. It requires only one to two hours of training on a mobile GPU and runs in real-time at 1 Hz. Our method achieves between two and four times more detections when localizing, as compared to baseline methods, and achieves higher precision on these detections.