 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMengmi Zhang
TTA-Nav: Test-time Adaptive Reconstruction for Point-Goal Navigation under Visual Corruptions
Mar 14, 2024
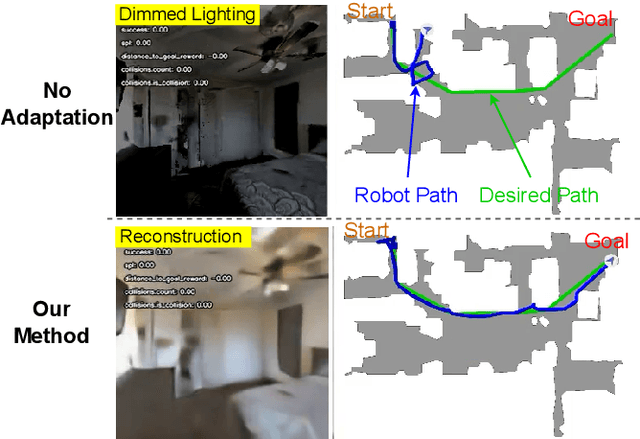
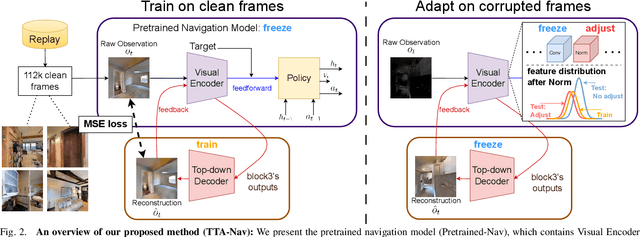


Robot navigation under visual corruption presents a formidable challenge. To address this, we propose a Test-time Adaptation (TTA) method, named as TTA-Nav, for point-goal navigation under visual corruptions. Our "plug-and-play" method incorporates a top-down decoder to a pre-trained navigation model. Firstly, the pre-trained navigation model gets a corrupted image and extracts features. Secondly, the top-down decoder produces the reconstruction given the high-level features extracted by the pre-trained model. Then, it feeds the reconstruction of a corrupted image back to the pre-trained model. Finally, the pre-trained model does forward pass again to output action. Despite being trained solely on clean images, the top-down decoder can reconstruct cleaner images from corrupted ones without the need for gradient-based adaptation. The pre-trained navigation model with our top-down decoder significantly enhances navigation performance across almost all visual corruptions in our benchmarks. Our method improves the success rate of point-goal navigation from the state-of-the-art result of 46% to 94% on the most severe corruption. This suggests its potential for broader application in robotic visual navigation. Project page: https://sites.google.com/view/tta-nav
Make Me Happier: Evoking Emotions Through Image Diffusion Models
Mar 13, 2024
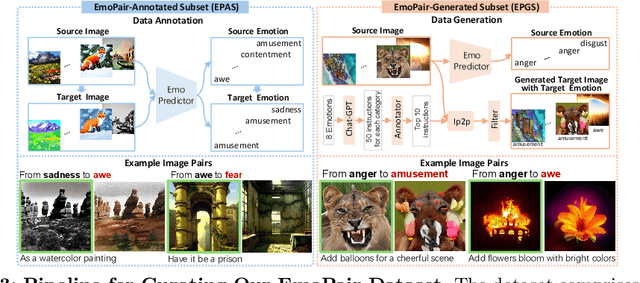
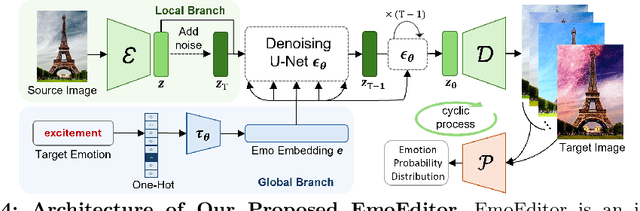
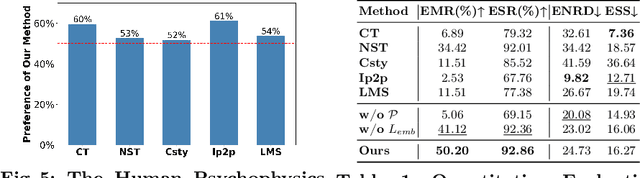
Despite the rapid progress in image generation, emotional image editing remains under-explored. The semantics, context, and structure of an image can evoke emotional responses, making emotional image editing techniques valuable for various real-world applications, including treatment of psychological disorders, commercialization of products, and artistic design. For the first time, we present a novel challenge of emotion-evoked image generation, aiming to synthesize images that evoke target emotions while retaining the semantics and structures of the original scenes. To address this challenge, we propose a diffusion model capable of effectively understanding and editing source images to convey desired emotions and sentiments. Moreover, due to the lack of emotion editing datasets, we provide a unique dataset consisting of 340,000 pairs of images and their emotion annotations. Furthermore, we conduct human psychophysics experiments and introduce four new evaluation metrics to systematically benchmark all the methods. Experimental results demonstrate that our method surpasses all competitive baselines. Our diffusion model is capable of identifying emotional cues from original images, editing images that elicit desired emotions, and meanwhile, preserving the semantic structure of the original images. All code, model, and data will be made public.
Adaptive Visual Scene Understanding: Incremental Scene Graph Generation
Oct 11, 2023

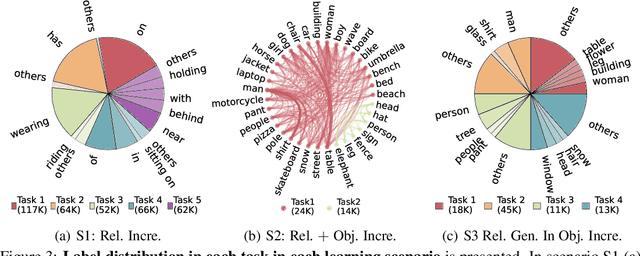
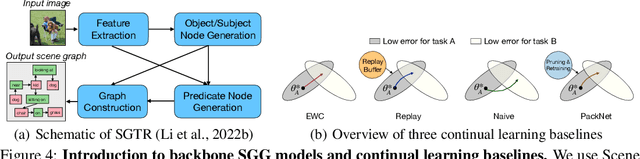
Scene graph generation (SGG) involves analyzing images to extract meaningful information about objects and their relationships. Given the dynamic nature of the visual world, it becomes crucial for AI systems to detect new objects and establish their new relationships with existing objects. To address the lack of continual learning methodologies in SGG, we introduce the comprehensive Continual ScenE Graph Generation (CSEGG) dataset along with 3 learning scenarios and 8 evaluation metrics. Our research investigates the continual learning performances of existing SGG methods on the retention of previous object entities and relationships as they learn new ones. Moreover, we also explore how continual object detection enhances generalization in classifying known relationships on unknown objects. We conduct extensive experiments benchmarking and analyzing the classical two-stage SGG methods and the most recent transformer-based SGG methods in continual learning settings, and gain valuable insights into the CSEGG problem. We invite the research community to explore this emerging field of study.
Integrating Curricula with Replays: Its Effects on Continual Learning
Jul 25, 2023
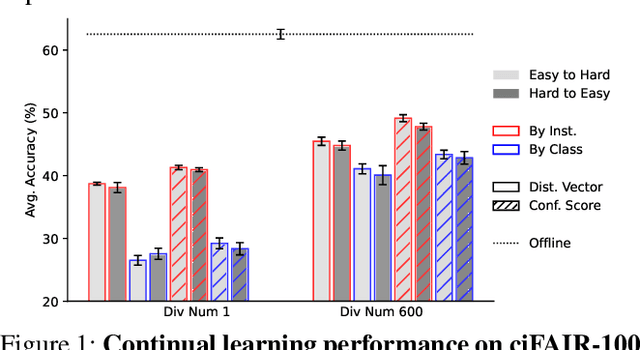
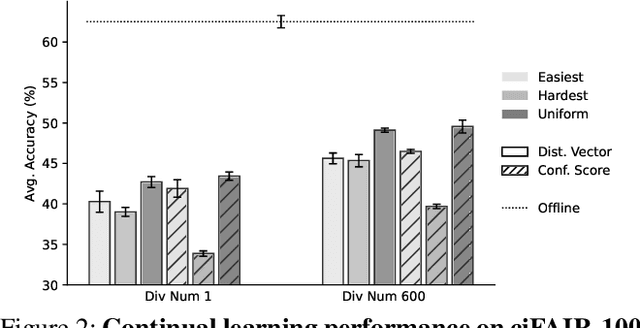
Humans engage in learning and reviewing processes with curricula when acquiring new skills or knowledge. This human learning behavior has inspired the integration of curricula with replay methods in continual learning agents. The goal is to emulate the human learning process, thereby improving knowledge retention and facilitating learning transfer. Existing replay methods in continual learning agents involve the random selection and ordering of data from previous tasks, which has shown to be effective. However, limited research has explored the integration of different curricula with replay methods to enhance continual learning. Our study takes initial steps in examining the impact of integrating curricula with replay methods on continual learning in three specific aspects: the interleaved frequency of replayed exemplars with training data, the sequence in which exemplars are replayed, and the strategy for selecting exemplars into the replay buffer. These aspects of curricula design align with cognitive psychology principles and leverage the benefits of interleaved practice during replays, easy-to-hard rehearsal, and exemplar selection strategy involving exemplars from a uniform distribution of difficulties. Based on our results, these three curricula effectively mitigated catastrophic forgetting and enhanced positive knowledge transfer, demonstrating the potential of curricula in advancing continual learning methodologies. Our code and data are available: https://github.com/ZhangLab-DeepNeuroCogLab/Integrating-Curricula-with-Replays
Decoding the Enigma: Benchmarking Humans and AIs on the Many Facets of Working Memory
Jul 20, 2023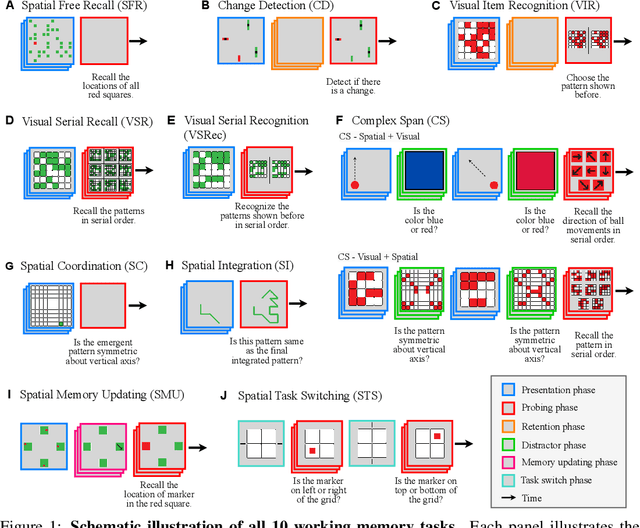
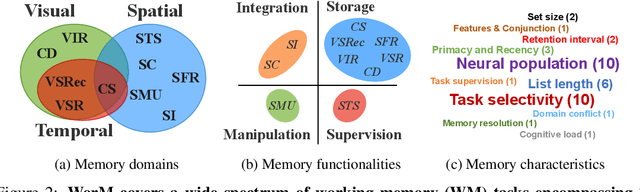
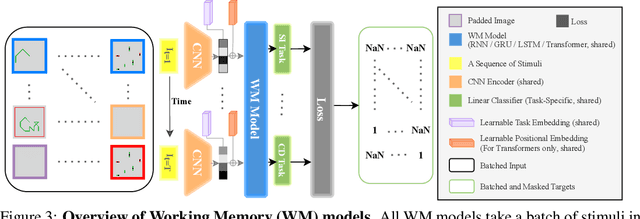

Working memory (WM), a fundamental cognitive process facilitating the temporary storage, integration, manipulation, and retrieval of information, plays a vital role in reasoning and decision-making tasks. Robust benchmark datasets that capture the multifaceted nature of WM are crucial for the effective development and evaluation of AI WM models. Here, we introduce a comprehensive Working Memory (WorM) benchmark dataset for this purpose. WorM comprises 10 tasks and a total of 1 million trials, assessing 4 functionalities, 3 domains, and 11 behavioral and neural characteristics of WM. We jointly trained and tested state-of-the-art recurrent neural networks and transformers on all these tasks. We also include human behavioral benchmarks as an upper bound for comparison. Our results suggest that AI models replicate some characteristics of WM in the brain, most notably primacy and recency effects, and neural clusters and correlates specialized for different domains and functionalities of WM. In the experiments, we also reveal some limitations in existing models to approximate human behavior. This dataset serves as a valuable resource for communities in cognitive psychology, neuroscience, and AI, offering a standardized framework to compare and enhance WM models, investigate WM's neural underpinnings, and develop WM models with human-like capabilities. Our source code and data are available at https://github.com/ZhangLab-DeepNeuroCogLab/WorM.
Training-free Object Counting with Prompts
Jun 30, 2023


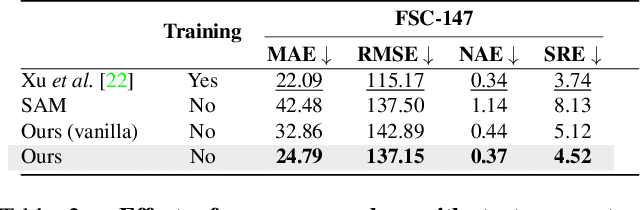
This paper tackles the problem of object counting in images. Existing approaches rely on extensive training data with point annotations for each object, making data collection labor-intensive and time-consuming. To overcome this, we propose a training-free object counter that treats the counting task as a segmentation problem. Our approach leverages the Segment Anything Model (SAM), known for its high-quality masks and zero-shot segmentation capability. However, the vanilla mask generation method of SAM lacks class-specific information in the masks, resulting in inferior counting accuracy. To overcome this limitation, we introduce a prior-guided mask generation method that incorporates three types of priors into the segmentation process, enhancing efficiency and accuracy. Additionally, we tackle the issue of counting objects specified through free-form text by proposing a two-stage approach that combines reference object selection and prior-guided mask generation. Extensive experiments on standard datasets demonstrate the competitive performance of our training-free counter compared to learning-based approaches. This paper presents a promising solution for counting objects in various scenarios without the need for extensive data collection and model training. Code is available at https://github.com/shizenglin/training-free-object-counter.
Object-centric Learning with Cyclic Walks between Parts and Whole
Feb 16, 2023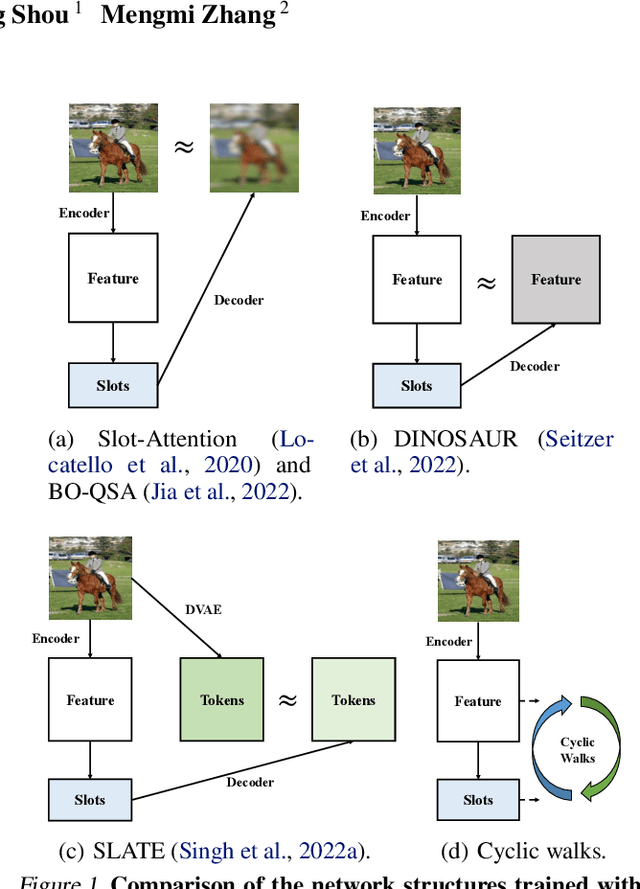
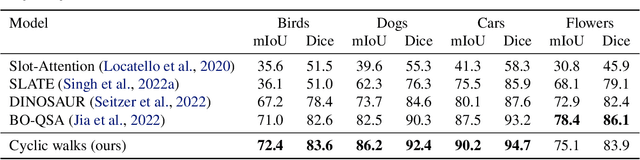
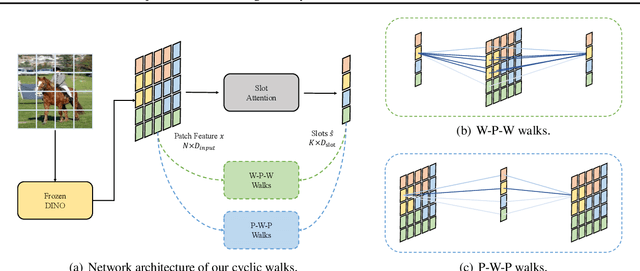
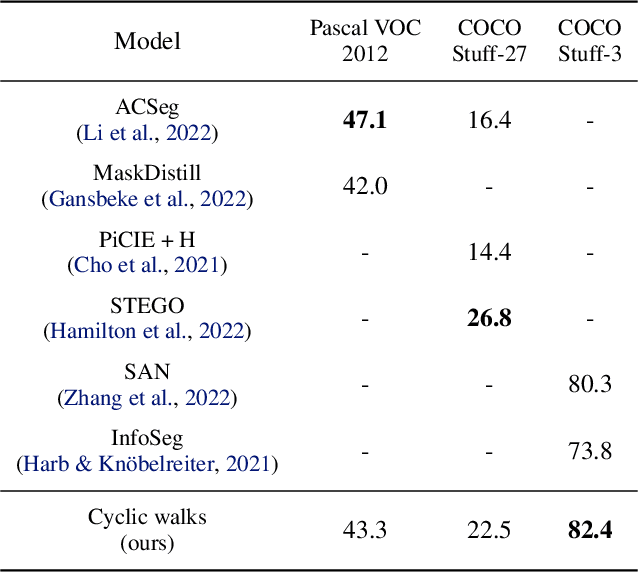
Learning object-centric representations from complex natural environments enables both humans and machines with reasoning abilities from low-level perceptual features. To capture compositional entities of the scene, we proposed cyclic walks between perceptual features extracted from CNN or transformers and object entities. First, a slot-attention module interfaces with these perceptual features and produces a finite set of slot representations. These slots can bind to any object entities in the scene via inter-slot competitions for attention. Next, we establish entity-feature correspondence with cyclic walks along high transition probability based on pairwise similarity between perceptual features (aka "parts") and slot-binded object representations (aka "whole"). The whole is greater than its parts and the parts constitute the whole. The part-whole interactions form cycle consistencies, as supervisory signals, to train the slot-attention module. We empirically demonstrate that the networks trained with our cyclic walks can extract object-centric representations on seven image datasets in three unsupervised learning tasks. In contrast to object-centric models attached with a decoder for image or feature reconstructions, our cyclic walks provide strong supervision signals, avoiding computation overheads and enhancing memory efficiency.
Learning to Learn: How to Continuously Teach Humans and Machines
Nov 28, 2022
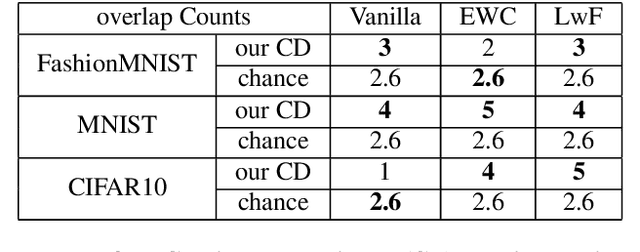
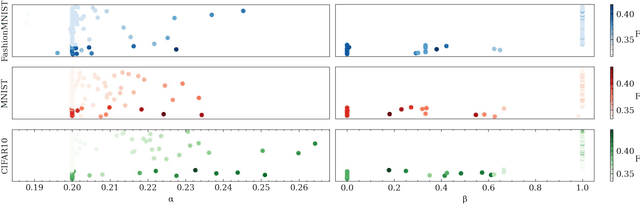
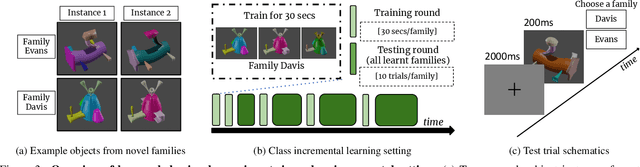
Our education system comprises a series of curricula. For example, when we learn mathematics at school, we learn in order from addition, to multiplication, and later to integration. Delineating a curriculum for teaching either a human or a machine shares the underlying goal of maximizing the positive knowledge transfer from early to later tasks and minimizing forgetting of the early tasks. Here, we exhaustively surveyed the effect of curricula on existing continual learning algorithms in the class-incremental setting, where algorithms must learn classes one at a time from a continuous stream of data. We observed that across a breadth of possible class orders (curricula), curricula influence the retention of information and that this effect is not just a product of stochasticity. Further, as a primary effort toward automated curriculum design, we proposed a method capable of designing and ranking effective curricula based on inter-class feature similarities. We compared the predicted curricula against empirically determined effectual curricula and observed significant overlaps between the two. To support the study of a curriculum designer, we conducted a series of human psychophysics experiments and contributed a new Continual Learning benchmark in object recognition. We assessed the degree of agreement in effective curricula between humans and machines. Surprisingly, our curriculum designer successfully predicts an optimal set of curricula that is effective for human learning. There are many considerations in curriculum design, such as timely student feedback and learning with multiple modalities. Our study is the first attempt to set a standard framework for the community to tackle the problem of teaching humans and machines to learn to learn continuously.
On the Robustness, Generalization, and Forgetting of Shape-Texture Debiased Continual Learning
Nov 26, 2022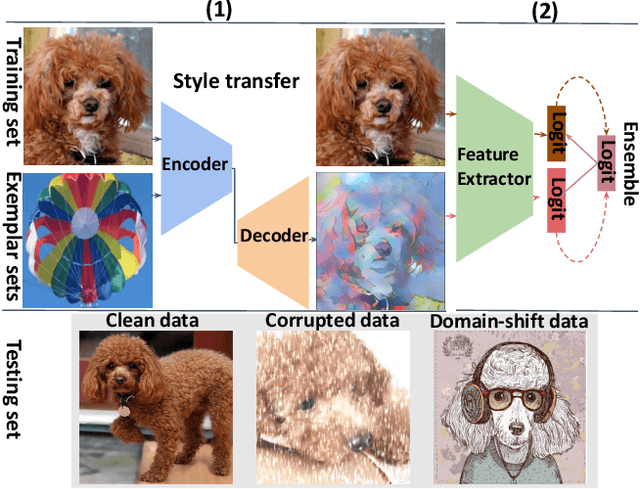
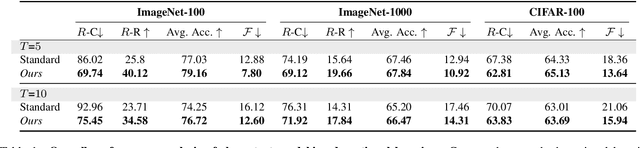
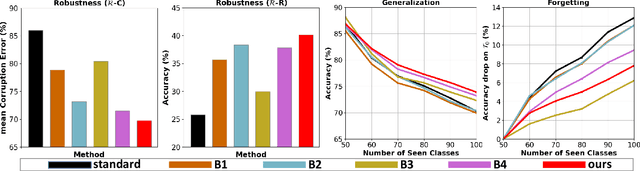

Tremendous progress has been made in continual learning to maintain good performance on old tasks when learning new tasks by tackling the catastrophic forgetting problem of neural networks. This paper advances continual learning by further considering its out-of-distribution robustness, in response to the vulnerability of continually trained models to distribution shifts (e.g., due to data corruptions and domain shifts) in inference. To this end, we propose shape-texture debiased continual learning. The key idea is to learn generalizable and robust representations for each task with shape-texture debiased training. In order to transform standard continual learning to shape-texture debiased continual learning, we propose shape-texture debiased data generation and online shape-texture debiased self-distillation. Experiments on six datasets demonstrate the benefits of our approach in improving generalization and robustness, as well as reducing forgetting. Our analysis on the flatness of the loss landscape explains the advantages. Moreover, our approach can be easily combined with new advanced architectures such as vision transformer, and applied to more challenging scenarios such as exemplar-free continual learning.
Efficient Zero-shot Visual Search via Target and Context-aware Transformer
Nov 24, 2022
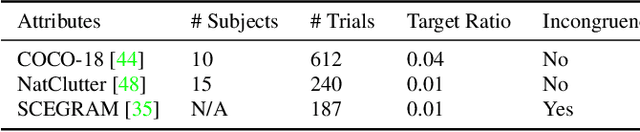
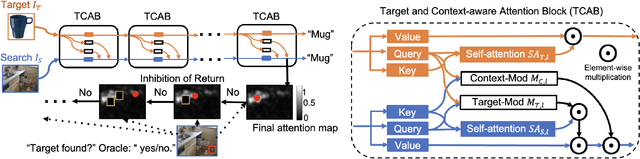
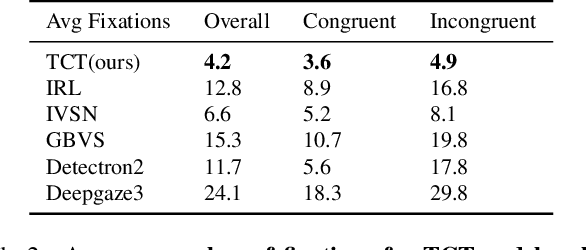
Visual search is a ubiquitous challenge in natural vision, including daily tasks such as finding a friend in a crowd or searching for a car in a parking lot. Human rely heavily on relevant target features to perform goal-directed visual search. Meanwhile, context is of critical importance for locating a target object in complex scenes as it helps narrow down the search area and makes the search process more efficient. However, few works have combined both target and context information in visual search computational models. Here we propose a zero-shot deep learning architecture, TCT (Target and Context-aware Transformer), that modulates self attention in the Vision Transformer with target and contextual relevant information to enable human-like zero-shot visual search performance. Target modulation is computed as patch-wise local relevance between the target and search images, whereas contextual modulation is applied in a global fashion. We conduct visual search experiments on TCT and other competitive visual search models on three natural scene datasets with varying levels of difficulty. TCT demonstrates human-like performance in terms of search efficiency and beats the SOTA models in challenging visual search tasks. Importantly, TCT generalizes well across datasets with novel objects without retraining or fine-tuning. Furthermore, we also introduce a new dataset to benchmark models for invariant visual search under incongruent contexts. TCT manages to search flexibly via target and context modulation, even under incongruent contexts.