 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMilad Aghajohari
LOQA: Learning with Opponent Q-Learning Awareness
May 02, 2024
In various real-world scenarios, interactions among agents often resemble the dynamics of general-sum games, where each agent strives to optimize its own utility. Despite the ubiquitous relevance of such settings, decentralized machine learning algorithms have struggled to find equilibria that maximize individual utility while preserving social welfare. In this paper we introduce Learning with Opponent Q-Learning Awareness (LOQA), a novel, decentralized reinforcement learning algorithm tailored to optimizing an agent's individual utility while fostering cooperation among adversaries in partially competitive environments. LOQA assumes the opponent samples actions proportionally to their action-value function Q. Experimental results demonstrate the effectiveness of LOQA at achieving state-of-the-art performance in benchmark scenarios such as the Iterated Prisoner's Dilemma and the Coin Game. LOQA achieves these outcomes with a significantly reduced computational footprint, making it a promising approach for practical multi-agent applications.
Best Response Shaping
Apr 05, 2024We investigate the challenge of multi-agent deep reinforcement learning in partially competitive environments, where traditional methods struggle to foster reciprocity-based cooperation. LOLA and POLA agents learn reciprocity-based cooperative policies by differentiation through a few look-ahead optimization steps of their opponent. However, there is a key limitation in these techniques. Because they consider a few optimization steps, a learning opponent that takes many steps to optimize its return may exploit them. In response, we introduce a novel approach, Best Response Shaping (BRS), which differentiates through an opponent approximating the best response, termed the "detective." To condition the detective on the agent's policy for complex games we propose a state-aware differentiable conditioning mechanism, facilitated by a question answering (QA) method that extracts a representation of the agent based on its behaviour on specific environment states. To empirically validate our method, we showcase its enhanced performance against a Monte Carlo Tree Search (MCTS) opponent, which serves as an approximation to the best response in the Coin Game. This work expands the applicability of multi-agent RL in partially competitive environments and provides a new pathway towards achieving improved social welfare in general sum games.
Meta-Value Learning: a General Framework for Learning with Learning Awareness
Jul 17, 2023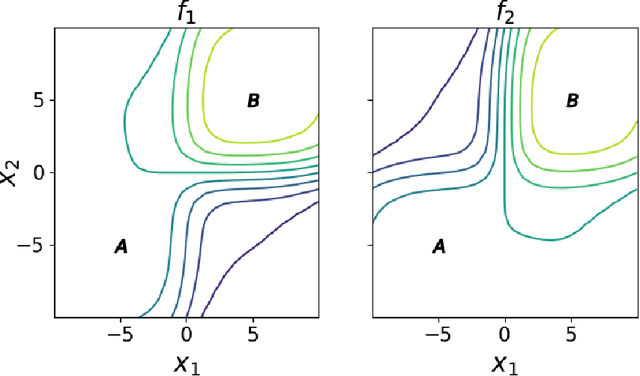
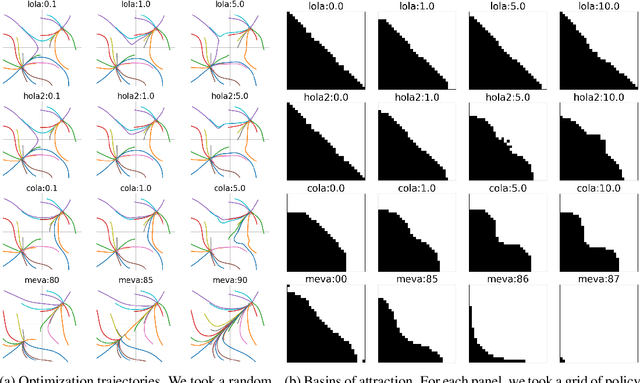
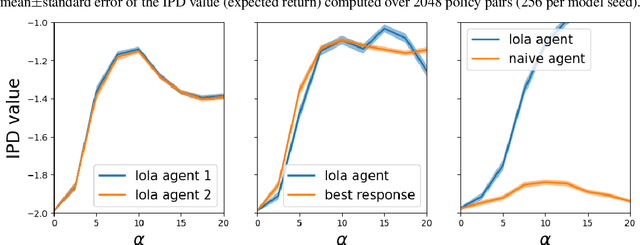
Gradient-based learning in multi-agent systems is difficult because the gradient derives from a first-order model which does not account for the interaction between agents' learning processes. LOLA (arXiv:1709.04326) accounts for this by differentiating through one step of optimization. We extend the ideas of LOLA and develop a fully-general value-based approach to optimization. At the core is a function we call the meta-value, which at each point in joint-policy space gives for each agent a discounted sum of its objective over future optimization steps. We argue that the gradient of the meta-value gives a more reliable improvement direction than the gradient of the original objective, because the meta-value derives from empirical observations of the effects of optimization. We show how the meta-value can be approximated by training a neural network to minimize TD error along optimization trajectories in which agents follow the gradient of the meta-value. We analyze the behavior of our method on the Logistic Game and on the Iterated Prisoner's Dilemma.
Riemannian Diffusion Models
Aug 16, 2022
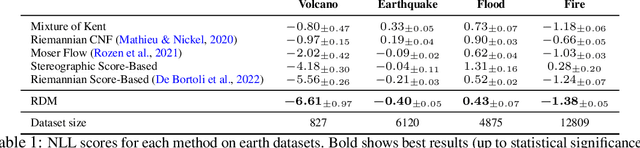


Diffusion models are recent state-of-the-art methods for image generation and likelihood estimation. In this work, we generalize continuous-time diffusion models to arbitrary Riemannian manifolds and derive a variational framework for likelihood estimation. Computationally, we propose new methods for computing the Riemannian divergence which is needed in the likelihood estimation. Moreover, in generalizing the Euclidean case, we prove that maximizing this variational lower-bound is equivalent to Riemannian score matching. Empirically, we demonstrate the expressive power of Riemannian diffusion models on a wide spectrum of smooth manifolds, such as spheres, tori, hyperboloids, and orthogonal groups. Our proposed method achieves new state-of-the-art likelihoods on all benchmarks.