 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMichael Luck
Visual Analytics for Fine-grained Text Classification Models and Datasets
Mar 21, 2024
In natural language processing (NLP), text classification tasks are increasingly fine-grained, as datasets are fragmented into a larger number of classes that are more difficult to differentiate from one another. As a consequence, the semantic structures of datasets have become more complex, and model decisions more difficult to explain. Existing tools, suited for coarse-grained classification, falter under these additional challenges. In response to this gap, we worked closely with NLP domain experts in an iterative design-and-evaluation process to characterize and tackle the growing requirements in their workflow of developing fine-grained text classification models. The result of this collaboration is the development of SemLa, a novel visual analytics system tailored for 1) dissecting complex semantic structures in a dataset when it is spatialized in model embedding space, and 2) visualizing fine-grained nuances in the meaning of text samples to faithfully explain model reasoning. This paper details the iterative design study and the resulting innovations featured in SemLa. The final design allows contrastive analysis at different levels by unearthing lexical and conceptual patterns including biases and artifacts in data. Expert feedback on our final design and case studies confirm that SemLa is a useful tool for supporting model validation and debugging as well as data annotation.
Imitation Learning Datasets: A Toolkit For Creating Datasets, Training Agents and Benchmarking
Mar 01, 2024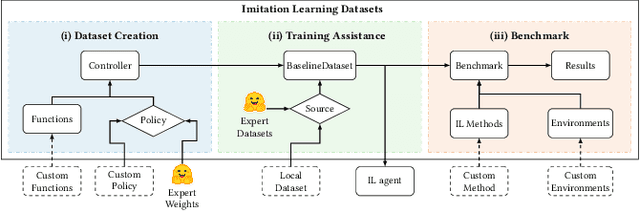
Imitation learning field requires expert data to train agents in a task. Most often, this learning approach suffers from the absence of available data, which results in techniques being tested on its dataset. Creating datasets is a cumbersome process requiring researchers to train expert agents from scratch, record their interactions and test each benchmark method with newly created data. Moreover, creating new datasets for each new technique results in a lack of consistency in the evaluation process since each dataset can drastically vary in state and action distribution. In response, this work aims to address these issues by creating Imitation Learning Datasets, a toolkit that allows for: (i) curated expert policies with multithreaded support for faster dataset creation; (ii) readily available datasets and techniques with precise measurements; and (iii) sharing implementations of common imitation learning techniques. Demonstration link: https://nathangavenski.github.io/#/il-datasets-video
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Dec 20, 2023The advancement of natural language processing (NLP) has been significantly boosted by the development of transformer-based large language models (LLMs). These models have revolutionized NLP tasks, particularly in code generation, aiding developers in creating software with enhanced efficiency. Despite their advancements, challenges in balancing code snippet generation with effective test case generation and execution persist. To address these issues, this paper introduces Multi-Agent Assistant Code Generation (AgentCoder), a novel solution comprising a multi-agent framework with specialized agents: the programmer agent, the test designer agent, and the test executor agent. During the coding procedure, the programmer agent will focus on the code generation and refinement based on the test executor agent's feedback. The test designer agent will generate test cases for the generated code, and the test executor agent will run the code with the test cases and write the feedback to the programmer. This collaborative system ensures robust code generation, surpassing the limitations of single-agent models and traditional methodologies. Our extensive experiments on 9 code generation models and 12 enhancement approaches showcase AgentCoder's superior performance over existing code generation models and prompt engineering techniques across various benchmarks. For example, AgentCoder achieves 77.4% and 89.1% pass@1 in HumanEval-ET and MBPP-ET with GPT-3.5, while SOTA baselines obtain only 69.5% and 63.0%.
Collaborative filtering to capture AI user's preferences as norms
Aug 10, 2023Customising AI technologies to each user's preferences is fundamental to them functioning well. Unfortunately, current methods require too much user involvement and fail to capture their true preferences. In fact, to avoid the nuisance of manually setting preferences, users usually accept the default settings even if these do not conform to their true preferences. Norms can be useful to regulate behaviour and ensure it adheres to user preferences but, while the literature has thoroughly studied norms, most proposals take a formal perspective. Indeed, while there has been some research on constructing norms to capture a user's privacy preferences, these methods rely on domain knowledge which, in the case of AI technologies, is difficult to obtain and maintain. We argue that a new perspective is required when constructing norms, which is to exploit the large amount of preference information readily available from whole systems of users. Inspired by recommender systems, we believe that collaborative filtering can offer a suitable approach to identifying a user's norm preferences without excessive user involvement.
Predicting Privacy Preferences for Smart Devices as Norms
Feb 21, 2023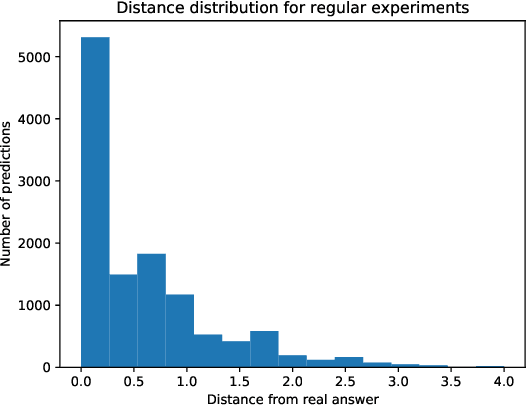


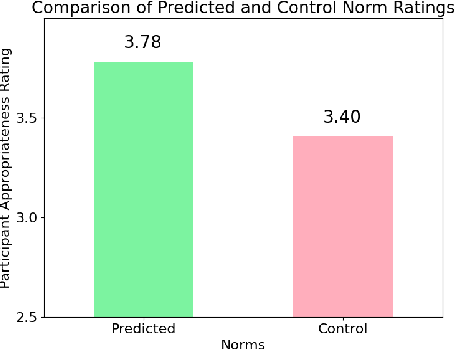
Smart devices, such as smart speakers, are becoming ubiquitous, and users expect these devices to act in accordance with their preferences. In particular, since these devices gather and manage personal data, users expect them to adhere to their privacy preferences. However, the current approach of gathering these preferences consists in asking the users directly, which usually triggers automatic responses failing to capture their true preferences. In response, in this paper we present a collaborative filtering approach to predict user preferences as norms. These preference predictions can be readily adopted or can serve to assist users in determining their own preferences. Using a dataset of privacy preferences of smart assistant users, we test the accuracy of our predictions.