 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMd Zahidul Islam
Seizure detection from Electroencephalogram signals via Wavelets and Graph Theory metrics
Nov 28, 2023

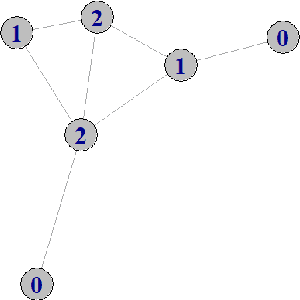
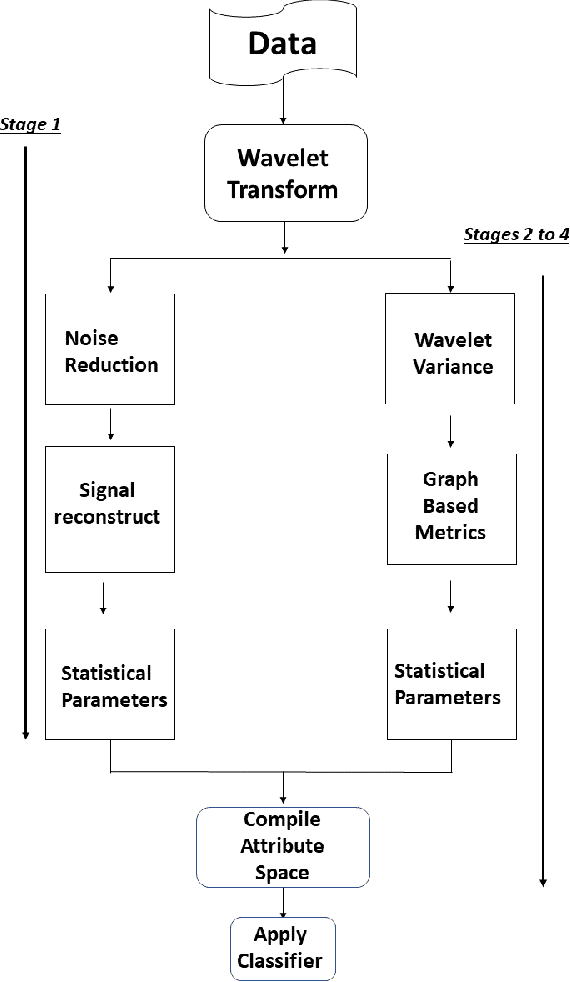
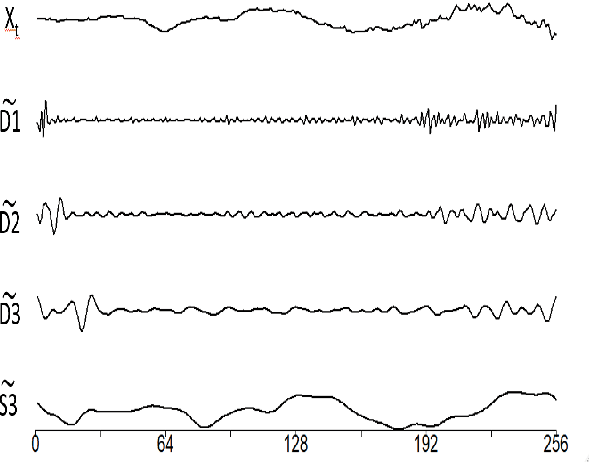
Epilepsy is one of the most prevalent neurological conditions, where an epileptic seizure is a transient occurrence due to abnormal, excessive and synchronous activity in the brain. Electroencephalogram signals emanating from the brain may be captured, analysed and then play a significant role in detection and prediction of epileptic seizures. In this work we enhance upon a previous approach that relied on the differing properties of the wavelet transform. Here we apply the Maximum Overlap Discrete Wavelet Transform to both reduce signal \textit{noise} and use signal variance exhibited at differing inherent frequency levels to develop various metrics of connection between the electrodes placed upon the scalp. %The properties of both the noise reduced signal and the interconnected electrodes differ significantly during the different brain states. Using short duration epochs, to approximate close to real time monitoring, together with simple statistical parameters derived from the reconstructed noise reduced signals we initiate seizure detection. To further improve performance we utilise graph theoretic indicators from derived electrode connectivity. From there we build the attribute space. We utilise open-source software and publicly available data to highlight the superior Recall/Sensitivity performance of our approach, when compared to existing published methods.
Enhancing Cluster Quality of Numerical Datasets with Domain Ontology
Apr 02, 2023


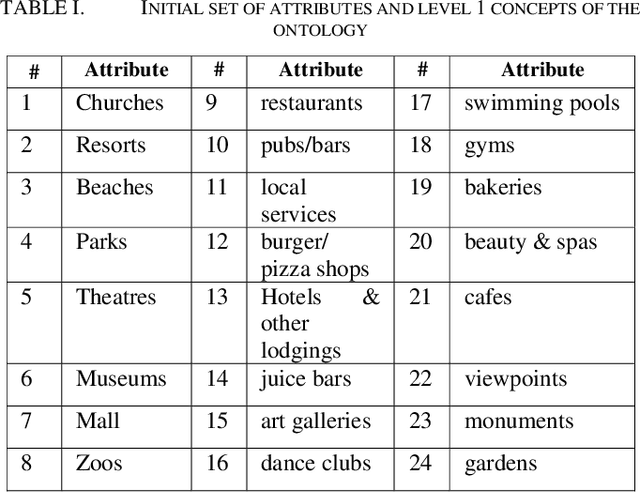
Ontology-based clustering has gained attention in recent years due to the potential benefits of ontology. Current ontology-based clustering approaches have mainly been applied to reduce the dimensionality of attributes in text document clustering. Reduction in dimensionality of attributes using ontology helps to produce high quality clusters for a dataset. However, ontology-based approaches in clustering numerical datasets have not been gained enough attention. Moreover, some literature mentions that ontology-based clustering can produce either high quality or low-quality clusters from a dataset. Therefore, in this paper we present a clustering approach that is based on domain ontology to reduce the dimensionality of attributes in a numerical dataset using domain ontology and to produce high quality clusters. For every dataset, we produce three datasets using domain ontology. We then cluster these datasets using a genetic algorithm-based clustering technique called GenClust++. The clusters of each dataset are evaluated in terms of Sum of Squared-Error (SSE). We use six numerical datasets to evaluate the performance of our ontology-based approach. The experimental results of our approach indicate that cluster quality gradually improves from lower to the higher levels of a domain ontology.
EEG Signal Processing using Wavelets for Accurate Seizure Detection through Cost Sensitive Data Mining
Sep 22, 2021

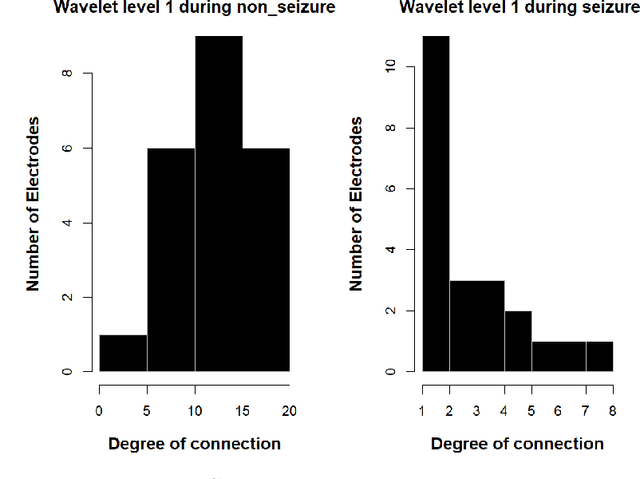

Epilepsy is one of the most common and yet diverse set of chronic neurological disorders. This excessive or synchronous neuronal activity is termed seizure. Electroencephalogram signal processing plays a significant role in detection and prediction of epileptic seizures. In this paper we introduce an approach that relies upon the properties of wavelets for seizure detection. We utilise the Maximum Overlap Discrete Wavelet Transform which enables us to reduce signal noise Then from the variance exhibited in wavelet coefficients we develop connectivity and communication efficiency between the electrodes as these properties differ significantly during a seizure period in comparison to a non-seizure period. We use basic statistical parameters derived from the reconstructed noise reduced signal, electrode connectivity and the efficiency of information transfer to build the attribute space. We have utilised data that are publicly available to test our method that is found to be significantly better than some existing approaches.
Signal Classification using Smooth Coefficients of Multiple wavelets
Sep 21, 2021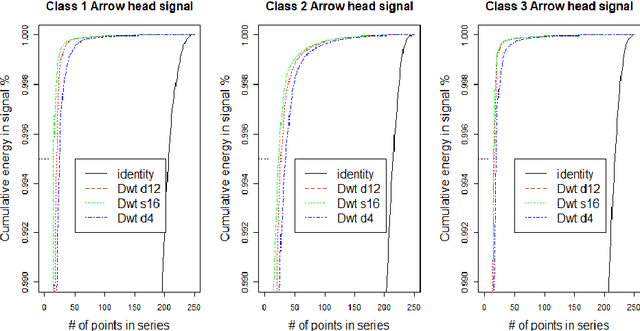
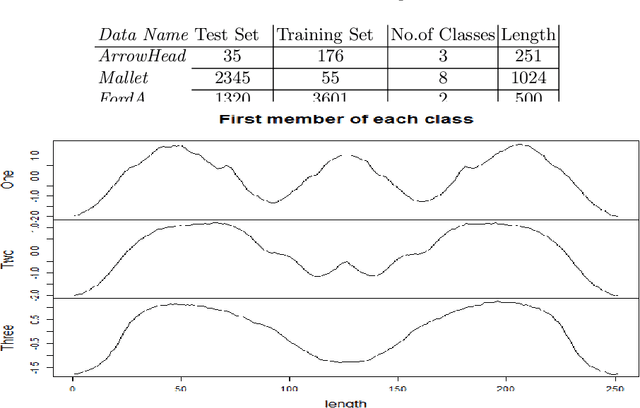


Classification of time series signals has become an important construct and has many practical applications. With existing classifiers we may be able to accurately classify signals, however that accuracy may decline if using a reduced number of attributes. Transforming the data then undertaking reduction in dimensionality may improve the quality of the data analysis, decrease time required for classification and simplify models. We propose an approach, which chooses suitable wavelets to transform the data, then combines the output from these transforms to construct a dataset to then apply ensemble classifiers to. We demonstrate this on different data sets, across different classifiers and use differing evaluation methods. Our experimental results demonstrate the effectiveness of the proposed technique, compared to the approaches that use either raw signal data or a single wavelet transform.
A Framework for Supervised Heterogeneous Transfer Learning using Dynamic Distribution Adaptation and Manifold Regularization
Aug 27, 2021
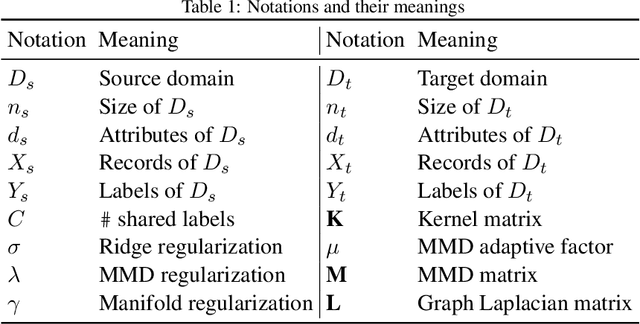
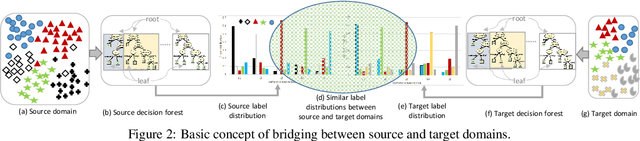

Transfer learning aims to learn classifiers for a target domain by transferring knowledge from a source domain. However, due to two main issues: feature discrepancy and distribution divergence, transfer learning can be a very difficult problem in practice. In this paper, we present a framework called TLF that builds a classifier for the target domain having only few labeled training records by transferring knowledge from the source domain having many labeled records. While existing methods often focus on one issue and leave the other one for the further work, TLF is capable of handling both issues simultaneously. In TLF, we alleviate feature discrepancy by identifying shared label distributions that act as the pivots to bridge the domains. We handle distribution divergence by simultaneously optimizing the structural risk functional, joint distributions between domains, and the manifold consistency underlying marginal distributions. Moreover, for the manifold consistency we exploit its intrinsic properties by identifying k nearest neighbors of a record, where the value of k is determined automatically in TLF. Furthermore, since negative transfer is not desired, we consider only the source records that are belonging to the source pivots during the knowledge transfer. We evaluate TLF on seven publicly available natural datasets and compare the performance of TLF against the performance of eleven state-of-the-art techniques. We also evaluate the effectiveness of TLF in some challenging situations. Our experimental results, including statistical sign test and Nemenyi test analyses, indicate a clear superiority of the proposed framework over the state-of-the-art techniques.
Adaptive Decision Forest: An Incremental Machine Learning Framework
Jan 28, 2021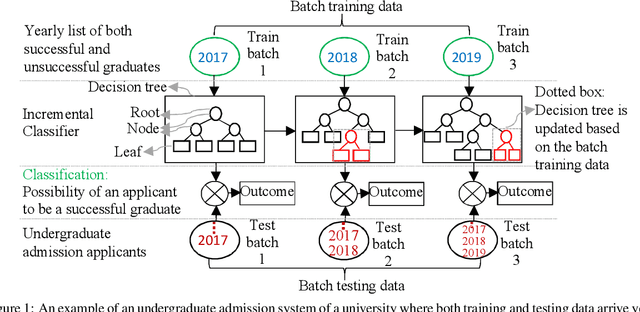
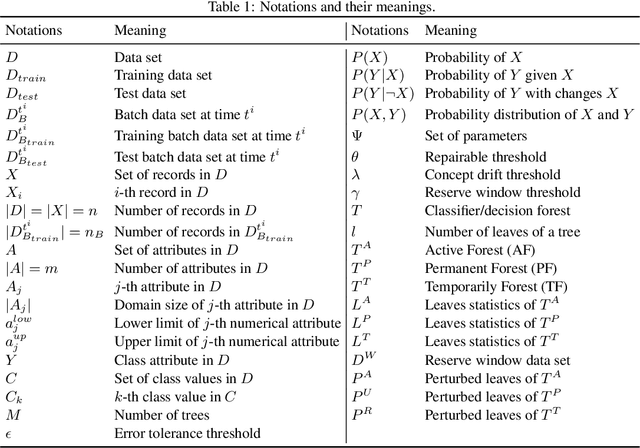


In this study, we present an incremental machine learning framework called Adaptive Decision Forest (ADF), which produces a decision forest to classify new records. Based on our two novel theorems, we introduce a new splitting strategy called iSAT, which allows ADF to classify new records even if they are associated with previously unseen classes. ADF is capable of identifying and handling concept drift; it, however, does not forget previously gained knowledge. Moreover, ADF is capable of handling big data if the data can be divided into batches. We evaluate ADF on five publicly available natural data sets and one synthetic data set, and compare the performance of ADF against the performance of eight state-of-the-art techniques. Our experimental results, including statistical sign test and Nemenyi test analyses, indicate a clear superiority of the proposed framework over the state-of-the-art techniques.
Detecting Autism Spectrum Disorder using Machine Learning
Sep 30, 2020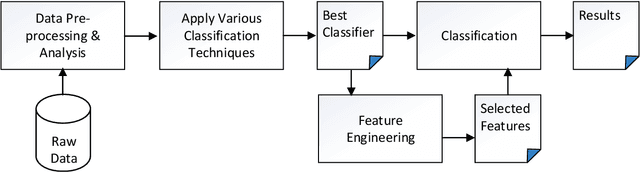
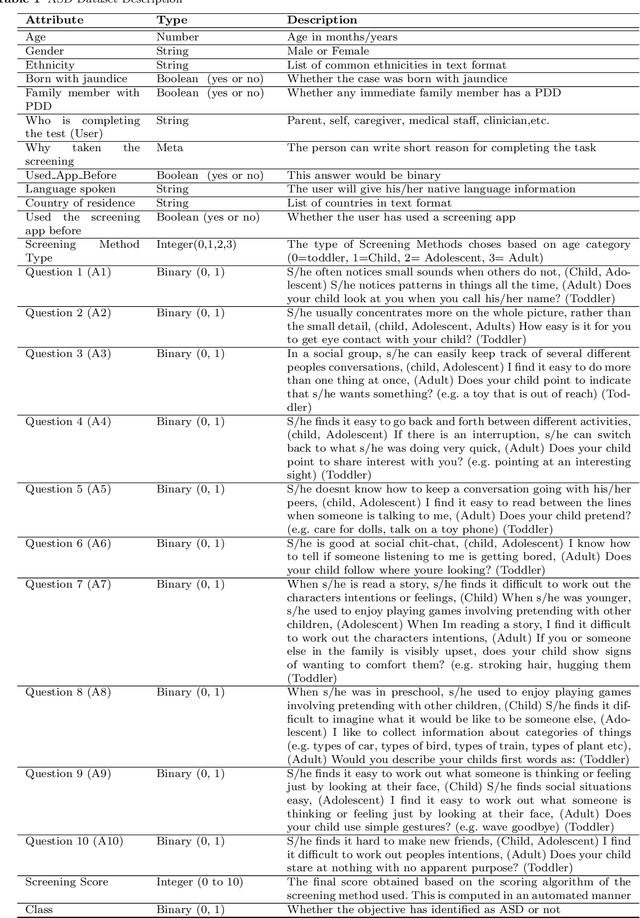
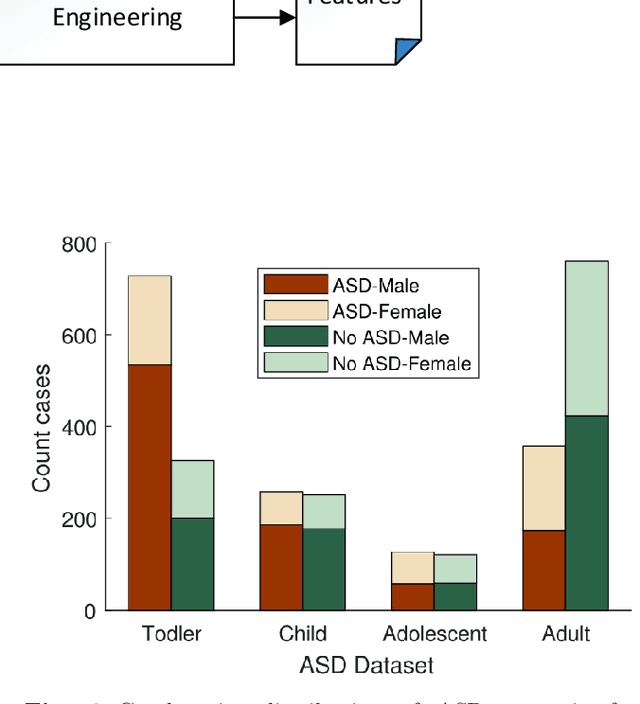

Autism Spectrum Disorder (ASD), which is a neuro development disorder, is often accompanied by sensory issues such an over sensitivity or under sensitivity to sounds and smells or touch. Although its main cause is genetics in nature, early detection and treatment can help to improve the conditions. In recent years, machine learning based intelligent diagnosis has been evolved to complement the traditional clinical methods which can be time consuming and expensive. The focus of this paper is to find out the most significant traits and automate the diagnosis process using available classification techniques for improved diagnosis purpose. We have analyzed ASD datasets of Toddler, Child, Adolescent and Adult. We determine the best performing classifier for these binary datasets using the evaluation metrics recall, precision, F-measures and classification errors. Our finding shows that Sequential minimal optimization (SMO) based Support Vector Machines (SVM) classifier outperforms all other benchmark machine learning algorithms in terms of accuracy during the detection of ASD cases and produces less classification errors compared to other algorithms. Also, we find that Relief Attributes algorithm is the best to identify the most significant attributes in ASD datasets.
FastForest: Increasing Random Forest Processing Speed While Maintaining Accuracy
Apr 06, 2020
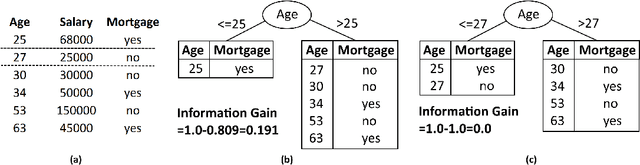
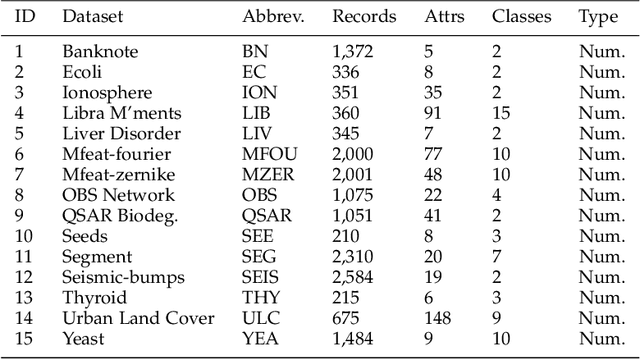
Random Forest remains one of Data Mining's most enduring ensemble algorithms, achieving well-documented levels of accuracy and processing speed, as well as regularly appearing in new research. However, with data mining now reaching the domain of hardware-constrained devices such as smartphones and Internet of Things (IoT) devices, there is continued need for further research into algorithm efficiency to deliver greater processing speed without sacrificing accuracy. Our proposed FastForest algorithm delivers an average 24% increase in processing speed compared with Random Forest whilst maintaining (and frequently exceeding) it on classification accuracy over tests involving 45 datasets. FastForest achieves this result through a combination of three optimising components - Subsample Aggregating ('Subbagging'), Logarithmic Split-Point Sampling and Dynamic Restricted Subspacing. Moreover, detailed testing of Subbagging sizes has found an optimal scalar delivering a positive mix of processing performance and accuracy.
A Novel Incremental Clustering Technique with Concept Drift Detection
Mar 30, 2020


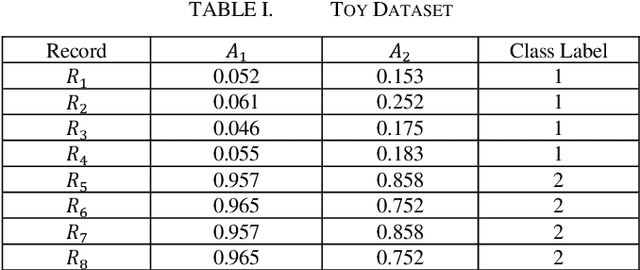
Data are being collected from various aspects of life. These data can often arrive in chunks/batches. Traditional static clustering algorithms are not suitable for dynamic datasets, i.e., when data arrive in streams of chunks/batches. If we apply a conventional clustering technique over the combined dataset, then every time a new batch of data comes, the process can be slow and wasteful. Moreover, it can be challenging to store the combined dataset in memory due to its ever-increasing size. As a result, various incremental clustering techniques have been proposed. These techniques need to efficiently update the current clustering result whenever a new batch arrives, to adapt the current clustering result/solution with the latest data. These techniques also need the ability to detect concept drifts when the clustering pattern of a new batch is significantly different from older batches. Sometimes, clustering patterns may drift temporarily in a single batch while the next batches do not exhibit the drift. Therefore, incremental clustering techniques need the ability to detect a temporary drift and sustained drift. In this paper, we propose an efficient incremental clustering algorithm called UIClust. It is designed to cluster streams of data chunks, even when there are temporary or sustained concept drifts. We evaluate the performance of UIClust by comparing it with a recently published, high-quality incremental clustering algorithm. We use real and synthetic datasets. We compare the results by using well-known clustering evaluation criteria: entropy, sum of squared errors (SSE), and execution time. Our results show that UIClust outperforms the existing technique in all our experiments.
Tree Index: A New Cluster Evaluation Technique
Mar 24, 2020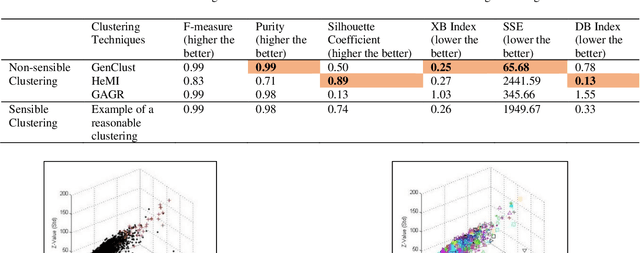


We introduce a cluster evaluation technique called Tree Index. Our Tree Index algorithm aims at describing the structural information of the clustering rather than the quantitative format of cluster-quality indexes (where the representation power of clustering is some cumulative error similar to vector quantization). Our Tree Index is finding margins amongst clusters for easy learning without the complications of Minimum Description Length. Our Tree Index produces a decision tree from the clustered data set, using the cluster identifiers as labels. It combines the entropy of each leaf with their depth. Intuitively, a shorter tree with pure leaves generalizes the data well (the clusters are easy to learn because they are well separated). So, the labels are meaningful clusters. If the clustering algorithm does not separate well, trees learned from their results will be large and too detailed. We show that, on the clustering results (obtained by various techniques) on a brain dataset, Tree Index discriminates between reasonable and non-sensible clusters. We confirm the effectiveness of Tree Index through graphical visualizations. Tree Index evaluates the sensible solutions higher than the non-sensible solutions while existing cluster-quality indexes fail to do so.