 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMayank Kumar
Detecting Errors in Numerical Data via any Regression Model
Jun 03, 2023
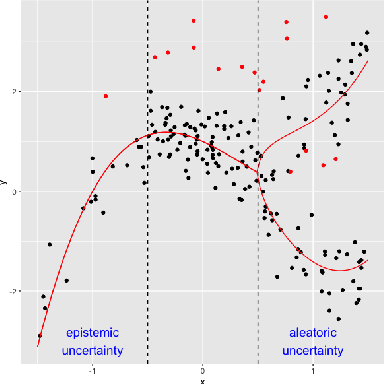
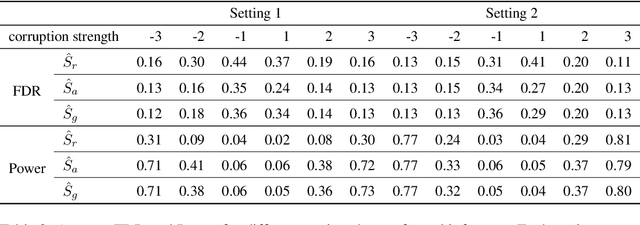
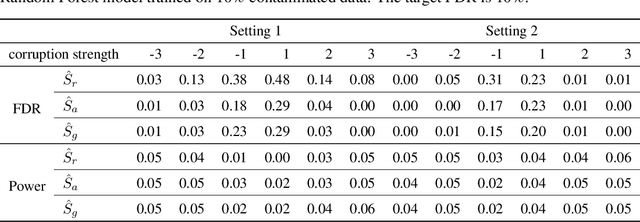
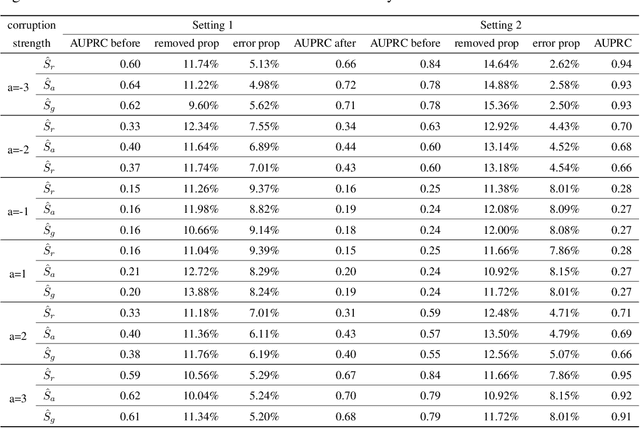
Noise plagues many numerical datasets, where the recorded values in the data may fail to match the true underlying values due to reasons including: erroneous sensors, data entry/processing mistakes, or imperfect human estimates. Here we consider estimating which data values are incorrect along a numerical column. We present a model-agnostic approach that can utilize any regressor (i.e. statistical or machine learning model) which was fit to predict values in this column based on the other variables in the dataset. By accounting for various uncertainties, our approach distinguishes between genuine anomalies and natural data fluctuations, conditioned on the available information in the dataset. We establish theoretical guarantees for our method and show that other approaches like conformal inference struggle to detect errors. We also contribute a new error detection benchmark involving 5 regression datasets with real-world numerical errors (for which the true values are also known). In this benchmark and additional simulation studies, our method identifies incorrect values with better precision/recall than other approaches.
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Oct 18, 2022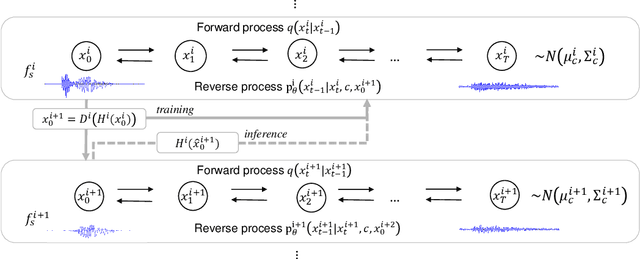
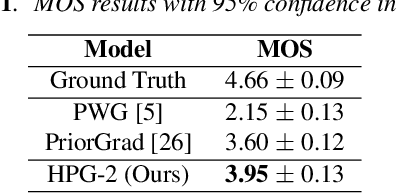
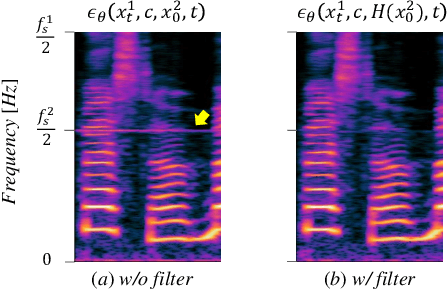
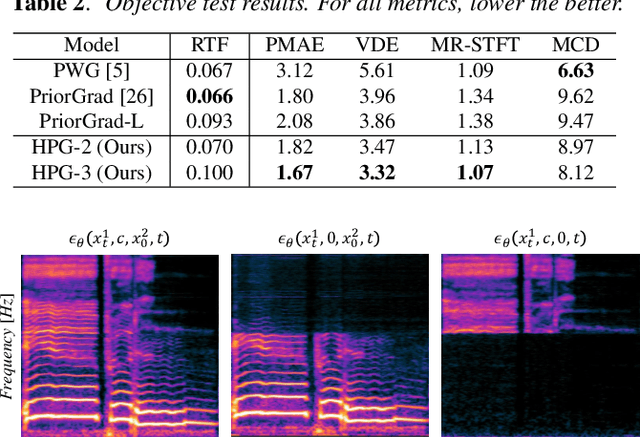
Recent progress in deep generative models has improved the quality of neural vocoders in speech domain. However, generating a high-quality singing voice remains challenging due to a wider variety of musical expressions in pitch, loudness, and pronunciations. In this work, we propose a hierarchical diffusion model for singing voice neural vocoders. The proposed method consists of multiple diffusion models operating in different sampling rates; the model at the lowest sampling rate focuses on generating accurate low-frequency components such as pitch, and other models progressively generate the waveform at higher sampling rates on the basis of the data at the lower sampling rate and acoustic features. Experimental results show that the proposed method produces high-quality singing voices for multiple singers, outperforming state-of-the-art neural vocoders with a similar range of computational costs.
DistancePPG: Robust non-contact vital signs monitoring using a camera
Mar 24, 2015



Vital signs such as pulse rate and breathing rate are currently measured using contact probes. But, non-contact methods for measuring vital signs are desirable both in hospital settings (e.g. in NICU) and for ubiquitous in-situ health tracking (e.g. on mobile phone and computers with webcams). Recently, camera-based non-contact vital sign monitoring have been shown to be feasible. However, camera-based vital sign monitoring is challenging for people with darker skin tone, under low lighting conditions, and/or during movement of an individual in front of the camera. In this paper, we propose distancePPG, a new camera-based vital sign estimation algorithm which addresses these challenges. DistancePPG proposes a new method of combining skin-color change signals from different tracked regions of the face using a weighted average, where the weights depend on the blood perfusion and incident light intensity in the region, to improve the signal-to-noise ratio (SNR) of camera-based estimate. One of our key contributions is a new automatic method for determining the weights based only on the video recording of the subject. The gains in SNR of camera-based PPG estimated using distancePPG translate into reduction of the error in vital sign estimation, and thus expand the scope of camera-based vital sign monitoring to potentially challenging scenarios. Further, a dataset will be released, comprising of synchronized video recordings of face and pulse oximeter based ground truth recordings from the earlobe for people with different skin tones, under different lighting conditions and for various motion scenarios.