 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMd. Ismail Hossain
LumiNet: The Bright Side of Perceptual Knowledge Distillation
Oct 05, 2023
In knowledge distillation research, feature-based methods have dominated due to their ability to effectively tap into extensive teacher models. In contrast, logit-based approaches are considered to be less adept at extracting hidden 'dark knowledge' from teachers. To bridge this gap, we present LumiNet, a novel knowledge-transfer algorithm designed to enhance logit-based distillation. We introduce a perception matrix that aims to recalibrate logits through adjustments based on the model's representation capability. By meticulously analyzing intra-class dynamics, LumiNet reconstructs more granular inter-class relationships, enabling the student model to learn a richer breadth of knowledge. Both teacher and student models are mapped onto this refined matrix, with the student's goal being to minimize representational discrepancies. Rigorous testing on benchmark datasets (CIFAR-100, ImageNet, and MSCOCO) attests to LumiNet's efficacy, revealing its competitive edge over leading feature-based methods. Moreover, in exploring the realm of transfer learning, we assess how effectively the student model, trained using our method, adapts to downstream tasks. Notably, when applied to Tiny ImageNet, the transferred features exhibit remarkable performance, further underscoring LumiNet's versatility and robustness in diverse settings. With LumiNet, we hope to steer the research discourse towards a renewed interest in the latent capabilities of logit-based knowledge distillation.
COLT: Cyclic Overlapping Lottery Tickets for Faster Pruning of Convolutional Neural Networks
Dec 24, 2022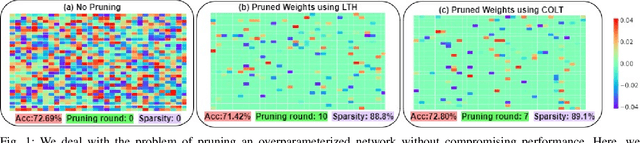
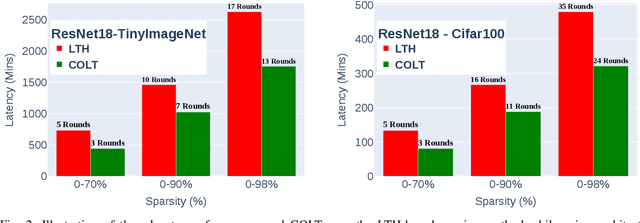
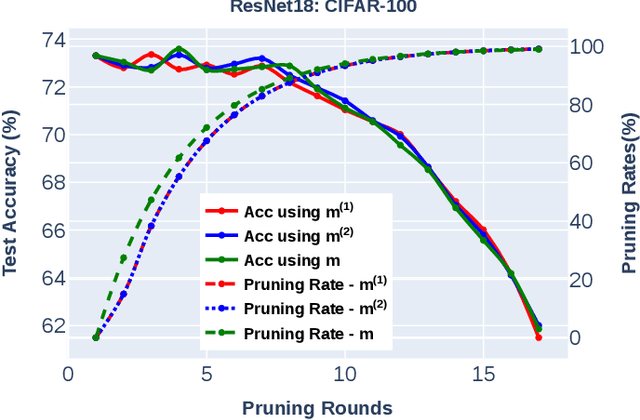
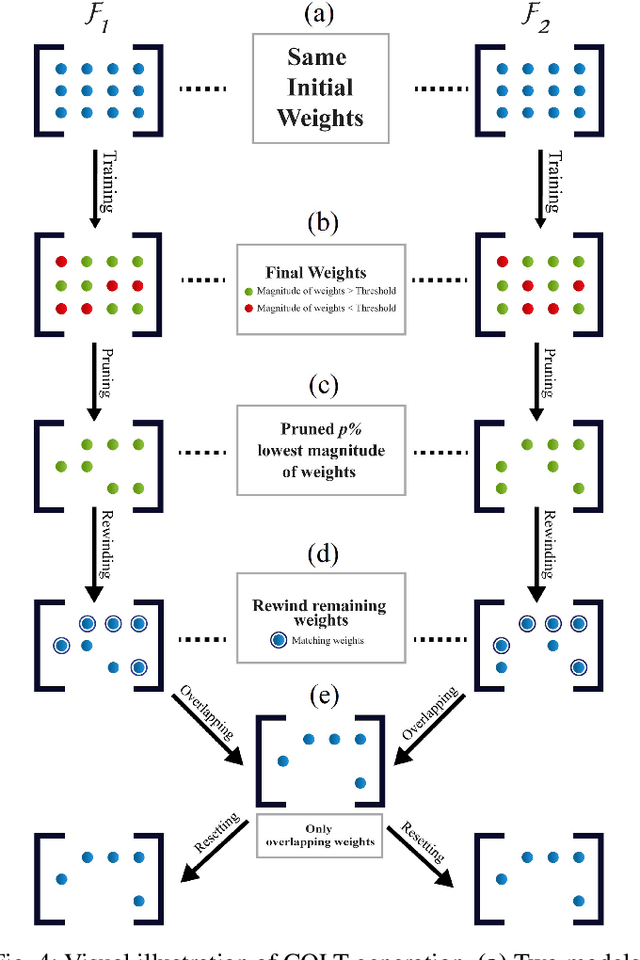
Pruning refers to the elimination of trivial weights from neural networks. The sub-networks within an overparameterized model produced after pruning are often called Lottery tickets. This research aims to generate winning lottery tickets from a set of lottery tickets that can achieve similar accuracy to the original unpruned network. We introduce a novel winning ticket called Cyclic Overlapping Lottery Ticket (COLT) by data splitting and cyclic retraining of the pruned network from scratch. We apply a cyclic pruning algorithm that keeps only the overlapping weights of different pruned models trained on different data segments. Our results demonstrate that COLT can achieve similar accuracies (obtained by the unpruned model) while maintaining high sparsities. We show that the accuracy of COLT is on par with the winning tickets of Lottery Ticket Hypothesis (LTH) and, at times, is better. Moreover, COLTs can be generated using fewer iterations than tickets generated by the popular Iterative Magnitude Pruning (IMP) method. In addition, we also notice COLTs generated on large datasets can be transferred to small ones without compromising performance, demonstrating its generalizing capability. We conduct all our experiments on Cifar-10, Cifar-100 & TinyImageNet datasets and report superior performance than the state-of-the-art methods.
Bangla-Wave: Improving Bangla Automatic Speech Recognition Utilizing N-gram Language Models
Sep 13, 2022


Although over 300M around the world speak Bangla, scant work has been done in improving Bangla voice-to-text transcription due to Bangla being a low-resource language. However, with the introduction of the Bengali Common Voice 9.0 speech dataset, Automatic Speech Recognition (ASR) models can now be significantly improved. With 399hrs of speech recordings, Bengali Common Voice is the largest and most diversified open-source Bengali speech corpus in the world. In this paper, we outperform the SOTA pretrained Bengali ASR models by finetuning a pretrained wav2vec2 model on the common voice dataset. We also demonstrate how to significantly improve the performance of an ASR model by adding an n-gram language model as a post-processor. Finally, we do some experiments and hyperparameter tuning to generate a robust Bangla ASR model that is better than the existing ASR models.
LILA-BOTI : Leveraging Isolated Letter Accumulations By Ordering Teacher Insights for Bangla Handwriting Recognition
May 23, 2022



Word-level handwritten optical character recognition (OCR) remains a challenge for morphologically rich languages like Bangla. The complexity arises from the existence of a large number of alphabets, the presence of several diacritic forms, and the appearance of complex conjuncts. The difficulty is exacerbated by the fact that some graphemes occur infrequently but remain indispensable, so addressing the class imbalance is required for satisfactory results. This paper addresses this issue by introducing two knowledge distillation methods: Leveraging Isolated Letter Accumulations By Ordering Teacher Insights (LILA-BOTI) and Super Teacher LILA-BOTI. In both cases, a Convolutional Recurrent Neural Network (CRNN) student model is trained with the dark knowledge gained from a printed isolated character recognition teacher model. We conducted inter-dataset testing on \emph{BN-HTRd} and \emph{BanglaWriting} as our evaluation protocol, thus setting up a challenging problem where the results would better reflect the performance on unseen data. Our evaluations achieved up to a 3.5% increase in the F1-Macro score for the minor classes and up to 4.5% increase in our overall word recognition rate when compared with the base model (No KD) and conventional KD.