 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMengfei Du
DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning
Apr 02, 2024
Vision-and-Language navigation (VLN) requires an agent to navigate in unseen environment by following natural language instruction. For task completion, the agent needs to align and integrate various navigation modalities, including instruction, observation and navigation history. Existing works primarily concentrate on cross-modal attention at the fusion stage to achieve this objective. Nevertheless, modality features generated by disparate uni-encoders reside in their own spaces, leading to a decline in the quality of cross-modal fusion and decision. To address this problem, we propose a Dual-levEL AligNment (DELAN) framework by cross-modal contrastive learning. This framework is designed to align various navigation-related modalities before fusion, thereby enhancing cross-modal interaction and action decision-making. Specifically, we divide the pre-fusion alignment into dual levels: instruction-history level and landmark-observation level according to their semantic correlations. We also reconstruct a dual-level instruction for adaptation to the dual-level alignment. As the training signals for pre-fusion alignment are extremely limited, self-supervised contrastive learning strategies are employed to enforce the matching between different modalities. Our approach seamlessly integrates with the majority of existing models, resulting in improved navigation performance on various VLN benchmarks, including R2R, R4R, RxR and CVDN.
ReForm-Eval: Evaluating Large Vision Language Models via Unified Re-Formulation of Task-Oriented Benchmarks
Oct 17, 2023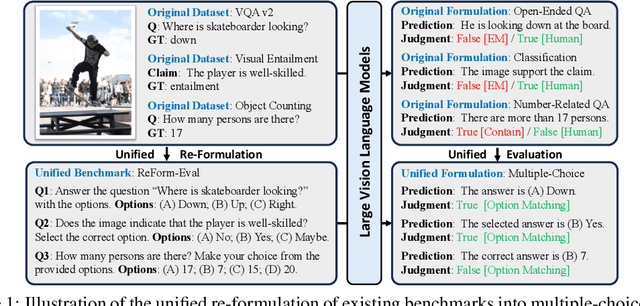



Recent years have witnessed remarkable progress in the development of large vision-language models (LVLMs). Benefiting from the strong language backbones and efficient cross-modal alignment strategies, LVLMs exhibit surprising capabilities to perceive visual signals and perform visually grounded reasoning. However, the capabilities of LVLMs have not been comprehensively and quantitatively evaluate. Most existing multi-modal benchmarks require task-oriented input-output formats, posing great challenges to automatically assess the free-form text output of LVLMs. To effectively leverage the annotations available in existing benchmarks and reduce the manual effort required for constructing new benchmarks, we propose to re-formulate existing benchmarks into unified LVLM-compatible formats. Through systematic data collection and reformulation, we present the ReForm-Eval benchmark, offering substantial data for evaluating various capabilities of LVLMs. Based on ReForm-Eval, we conduct extensive experiments, thoroughly analyze the strengths and weaknesses of existing LVLMs, and identify the underlying factors. Our benchmark and evaluation framework will be open-sourced as a cornerstone for advancing the development of LVLMs.