 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMichael S. Ryoo
Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs
Apr 11, 2024
Integration of Large Language Models (LLMs) into visual domain tasks, resulting in visual-LLMs (V-LLMs), has enabled exceptional performance in vision-language tasks, particularly for visual question answering (VQA). However, existing V-LLMs (e.g. BLIP-2, LLaVA) demonstrate weak spatial reasoning and localization awareness. Despite generating highly descriptive and elaborate textual answers, these models fail at simple tasks like distinguishing a left vs right location. In this work, we explore how image-space coordinate based instruction fine-tuning objectives could inject spatial awareness into V-LLMs. We discover optimal coordinate representations, data-efficient instruction fine-tuning objectives, and pseudo-data generation strategies that lead to improved spatial awareness in V-LLMs. Additionally, our resulting model improves VQA across image and video domains, reduces undesired hallucination, and generates better contextual object descriptions. Experiments across 5 vision-language tasks involving 14 different datasets establish the clear performance improvements achieved by our proposed framework.
Understanding Long Videos in One Multimodal Language Model Pass
Mar 25, 2024Large Language Models (LLMs), known to contain a strong awareness of world knowledge, have allowed recent approaches to achieve excellent performance on Long-Video Understanding benchmarks, but at high inference costs. In this work, we first propose Likelihood Selection, a simple technique that unlocks faster inference in autoregressive LLMs for multiple-choice tasks common in long-video benchmarks. In addition to faster inference, we discover the resulting models to yield surprisingly good accuracy on long-video tasks, even with no video specific information. Building on this, we inject video-specific object-centric information extracted from off-the-shelf pre-trained models and utilize natural language as a medium for information fusion. Our resulting Multimodal Video Understanding (MVU) framework demonstrates state-of-the-art performance across long-video and fine-grained action recognition benchmarks. Code available at: https://github.com/kahnchana/mvu
Language Repository for Long Video Understanding
Mar 21, 2024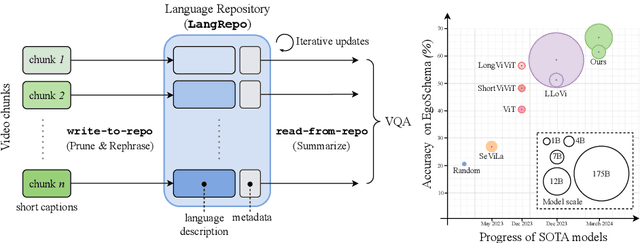
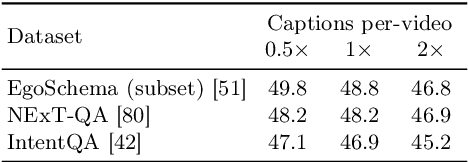
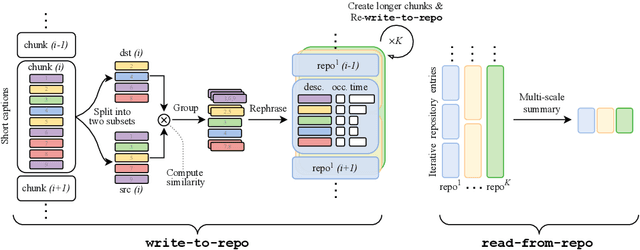
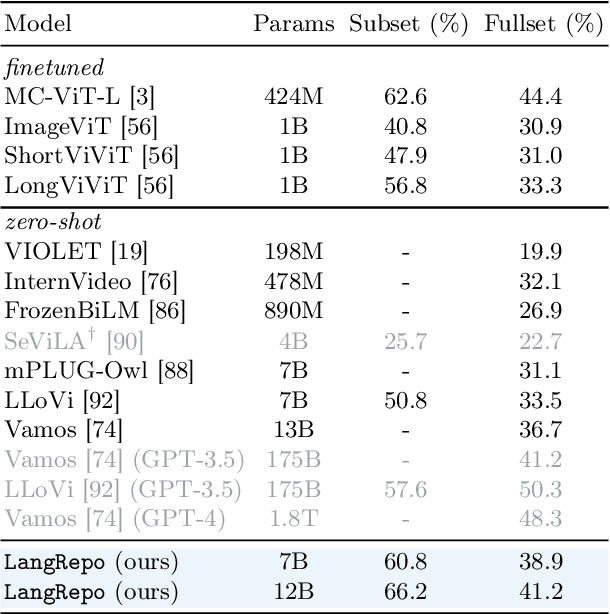
Language has become a prominent modality in computer vision with the rise of multi-modal LLMs. Despite supporting long context-lengths, their effectiveness in handling long-term information gradually declines with input length. This becomes critical, especially in applications such as long-form video understanding. In this paper, we introduce a Language Repository (LangRepo) for LLMs, that maintains concise and structured information as an interpretable (i.e., all-textual) representation. Our repository is updated iteratively based on multi-scale video chunks. We introduce write and read operations that focus on pruning redundancies in text, and extracting information at various temporal scales. The proposed framework is evaluated on zero-shot visual question-answering benchmarks including EgoSchema, NExT-QA, IntentQA and NExT-GQA, showing state-of-the-art performance at its scale. Our code is available at https://github.com/kkahatapitiya/LangRepo.
Diffusion Illusions: Hiding Images in Plain Sight
Dec 06, 2023


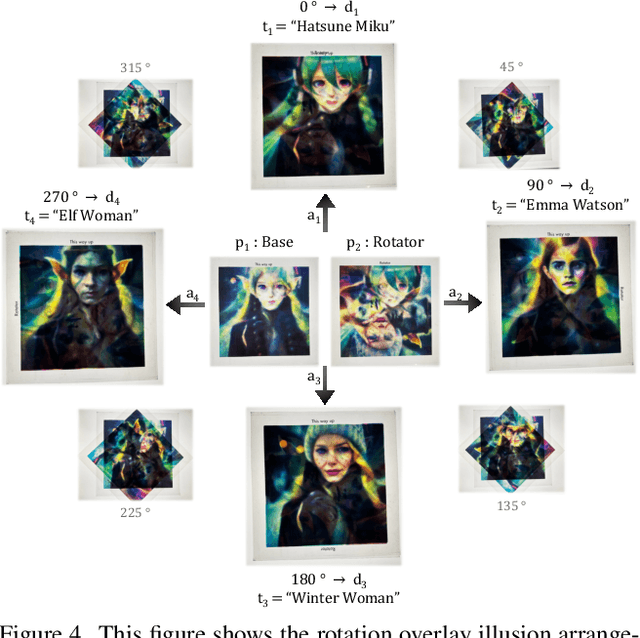
We explore the problem of computationally generating special `prime' images that produce optical illusions when physically arranged and viewed in a certain way. First, we propose a formal definition for this problem. Next, we introduce Diffusion Illusions, the first comprehensive pipeline designed to automatically generate a wide range of these illusions. Specifically, we both adapt the existing `score distillation loss' and propose a new `dream target loss' to optimize a group of differentially parametrized prime images, using a frozen text-to-image diffusion model. We study three types of illusions, each where the prime images are arranged in different ways and optimized using the aforementioned losses such that images derived from them align with user-chosen text prompts or images. We conduct comprehensive experiments on these illusions and verify the effectiveness of our proposed method qualitatively and quantitatively. Additionally, we showcase the successful physical fabrication of our illusions -- as they are all designed to work in the real world. Our code and examples are publicly available at our interactive project website: https://diffusionillusions.com
Mirasol3B: A Multimodal Autoregressive model for time-aligned and contextual modalities
Nov 13, 2023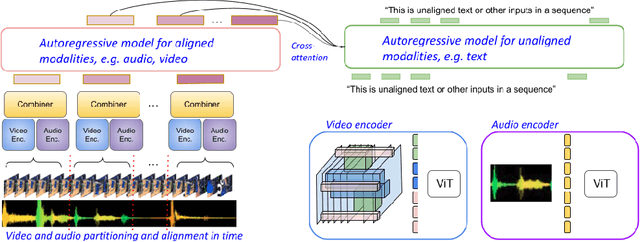
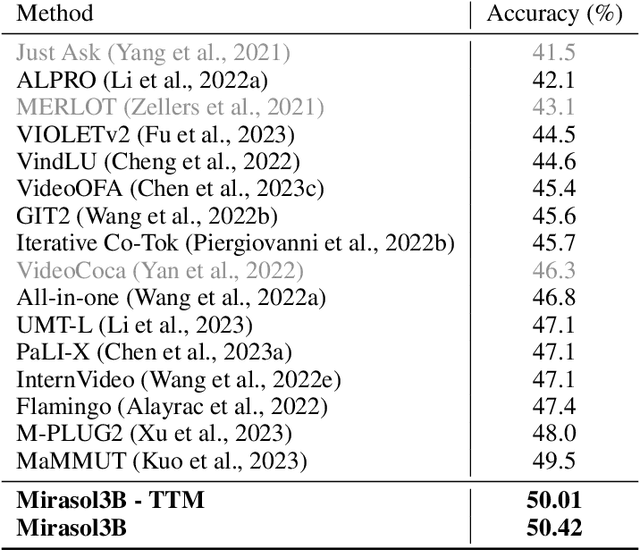
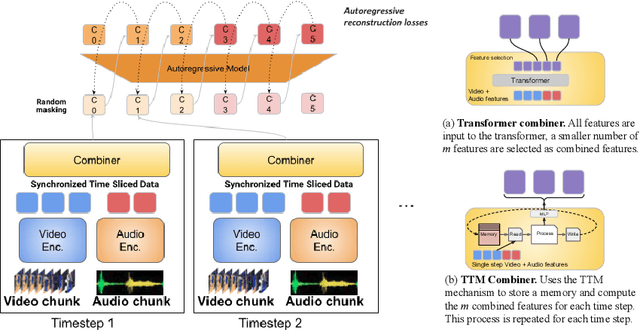

One of the main challenges of multimodal learning is the need to combine heterogeneous modalities (e.g., video, audio, text). For example, video and audio are obtained at much higher rates than text and are roughly aligned in time. They are often not synchronized with text, which comes as a global context, e.g., a title, or a description. Furthermore, video and audio inputs are of much larger volumes, and grow as the video length increases, which naturally requires more compute dedicated to these modalities and makes modeling of long-range dependencies harder. We here decouple the multimodal modeling, dividing it into separate, focused autoregressive models, processing the inputs according to the characteristics of the modalities. We propose a multimodal model, called Mirasol3B, consisting of an autoregressive component for the time-synchronized modalities (audio and video), and an autoregressive component for the context modalities which are not necessarily aligned in time but are still sequential. To address the long-sequences of the video-audio inputs, we propose to further partition the video and audio sequences in consecutive snippets and autoregressively process their representations. To that end, we propose a Combiner mechanism, which models the audio-video information jointly within a timeframe. The Combiner learns to extract audio and video features from raw spatio-temporal signals, and then learns to fuse these features producing compact but expressive representations per snippet. Our approach achieves the state-of-the-art on well established multimodal benchmarks, outperforming much larger models. It effectively addresses the high computational demand of media inputs by both learning compact representations, controlling the sequence length of the audio-video feature representations, and modeling their dependencies in time.
AAN: Attributes-Aware Network for Temporal Action Detection
Sep 01, 2023


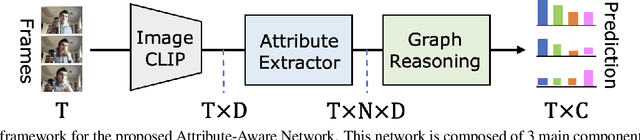
The challenge of long-term video understanding remains constrained by the efficient extraction of object semantics and the modelling of their relationships for downstream tasks. Although the CLIP visual features exhibit discriminative properties for various vision tasks, particularly in object encoding, they are suboptimal for long-term video understanding. To address this issue, we present the Attributes-Aware Network (AAN), which consists of two key components: the Attributes Extractor and a Graph Reasoning block. These components facilitate the extraction of object-centric attributes and the modelling of their relationships within the video. By leveraging CLIP features, AAN outperforms state-of-the-art approaches on two popular action detection datasets: Charades and Toyota Smarthome Untrimmed datasets.
Crossway Diffusion: Improving Diffusion-based Visuomotor Policy via Self-supervised Learning
Jul 04, 2023

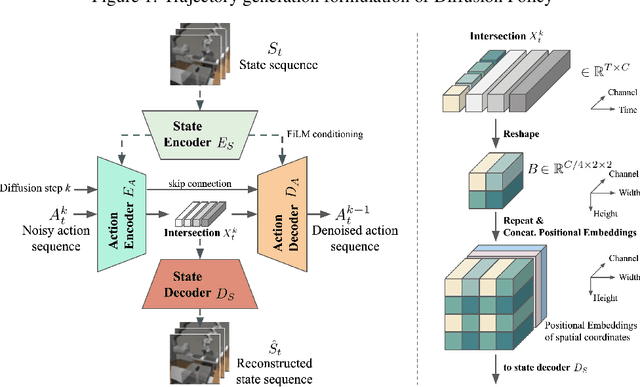

Sequence modeling approaches have shown promising results in robot imitation learning. Recently, diffusion models have been adopted for behavioral cloning, benefiting from their exceptional capabilities in modeling complex data distribution. In this work, we propose Crossway Diffusion, a method to enhance diffusion-based visuomotor policy learning by using an extra self-supervised learning (SSL) objective. The standard diffusion-based policy generates action sequences from random noise conditioned on visual observations and other low-dimensional states. We further extend this by introducing a new decoder that reconstructs raw image pixels (and other state information) from the intermediate representations of the reverse diffusion process, and train the model jointly using the SSL loss. Our experiments demonstrate the effectiveness of Crossway Diffusion in various simulated and real-world robot tasks, confirming its advantages over the standard diffusion-based policy. We demonstrate that such self-supervised reconstruction enables better representation for policy learning, especially when the demonstrations have different proficiencies.
Energy-Based Models for Cross-Modal Localization using Convolutional Transformers
Jun 06, 2023

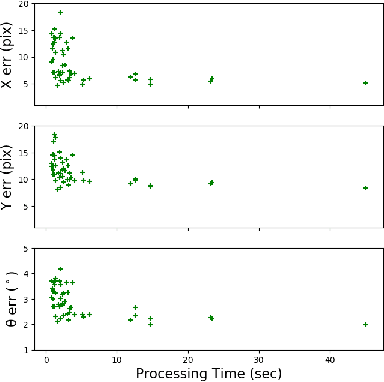

We present a novel framework using Energy-Based Models (EBMs) for localizing a ground vehicle mounted with a range sensor against satellite imagery in the absence of GPS. Lidar sensors have become ubiquitous on autonomous vehicles for describing its surrounding environment. Map priors are typically built using the same sensor modality for localization purposes. However, these map building endeavors using range sensors are often expensive and time-consuming. Alternatively, we leverage the use of satellite images as map priors, which are widely available, easily accessible, and provide comprehensive coverage. We propose a method using convolutional transformers that performs accurate metric-level localization in a cross-modal manner, which is challenging due to the drastic difference in appearance between the sparse range sensor readings and the rich satellite imagery. We train our model end-to-end and demonstrate our approach achieving higher accuracy than the state-of-the-art on KITTI, Pandaset, and a custom dataset.
Active Reinforcement Learning under Limited Visual Observability
Jun 01, 2023


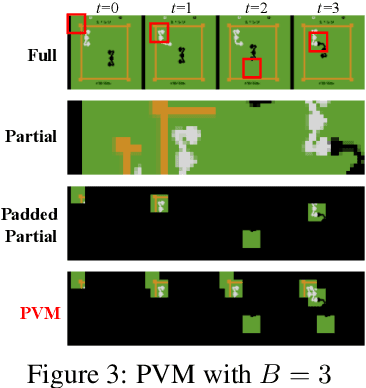
In this work, we investigate Active Reinforcement Learning (Active-RL), where an embodied agent simultaneously learns action policy for the task while also controlling its visual observations in partially observable environments. We denote the former as motor policy and the latter as sensory policy. For example, humans solve real world tasks by hand manipulation (motor policy) together with eye movements (sensory policy). Active-RL poses challenges on coordinating two policies given their mutual influence. We propose SUGARL, Sensorimotor Understanding Guided Active Reinforcement Learning, a framework that models motor and sensory policies separately, but jointly learns them using with an intrinsic sensorimotor reward. This learnable reward is assigned by sensorimotor reward module, incentivizes the sensory policy to select observations that are optimal to infer its own motor action, inspired by the sensorimotor stage of humans. Through a series of experiments, we show the effectiveness of our method across a range of observability conditions and its adaptability to existed RL algorithms. The sensory policies learned through our method are observed to exhibit effective active vision strategies.
VicTR: Video-conditioned Text Representations for Activity Recognition
Apr 05, 2023
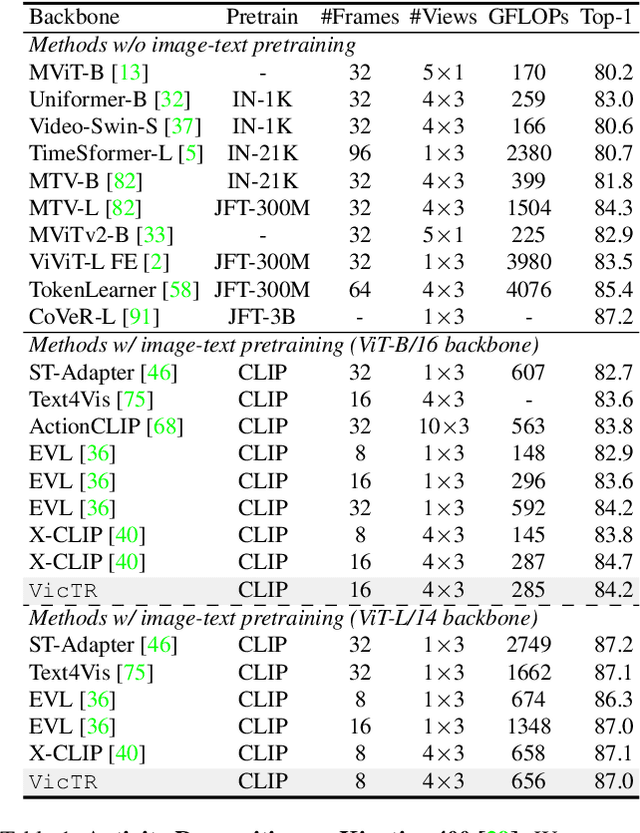

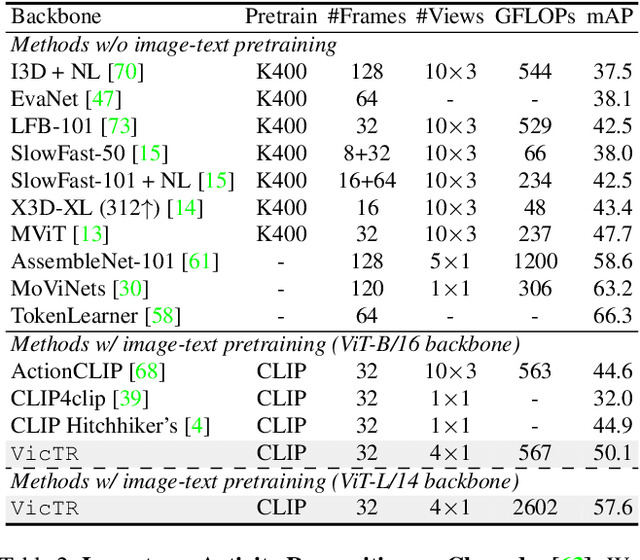
Vision-Language models have shown strong performance in the image-domain -- even in zero-shot settings, thanks to the availability of large amount of pretraining data (i.e., paired image-text examples). However for videos, such paired data is not as abundant. Thus, video-text models are usually designed by adapting pretrained image-text models to video-domain, instead of training from scratch. All such recipes rely on augmenting visual embeddings with temporal information (i.e., image -> video), often keeping text embeddings unchanged or even being discarded. In this paper, we argue that such adapted video-text models can benefit more by augmenting text rather than visual information. We propose VicTR, which jointly-optimizes text and video tokens, generating 'Video-conditioned Text' embeddings. Our method can further make use of freely-available semantic information, in the form of visually-grounded auxiliary text (e.g., object or scene information). We conduct experiments on multiple benchmarks including supervised (Kinetics-400, Charades), zero-shot and few-shot (HMDB-51, UCF-101) settings, showing competitive performance on activity recognition based on video-text models.