 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMichael Wand
Spreads in Effective Learning Rates: The Perils of Batch Normalization During Early Training
Jun 01, 2023
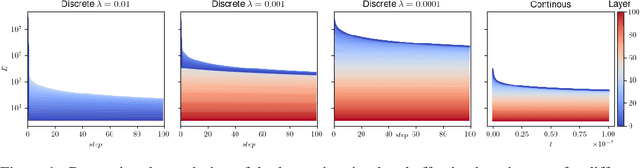
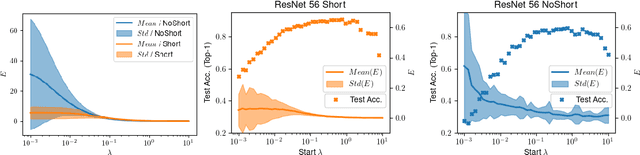


Excursions in gradient magnitude pose a persistent challenge when training deep networks. In this paper, we study the early training phases of deep normalized ReLU networks, accounting for the induced scale invariance by examining effective learning rates (LRs). Starting with the well-known fact that batch normalization (BN) leads to exponentially exploding gradients at initialization, we develop an ODE-based model to describe early training dynamics. Our model predicts that in the gradient flow, effective LRs will eventually equalize, aligning with empirical findings on warm-up training. Using large LRs is analogous to applying an explicit solver to a stiff non-linear ODE, causing overshooting and vanishing gradients in lower layers after the first step. Achieving overall balance demands careful tuning of LRs, depth, and (optionally) momentum. Our model predicts the formation of spreads in effective LRs, consistent with empirical measurements. Moreover, we observe that large spreads in effective LRs result in training issues concerning accuracy, indicating the importance of controlling these dynamics. To further support a causal relationship, we implement a simple scheduling scheme prescribing uniform effective LRs across layers and confirm accuracy benefits.
Nonlinearities in Steerable SO(2)-Equivariant CNNs
Sep 14, 2021


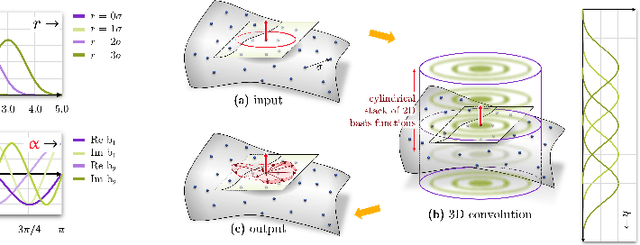
Invariance under symmetry is an important problem in machine learning. Our paper looks specifically at equivariant neural networks where transformations of inputs yield homomorphic transformations of outputs. Here, steerable CNNs have emerged as the standard solution. An inherent problem of steerable representations is that general nonlinear layers break equivariance, thus restricting architectural choices. Our paper applies harmonic distortion analysis to illuminate the effect of nonlinearities on Fourier representations of SO(2). We develop a novel FFT-based algorithm for computing representations of non-linearly transformed activations while maintaining band-limitation. It yields exact equivariance for polynomial (approximations of) nonlinearities, as well as approximate solutions with tunable accuracy for general functions. We apply the approach to build a fully E(3)-equivariant network for sampled 3D surface data. In experiments with 2D and 3D data, we obtain results that compare favorably to the state-of-the-art in terms of accuracy while permitting continuous symmetry and exact equivariance.
Deep Non-Line-of-Sight Reconstruction
Jan 29, 2020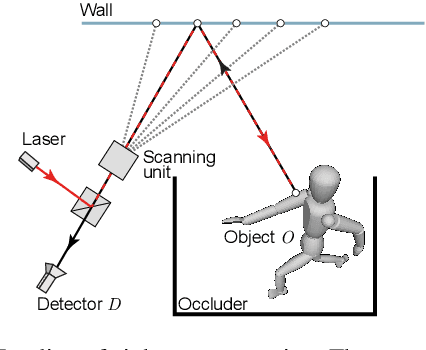
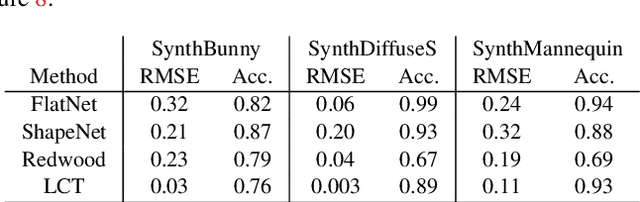
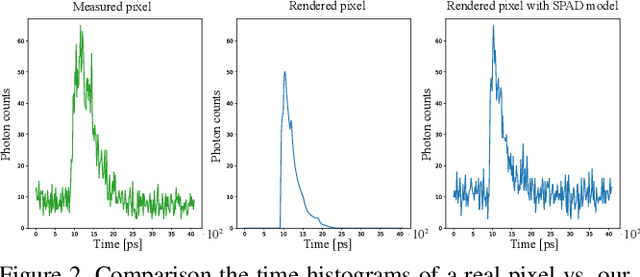
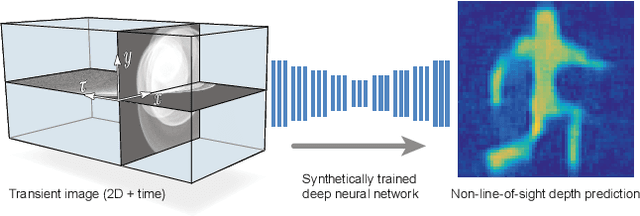
The recent years have seen a surge of interest in methods for imaging beyond the direct line of sight. The most prominent techniques rely on time-resolved optical impulse responses, obtained by illuminating a diffuse wall with an ultrashort light pulse and observing multi-bounce indirect reflections with an ultrafast time-resolved imager. Reconstruction of geometry from such data, however, is a complex non-linear inverse problem that comes with substantial computational demands. In this paper, we employ convolutional feed-forward networks for solving the reconstruction problem efficiently while maintaining good reconstruction quality. Specifically, we devise a tailored autoencoder architecture, trained end-to-end, that maps transient images directly to a depth map representation. Training is done using an efficient transient renderer for diffuse three-bounce indirect light transport that enables the quick generation of large amounts of training data for the network. We examine the performance of our method on a variety of synthetic and experimental datasets and its dependency on the choice of training data and augmentation strategies, as well as architectural features. We demonstrate that our feed-forward network, even though it is trained solely on synthetic data, generalizes to measured data from SPAD sensors and is able to obtain results that are competitive with model-based reconstruction methods.
Progressive Stochastic Binarization of Deep Networks
Apr 03, 2019
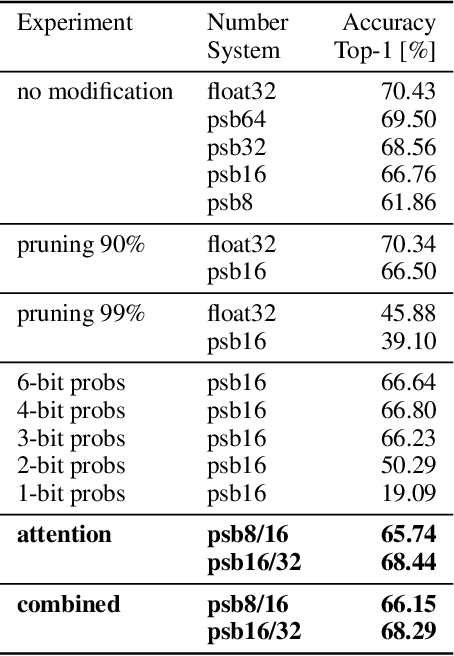
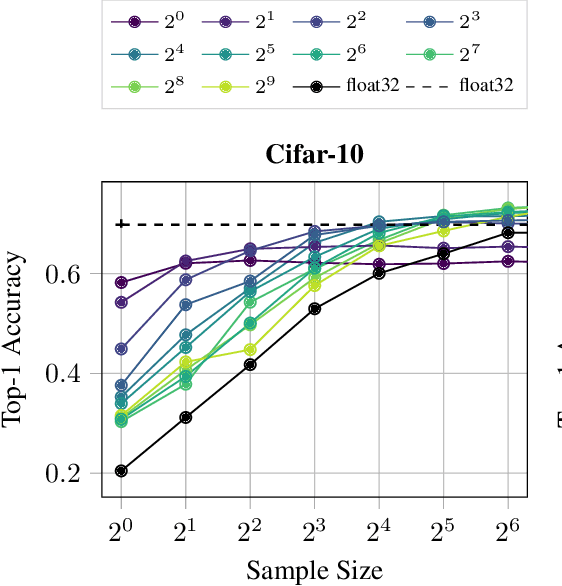
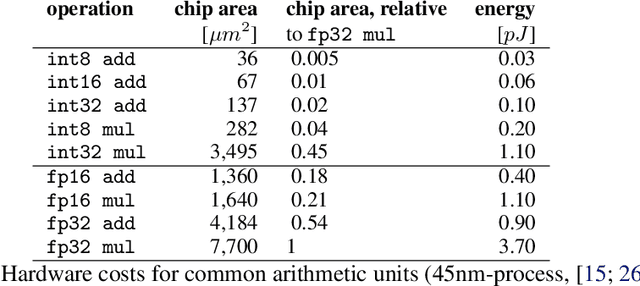
A plethora of recent research has focused on improving the memory footprint and inference speed of deep networks by reducing the complexity of (i) numerical representations (for example, by deterministic or stochastic quantization) and (ii) arithmetic operations (for example, by binarization of weights). We propose a stochastic binarization scheme for deep networks that allows for efficient inference on hardware by restricting itself to additions of small integers and fixed shifts. Unlike previous approaches, the underlying randomized approximation is progressive, thus permitting an adaptive control of the accuracy of each operation at run-time. In a low-precision setting, we match the accuracy of previous binarized approaches. Our representation is unbiased - it approaches continuous computation with increasing sample size. In a high-precision regime, the computational costs are competitive with previous quantization schemes. Progressive stochastic binarization also permits localized, dynamic accuracy control within a single network, thereby providing a new tool for adaptively focusing computational attention. We evaluate our method on networks of various architectures, already pretrained on ImageNet. With representational costs comparable to previous schemes, we obtain accuracies close to the original floating point implementation. This includes pruned networks, except the known special case of certain types of separated convolutions. By focusing computational attention using progressive sampling, we reduce inference costs on ImageNet further by a factor of up to 33% (before network pruning).
Investigations on End-to-End Audiovisual Fusion
Apr 30, 2018
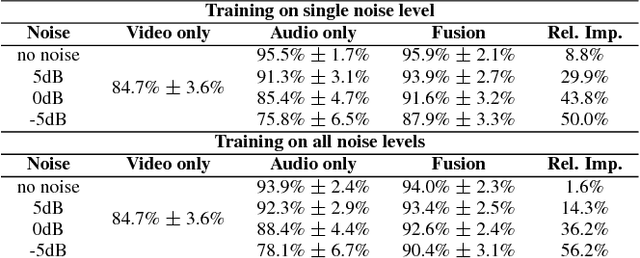
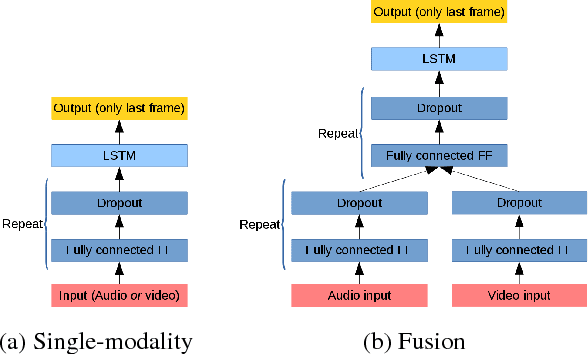

Audiovisual speech recognition (AVSR) is a method to alleviate the adverse effect of noise in the acoustic signal. Leveraging recent developments in deep neural network-based speech recognition, we present an AVSR neural network architecture which is trained end-to-end, without the need to separately model the process of decision fusion as in conventional (e.g. HMM-based) systems. The fusion system outperforms single-modality recognition under all noise conditions. Investigation of the saliency of the input features shows that the neural network automatically adapts to different noise levels in the acoustic signal.
* Published at ICASSP 2018
Improving Speaker-Independent Lipreading with Domain-Adversarial Training
Aug 04, 2017
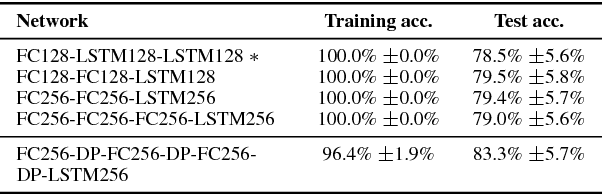
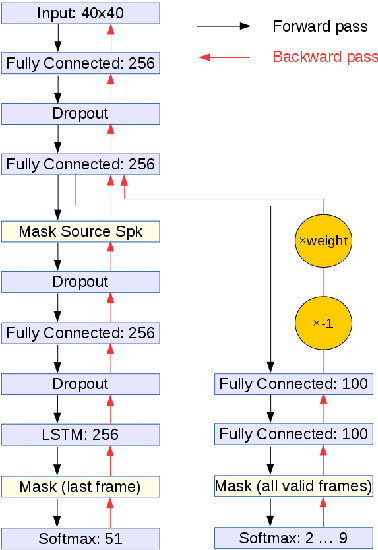
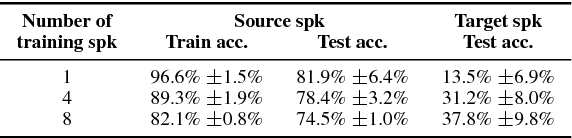
We present a Lipreading system, i.e. a speech recognition system using only visual features, which uses domain-adversarial training for speaker independence. Domain-adversarial training is integrated into the optimization of a lipreader based on a stack of feedforward and LSTM (Long Short-Term Memory) recurrent neural networks, yielding an end-to-end trainable system which only requires a very small number of frames of untranscribed target data to substantially improve the recognition accuracy on the target speaker. On pairs of different source and target speakers, we achieve a relative accuracy improvement of around 40% with only 15 to 20 seconds of untranscribed target speech data. On multi-speaker training setups, the accuracy improvements are smaller but still substantial.
Precomputed Real-Time Texture Synthesis with Markovian Generative Adversarial Networks
Apr 15, 2016
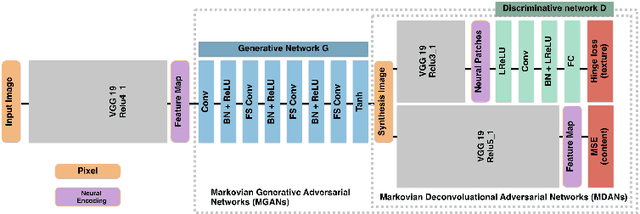


This paper proposes Markovian Generative Adversarial Networks (MGANs), a method for training generative neural networks for efficient texture synthesis. While deep neural network approaches have recently demonstrated remarkable results in terms of synthesis quality, they still come at considerable computational costs (minutes of run-time for low-res images). Our paper addresses this efficiency issue. Instead of a numerical deconvolution in previous work, we precompute a feed-forward, strided convolutional network that captures the feature statistics of Markovian patches and is able to directly generate outputs of arbitrary dimensions. Such network can directly decode brown noise to realistic texture, or photos to artistic paintings. With adversarial training, we obtain quality comparable to recent neural texture synthesis methods. As no optimization is required any longer at generation time, our run-time performance (0.25M pixel images at 25Hz) surpasses previous neural texture synthesizers by a significant margin (at least 500 times faster). We apply this idea to texture synthesis, style transfer, and video stylization.
Lipreading with Long Short-Term Memory
Jan 29, 2016
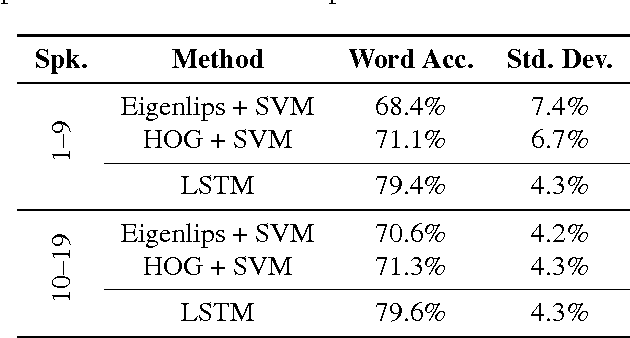
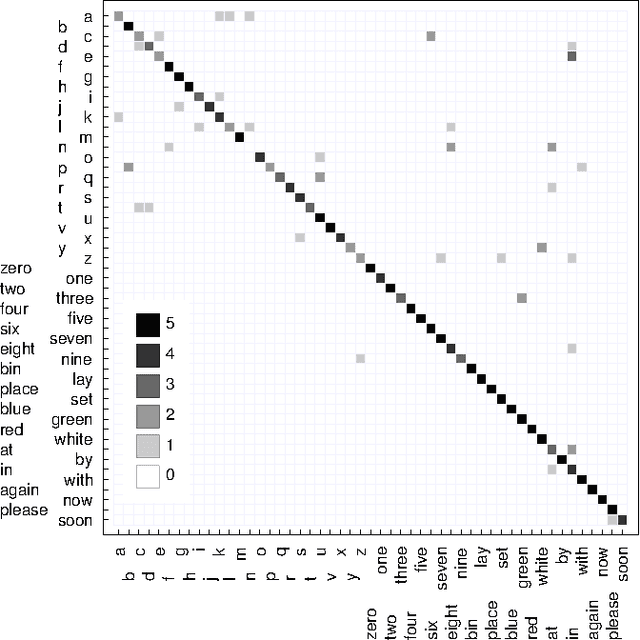
Lipreading, i.e. speech recognition from visual-only recordings of a speaker's face, can be achieved with a processing pipeline based solely on neural networks, yielding significantly better accuracy than conventional methods. Feed-forward and recurrent neural network layers (namely Long Short-Term Memory; LSTM) are stacked to form a single structure which is trained by back-propagating error gradients through all the layers. The performance of such a stacked network was experimentally evaluated and compared to a standard Support Vector Machine classifier using conventional computer vision features (Eigenlips and Histograms of Oriented Gradients). The evaluation was performed on data from 19 speakers of the publicly available GRID corpus. With 51 different words to classify, we report a best word accuracy on held-out evaluation speakers of 79.6% using the end-to-end neural network-based solution (11.6% improvement over the best feature-based solution evaluated).
Combining Markov Random Fields and Convolutional Neural Networks for Image Synthesis
Jan 18, 2016



This paper studies a combination of generative Markov random field (MRF) models and discriminatively trained deep convolutional neural networks (dCNNs) for synthesizing 2D images. The generative MRF acts on higher-levels of a dCNN feature pyramid, controling the image layout at an abstract level. We apply the method to both photographic and non-photo-realistic (artwork) synthesis tasks. The MRF regularizer prevents over-excitation artifacts and reduces implausible feature mixtures common to previous dCNN inversion approaches, permitting synthezing photographic content with increased visual plausibility. Unlike standard MRF-based texture synthesis, the combined system can both match and adapt local features with considerable variability, yielding results far out of reach of classic generative MRF methods.
A Low-Dimensional Representation for Robust Partial Isometric Correspondences Computation
Jan 13, 2014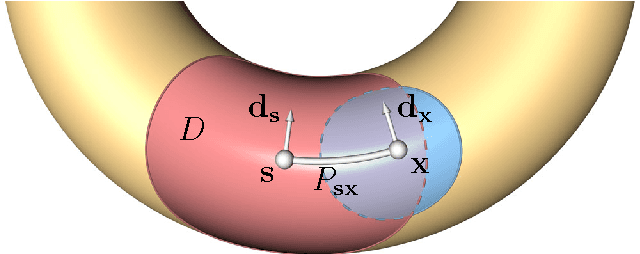
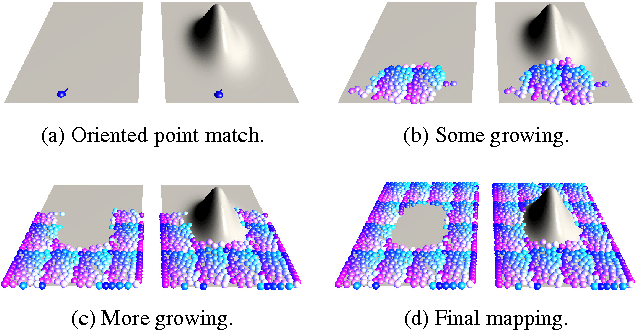
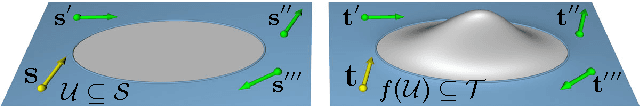
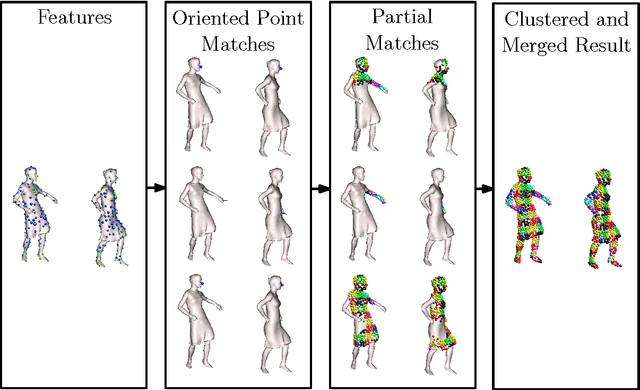
Intrinsic isometric shape matching has become the standard approach for pose invariant correspondence estimation among deformable shapes. Most existing approaches assume global consistency, i.e., the metric structure of the whole manifold must not change significantly. While global isometric matching is well understood, only a few heuristic solutions are known for partial matching. Partial matching is particularly important for robustness to topological noise (incomplete data and contacts), which is a common problem in real-world 3D scanner data. In this paper, we introduce a new approach to partial, intrinsic isometric matching. Our method is based on the observation that isometries are fully determined by purely local information: a map of a single point and its tangent space fixes an isometry for both global and the partial maps. From this idea, we develop a new representation for partial isometric maps based on equivalence classes of correspondences between pairs of points and their tangent spaces. From this, we derive a local propagation algorithm that find such mappings efficiently. In contrast to previous heuristics based on RANSAC or expectation maximization, our method is based on a simple and sound theoretical model and fully deterministic. We apply our approach to register partial point clouds and compare it to the state-of-the-art methods, where we obtain significant improvements over global methods for real-world data and stronger guarantees than previous heuristic partial matching algorithms.
* 17 pages, 12 figures