 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelanie Weber
On the hardness of learning under symmetries
Jan 03, 2024
We study the problem of learning equivariant neural networks via gradient descent. The incorporation of known symmetries ("equivariance") into neural nets has empirically improved the performance of learning pipelines, in domains ranging from biology to computer vision. However, a rich yet separate line of learning theoretic research has demonstrated that actually learning shallow, fully-connected (i.e. non-symmetric) networks has exponential complexity in the correlational statistical query (CSQ) model, a framework encompassing gradient descent. In this work, we ask: are known problem symmetries sufficient to alleviate the fundamental hardness of learning neural nets with gradient descent? We answer this question in the negative. In particular, we give lower bounds for shallow graph neural networks, convolutional networks, invariant polynomials, and frame-averaged networks for permutation subgroups, which all scale either superpolynomially or exponentially in the relevant input dimension. Therefore, in spite of the significant inductive bias imparted via symmetry, actually learning the complete classes of functions represented by equivariant neural networks via gradient descent remains hard.
Effective Structural Encodings via Local Curvature Profiles
Nov 24, 2023Structural and Positional Encodings can significantly improve the performance of Graph Neural Networks in downstream tasks. Recent literature has begun to systematically investigate differences in the structural properties that these approaches encode, as well as performance trade-offs between them. However, the question of which structural properties yield the most effective encoding remains open. In this paper, we investigate this question from a geometric perspective. We propose a novel structural encoding based on discrete Ricci curvature (Local Curvature Profiles, short LCP) and show that it significantly outperforms existing encoding approaches. We further show that combining local structural encodings, such as LCP, with global positional encodings improves downstream performance, suggesting that they capture complementary geometric information. Finally, we compare different encoding types with (curvature-based) rewiring techniques. Rewiring has recently received a surge of interest due to its ability to improve the performance of Graph Neural Networks by mitigating over-smoothing and over-squashing effects. Our results suggest that utilizing curvature information for structural encodings delivers significantly larger performance increases than rewiring.
Mitigating Over-Smoothing and Over-Squashing using Augmentations of Forman-Ricci Curvature
Sep 17, 2023While Graph Neural Networks (GNNs) have been successfully leveraged for learning on graph-structured data across domains, several potential pitfalls have been described recently. Those include the inability to accurately leverage information encoded in long-range connections (over-squashing), as well as difficulties distinguishing the learned representations of nearby nodes with growing network depth (over-smoothing). An effective way to characterize both effects is discrete curvature: Long-range connections that underlie over-squashing effects have low curvature, whereas edges that contribute to over-smoothing have high curvature. This observation has given rise to rewiring techniques, which add or remove edges to mitigate over-smoothing and over-squashing. Several rewiring approaches utilizing graph characteristics, such as curvature or the spectrum of the graph Laplacian, have been proposed. However, existing methods, especially those based on curvature, often require expensive subroutines and careful hyperparameter tuning, which limits their applicability to large-scale graphs. Here we propose a rewiring technique based on Augmented Forman-Ricci curvature (AFRC), a scalable curvature notation, which can be computed in linear time. We prove that AFRC effectively characterizes over-smoothing and over-squashing effects in message-passing GNNs. We complement our theoretical results with experiments, which demonstrate that the proposed approach achieves state-of-the-art performance while significantly reducing the computational cost in comparison with other methods. Utilizing fundamental properties of discrete curvature, we propose effective heuristics for hyperparameters in curvature-based rewiring, which avoids expensive hyperparameter searches, further improving the scalability of the proposed approach.
Curvature-based Clustering on Graphs
Jul 19, 2023

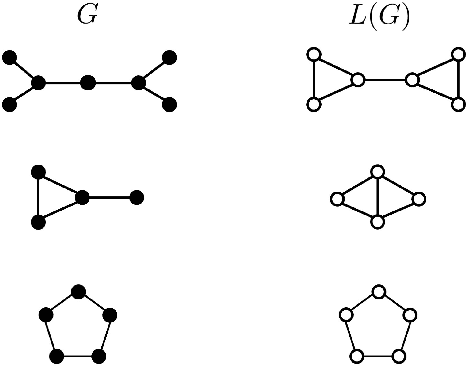
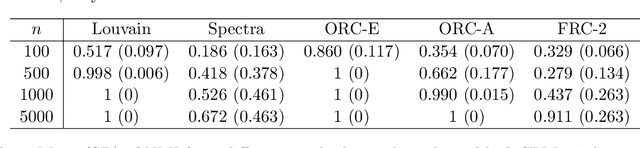
Unsupervised node clustering (or community detection) is a classical graph learning task. In this paper, we study algorithms, which exploit the geometry of the graph to identify densely connected substructures, which form clusters or communities. Our method implements discrete Ricci curvatures and their associated geometric flows, under which the edge weights of the graph evolve to reveal its community structure. We consider several discrete curvature notions and analyze the utility of the resulting algorithms. In contrast to prior literature, we study not only single-membership community detection, where each node belongs to exactly one community, but also mixed-membership community detection, where communities may overlap. For the latter, we argue that it is beneficial to perform community detection on the line graph, i.e., the graph's dual. We provide both theoretical and empirical evidence for the utility of our curvature-based clustering algorithms. In addition, we give several results on the relationship between the curvature of a graph and that of its dual, which enable the efficient implementation of our proposed mixed-membership community detection approach and which may be of independent interest for curvature-based network analysis.
Continuum Limits of Ollivier's Ricci Curvature on data clouds: pointwise consistency and global lower bounds
Jul 05, 2023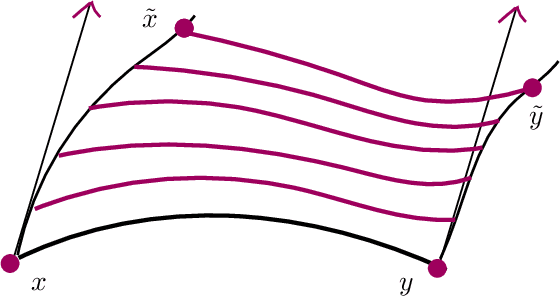

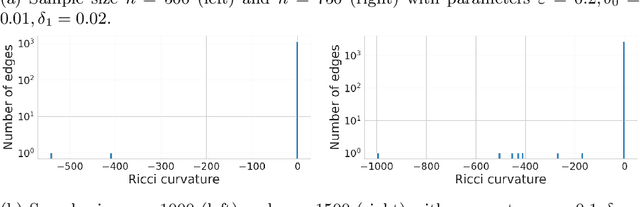
Let $\mathcal{M} \subseteq \mathbb{R}^d$ denote a low-dimensional manifold and let $\mathcal{X}= \{ x_1, \dots, x_n \}$ be a collection of points uniformly sampled from $\mathcal{M}$. We study the relationship between the curvature of a random geometric graph built from $\mathcal{X}$ and the curvature of the manifold $\mathcal{M}$ via continuum limits of Ollivier's discrete Ricci curvature. We prove pointwise, non-asymptotic consistency results and also show that if $\mathcal{M}$ has Ricci curvature bounded from below by a positive constant, then the random geometric graph will inherit this global structural property with high probability. We discuss applications of the global discrete curvature bounds to contraction properties of heat kernels on graphs, as well as implications for manifold learning from data clouds. In particular, we show that the consistency results allow for characterizing the intrinsic curvature of a manifold from extrinsic curvature.
LegalRelectra: Mixed-domain Language Modeling for Long-range Legal Text Comprehension
Dec 16, 2022
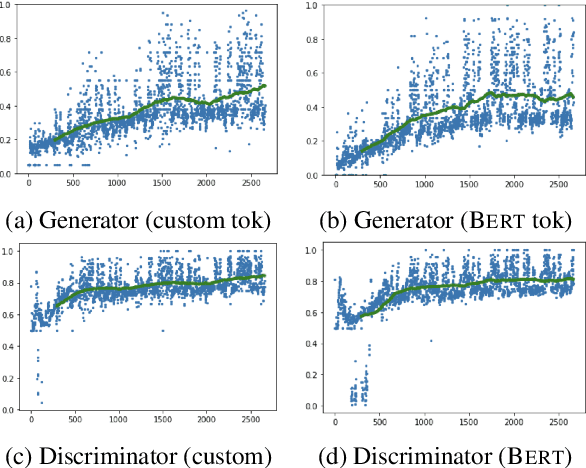
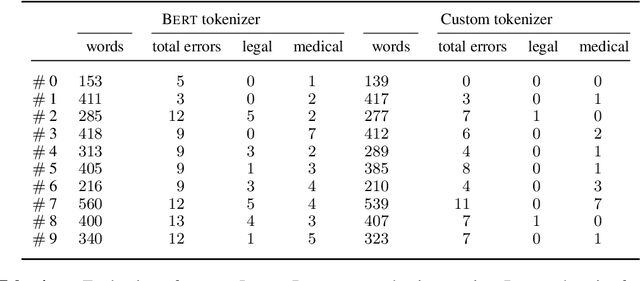
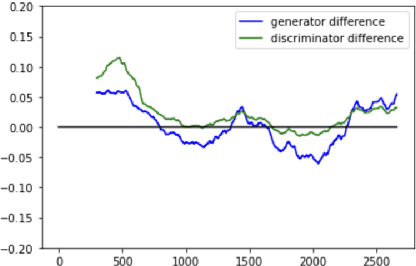
The application of Natural Language Processing (NLP) to specialized domains, such as the law, has recently received a surge of interest. As many legal services rely on processing and analyzing large collections of documents, automating such tasks with NLP tools emerges as a key challenge. Many popular language models, such as BERT or RoBERTa, are general-purpose models, which have limitations on processing specialized legal terminology and syntax. In addition, legal documents may contain specialized vocabulary from other domains, such as medical terminology in personal injury text. Here, we propose LegalRelectra, a legal-domain language model that is trained on mixed-domain legal and medical corpora. We show that our model improves over general-domain and single-domain medical and legal language models when processing mixed-domain (personal injury) text. Our training architecture implements the Electra framework, but utilizes Reformer instead of BERT for its generator and discriminator. We show that this improves the model's performance on processing long passages and results in better long-range text comprehension.
On a class of geodesically convex optimization problems solved via Euclidean MM methods
Jun 22, 2022

We study geodesically convex (g-convex) problems that can be written as a difference of Euclidean convex functions. This structure arises in several optimization problems in statistics and machine learning, e.g., for matrix scaling, M-estimators for covariances, and Brascamp-Lieb inequalities. Our work offers efficient algorithms that on the one hand exploit g-convexity to ensure global optimality along with guarantees on iteration complexity. On the other hand, the split structure permits us to develop Euclidean Majorization-Minorization algorithms that help us bypass the need to compute expensive Riemannian operations such as exponential maps and parallel transport. We illustrate our results by specializing them to a few concrete optimization problems that have been previously studied in the machine learning literature. Ultimately, we hope our work helps motivate the broader search for mixed Euclidean-Riemannian optimization algorithms.
Identifying biases in legal data: An algorithmic fairness perspective
Sep 21, 2021
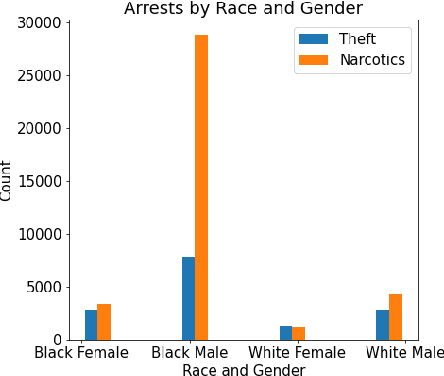

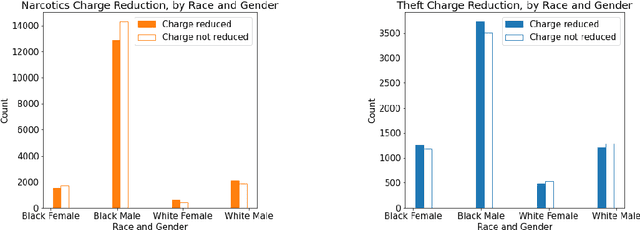
The need to address representation biases and sentencing disparities in legal case data has long been recognized. Here, we study the problem of identifying and measuring biases in large-scale legal case data from an algorithmic fairness perspective. Our approach utilizes two regression models: A baseline that represents the decisions of a "typical" judge as given by the data and a "fair" judge that applies one of three fairness concepts. Comparing the decisions of the "typical" judge and the "fair" judge allows for quantifying biases across demographic groups, as we demonstrate in four case studies on criminal data from Cook County (Illinois).
Robust Large-Margin Learning in Hyperbolic Space
Apr 11, 2020

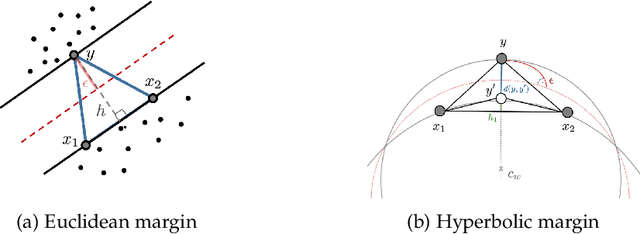

Recently, there has been a surge of interest in representation learning in hyperbolic spaces, driven by their ability to represent hierarchical data with significantly fewer dimensions than standard Euclidean spaces. However, the viability and benefits of hyperbolic spaces for downstream machine learning tasks have received less attention. In this paper, we present, to our knowledge, the first theoretical guarantees for learning a classifier in hyperbolic rather than Euclidean space. Specifically, we consider the problem of learning a large-margin classifier for data possessing a hierarchical structure. Our first contribution is a hyperbolic perceptron algorithm, which provably converges to a separating hyperplane. We then provide an algorithm to efficiently learn a large-margin hyperplane, relying on the careful injection of adversarial examples. Finally, we prove that for hierarchical data that embeds well into hyperbolic space, the low embedding dimension ensures superior guarantees when learning the classifier directly in hyperbolic space.
Neighborhood Growth Determines Geometric Priors for Relational Representation Learning
Oct 12, 2019
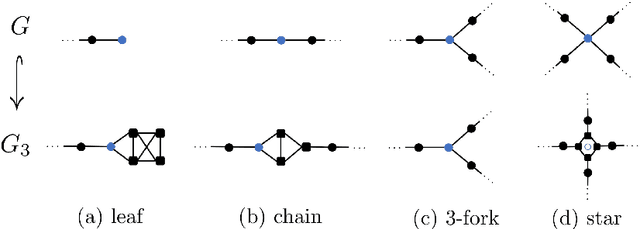

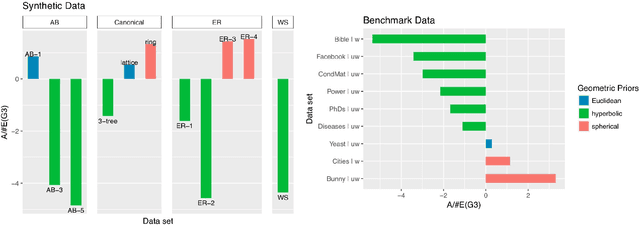
The problem of identifying geometric structure in heterogeneous, high-dimensional data is a cornerstone of representation learning. While there exists a large body of literature on the embeddability of canonical graphs, such as lattices or trees, the heterogeneity of the relational data typically encountered in practice limits the applicability of these classical methods. In this paper, we propose a combinatorial approach to evaluating embeddability, i.e., to decide whether a data set is best represented in Euclidean, Hyperbolic or Spherical space. Our method analyzes nearest-neighbor structures and local neighborhood growth rates to identify the geometric priors of suitable embedding spaces. For canonical graphs, the algorithm's prediction provably matches classical results. As for large, heterogeneous graphs, we introduce an efficiently computable statistic that approximates the algorithm's decision rule. We validate our method over a range of benchmark data sets and compare with recently published optimization-based embeddability methods.