 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeng-Li Shih
3D Photography using Context-aware Layered Depth Inpainting
Apr 14, 2020
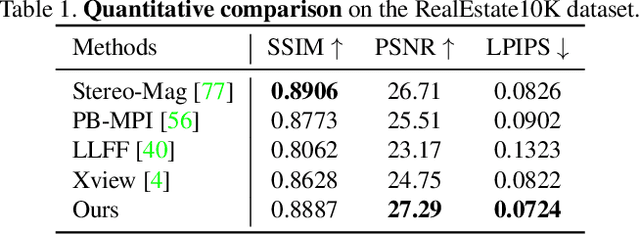
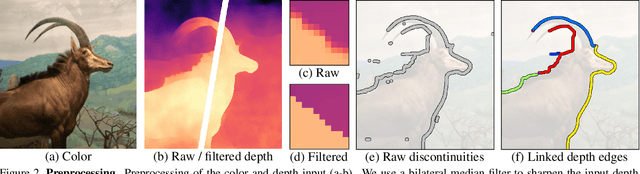
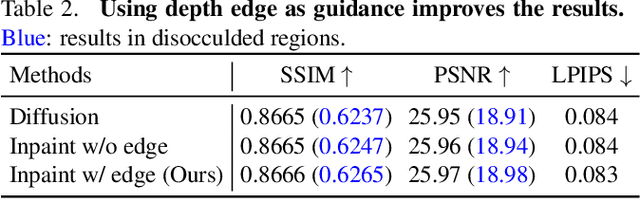

We propose a method for converting a single RGB-D input image into a 3D photo - a multi-layer representation for novel view synthesis that contains hallucinated color and depth structures in regions occluded in the original view. We use a Layered Depth Image with explicit pixel connectivity as underlying representation, and present a learning-based inpainting model that synthesizes new local color-and-depth content into the occluded region in a spatial context-aware manner. The resulting 3D photos can be efficiently rendered with motion parallax using standard graphics engines. We validate the effectiveness of our method on a wide range of challenging everyday scenes and show fewer artifacts compared with the state of the arts.
Self-Supervised Learning of Depth and Camera Motion from 360° Videos
Nov 13, 2018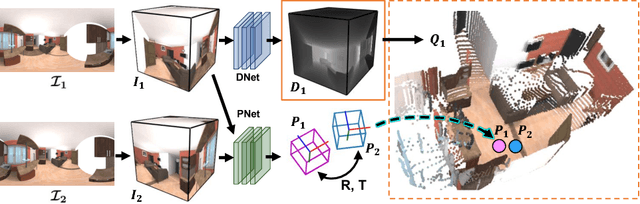
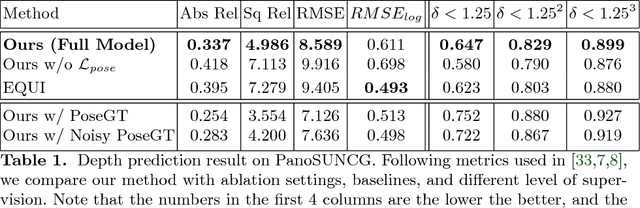
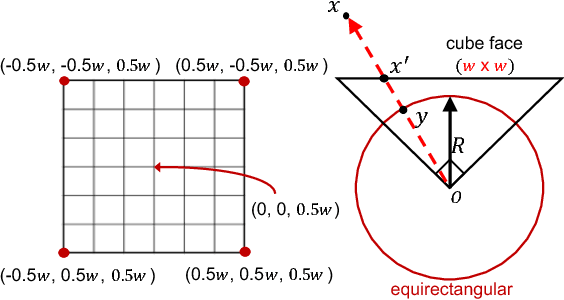
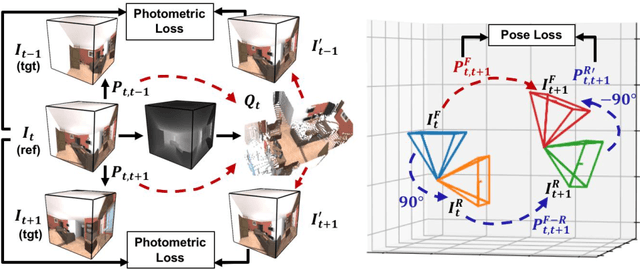
As 360{\deg} cameras become prevalent in many autonomous systems (e.g., self-driving cars and drones), efficient 360{\deg} perception becomes more and more important. We propose a novel self-supervised learning approach for predicting the omnidirectional depth and camera motion from a 360{\deg} video. In particular, starting from the SfMLearner, which is designed for cameras with normal field-of-view, we introduce three key features to process 360{\deg} images efficiently. Firstly, we convert each image from equirectangular projection to cubic projection in order to avoid image distortion. In each network layer, we use Cube Padding (CP), which pads intermediate features from adjacent faces, to avoid image boundaries. Secondly, we propose a novel "spherical" photometric consistency constraint on the whole viewing sphere. In this way, no pixel will be projected outside the image boundary which typically happens in images with normal field-of-view. Finally, rather than naively estimating six independent camera motions (i.e., naively applying SfM-Learner to each face on a cube), we propose a novel camera pose consistency loss to ensure the estimated camera motions reaching consensus. To train and evaluate our approach, we collect a new PanoSUNCG dataset containing a large amount of 360{\deg} videos with groundtruth depth and camera motion. Our approach achieves state-of-the-art depth prediction and camera motion estimation on PanoSUNCG with faster inference speed comparing to equirectangular. In real-world indoor videos, our approach can also achieve qualitatively reasonable depth prediction by acquiring model pre-trained on PanoSUNCG.
Tactics of Adversarial Attack on Deep Reinforcement Learning Agents
May 23, 2017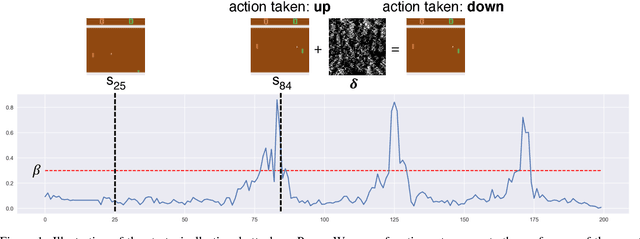
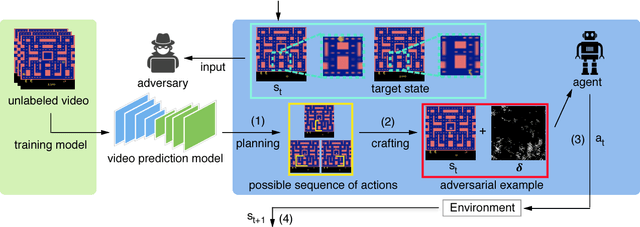

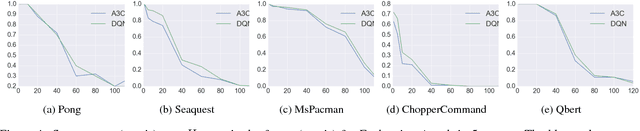
We introduce two tactics to attack agents trained by deep reinforcement learning algorithms using adversarial examples, namely the strategically-timed attack and the enchanting attack. In the strategically-timed attack, the adversary aims at minimizing the agent's reward by only attacking the agent at a small subset of time steps in an episode. Limiting the attack activity to this subset helps prevent detection of the attack by the agent. We propose a novel method to determine when an adversarial example should be crafted and applied. In the enchanting attack, the adversary aims at luring the agent to a designated target state. This is achieved by combining a generative model and a planning algorithm: while the generative model predicts the future states, the planning algorithm generates a preferred sequence of actions for luring the agent. A sequence of adversarial examples is then crafted to lure the agent to take the preferred sequence of actions. We apply the two tactics to the agents trained by the state-of-the-art deep reinforcement learning algorithm including DQN and A3C. In 5 Atari games, our strategically timed attack reduces as much reward as the uniform attack (i.e., attacking at every time step) does by attacking the agent 4 times less often. Our enchanting attack lures the agent toward designated target states with a more than 70% success rate. Videos are available at http://yclin.me/adversarial_attack_RL/