 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeiziniu Li
MEMO: Coverage-guided Model Generation For Deep Learning Library Testing
Aug 02, 2022




Recent deep learning (DL) applications are mostly built on top of DL libraries. The quality assurance of these libraries is critical to the dependable deployment of DL applications. A few techniques have thereby been proposed to test DL libraries by generating DL models as test inputs. Then these techniques feed those DL models to DL libraries for making inferences, in order to exercise DL libraries modules related to a DL model's execution. However, the test effectiveness of these techniques is constrained by the diversity of generated DL models. Our investigation finds that these techniques can cover at most 11.7% of layer pairs (i.e., call sequence between two layer APIs) and 55.8% of layer parameters (e.g., "padding" in Conv2D). As a result, we find that many bugs arising from specific layer pairs and parameters can be missed by existing techniques. In view of the limitations of existing DL library testing techniques, we propose MEMO to efficiently generate diverse DL models by exploring layer types, layer pairs, and layer parameters. MEMO: (1) designs an initial model reduction technique to boost test efficiency without compromising model diversity; and (2) designs a set of mutation operators for a customized Markov Chain Monte Carlo (MCMC) algorithm to explore new layer types, layer pairs, and layer parameters. We evaluate MEMO on seven popular DL libraries, including four for model execution (TensorFlow, PyTorch and MXNet, and ONNX) and three for model conversions (Keras-MXNet, TF2ONNX, ONNX2PyTorch). The evaluation result shows that MEMO outperforms recent works by covering 10.3% more layer pairs, 15.3% more layer parameters, and 2.3% library branches. Moreover, MEMO detects 29 new bugs in the latest version of DL libraries, with 17 of them confirmed by DL library developers, and 5 of those confirmed bugs have been fixed.
DeepFD: Automated Fault Diagnosis and Localization for Deep Learning Programs
May 04, 2022



As Deep Learning (DL) systems are widely deployed for mission-critical applications, debugging such systems becomes essential. Most existing works identify and repair suspicious neurons on the trained Deep Neural Network (DNN), which, unfortunately, might be a detour. Specifically, several existing studies have reported that many unsatisfactory behaviors are actually originated from the faults residing in DL programs. Besides, locating faulty neurons is not actionable for developers, while locating the faulty statements in DL programs can provide developers with more useful information for debugging. Though a few recent studies were proposed to pinpoint the faulty statements in DL programs or the training settings (e.g. too large learning rate), they were mainly designed based on predefined rules, leading to many false alarms or false negatives, especially when the faults are beyond their capabilities. In view of these limitations, in this paper, we proposed DeepFD, a learning-based fault diagnosis and localization framework which maps the fault localization task to a learning problem. In particular, it infers the suspicious fault types via monitoring the runtime features extracted during DNN model training and then locates the diagnosed faults in DL programs. It overcomes the limitations by identifying the root causes of faults in DL programs instead of neurons and diagnosing the faults by a learning approach instead of a set of hard-coded rules. The evaluation exhibits the potential of DeepFD. It correctly diagnoses 52% faulty DL programs, compared with around half (27%) achieved by the best state-of-the-art works. Besides, for fault localization, DeepFD also outperforms the existing works, correctly locating 42% faulty programs, which almost doubles the best result (23%) achieved by the existing works.
SemMT: A Semantic-based Testing Approach for Machine Translation Systems
Dec 03, 2020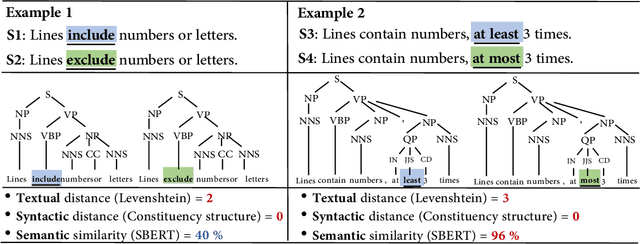


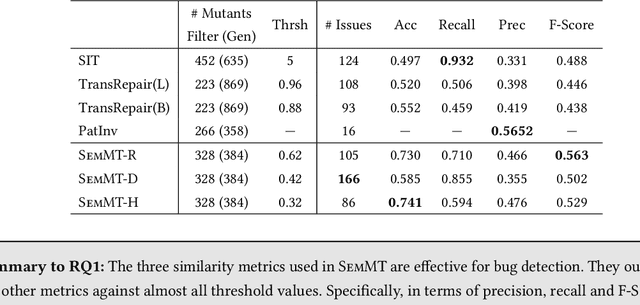
Machine translation has wide applications in daily life. In mission-critical applications such as translating official documents, incorrect translation can have unpleasant or sometimes catastrophic consequences. This motivates recent research on testing methodologies for machine translation systems. Existing methodologies mostly rely on metamorphic relations designed at the textual level (e.g., Levenshtein distance) or syntactic level (e.g., the distance between grammar structures) to determine the correctness of translation results. However, these metamorphic relations do not consider whether the original and translated sentences have the same meaning (i.e., Semantic similarity). Therefore, in this paper, we propose SemMT, an automatic testing approach for machine translation systems based on semantic similarity checking. SemMT applies round-trip translation and measures the semantic similarity between the original and translated sentences. Our insight is that the semantics expressed by the logic and numeric constraint in sentences can be captured using regular expressions (or deterministic finite automata) where efficient equivalence/similarity checking algorithms are available. Leveraging the insight, we propose three semantic similarity metrics and implement them in SemMT. The experiment result reveals SemMT can achieve higher effectiveness compared with state-of-the-art works, achieving an increase of 21% and 23% on accuracy and F-Score, respectively. We also explore potential improvements that can be achieved when proper combinations of metrics are adopted. Finally, we discuss a solution to locate the suspicious trip in round-trip translation, which may shed lights on further exploration.