 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing Zhong
Label Propagation Training Schemes for Physics-Informed Neural Networks and Gaussian Processes
Apr 08, 2024
This paper proposes a semi-supervised methodology for training physics-informed machine learning methods. This includes self-training of physics-informed neural networks and physics-informed Gaussian processes in isolation, and the integration of the two via co-training. We demonstrate via extensive numerical experiments how these methods can ameliorate the issue of propagating information forward in time, which is a common failure mode of physics-informed machine learning.
Multi-LoRA Composition for Image Generation
Feb 26, 2024Low-Rank Adaptation (LoRA) is extensively utilized in text-to-image models for the accurate rendition of specific elements like distinct characters or unique styles in generated images. Nonetheless, existing methods face challenges in effectively composing multiple LoRAs, especially as the number of LoRAs to be integrated grows, thus hindering the creation of complex imagery. In this paper, we study multi-LoRA composition through a decoding-centric perspective. We present two training-free methods: LoRA Switch, which alternates between different LoRAs at each denoising step, and LoRA Composite, which simultaneously incorporates all LoRAs to guide more cohesive image synthesis. To evaluate the proposed approaches, we establish ComposLoRA, a new comprehensive testbed as part of this research. It features a diverse range of LoRA categories with 480 composition sets. Utilizing an evaluation framework based on GPT-4V, our findings demonstrate a clear improvement in performance with our methods over the prevalent baseline, particularly evident when increasing the number of LoRAs in a composition.
Investigating Data Contamination for Pre-training Language Models
Jan 11, 2024Language models pre-trained on web-scale corpora demonstrate impressive capabilities on diverse downstream tasks. However, there is increasing concern whether such capabilities might arise from evaluation datasets being included in the pre-training corpus -- a phenomenon known as \textit{data contamination} -- in a manner that artificially increases performance. There has been little understanding of how this potential contamination might influence LMs' performance on downstream tasks. In this paper, we explore the impact of data contamination at the pre-training stage by pre-training a series of GPT-2 models \textit{from scratch}. We highlight the effect of both text contamination (\textit{i.e.}\ input text of the evaluation samples) and ground-truth contamination (\textit{i.e.}\ the prompts asked on the input and the desired outputs) from evaluation data. We also investigate the effects of repeating contamination for various downstream tasks. Additionally, we examine the prevailing n-gram-based definitions of contamination within current LLM reports, pinpointing their limitations and inadequacy. Our findings offer new insights into data contamination's effects on language model capabilities and underscore the need for independent, comprehensive contamination assessments in LLM studies.
PINNs-Based Uncertainty Quantification for Transient Stability Analysis
Nov 21, 2023This paper addresses the challenge of transient stability in power systems with missing parameters and uncertainty propagation in swing equations. We introduce a novel application of Physics-Informed Neural Networks (PINNs), specifically an Ensemble of PINNs (E-PINNs), to estimate critical parameters like rotor angle and inertia coefficient with enhanced accuracy and reduced computational load. E-PINNs capitalize on the underlying physical principles of swing equations to provide a robust solution. Our approach not only facilitates efficient parameter estimation but also quantifies uncertainties, delivering probabilistic insights into the system behavior. The efficacy of E-PINNs is demonstrated through the analysis of $1$-bus and $2$-bus systems, highlighting the model's ability to handle parameter variability and data scarcity. The study advances the application of machine learning in power system stability, paving the way for reliable and computationally efficient transient stability analysis.
Learning Collective Behaviors from Observation
Nov 01, 2023We present a review of a series of learning methods used to identify the structure of dynamical systems, aiming to understand emergent behaviors in complex systems of interacting agents. These methods not only offer theoretical guarantees of convergence but also demonstrate computational efficiency in handling high-dimensional observational data. They can manage observation data from both first- and second-order dynamical systems, accounting for observation/stochastic noise, complex interaction rules, missing interaction features, and real-world observations of interacting agent systems. The essence of developing such a series of learning methods lies in designing appropriate loss functions using the variational inverse problem approach, which inherently provides dimension reduction capabilities to our learning methods.
Instruct and Extract: Instruction Tuning for On-Demand Information Extraction
Oct 24, 2023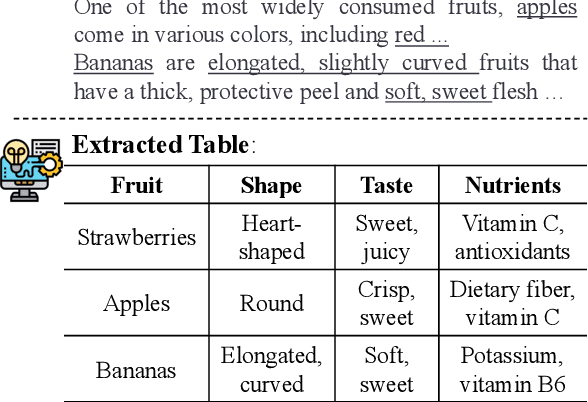

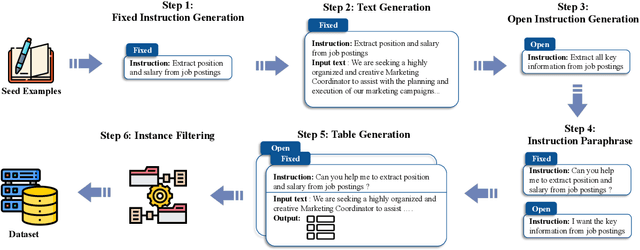
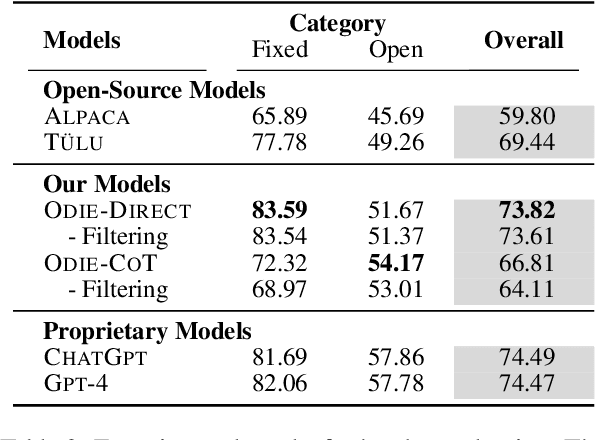
Large language models with instruction-following capabilities open the door to a wider group of users. However, when it comes to information extraction - a classic task in natural language processing - most task-specific systems cannot align well with long-tail ad hoc extraction use cases for non-expert users. To address this, we propose a novel paradigm, termed On-Demand Information Extraction, to fulfill the personalized demands of real-world users. Our task aims to follow the instructions to extract the desired content from the associated text and present it in a structured tabular format. The table headers can either be user-specified or inferred contextually by the model. To facilitate research in this emerging area, we present a benchmark named InstructIE, inclusive of both automatically generated training data, as well as the human-annotated test set. Building on InstructIE, we further develop an On-Demand Information Extractor, ODIE. Comprehensive evaluations on our benchmark reveal that ODIE substantially outperforms the existing open-source models of similar size. Our code and dataset are released on https://github.com/yzjiao/On-Demand-IE.
The Shifted and The Overlooked: A Task-oriented Investigation of User-GPT Interactions
Oct 19, 2023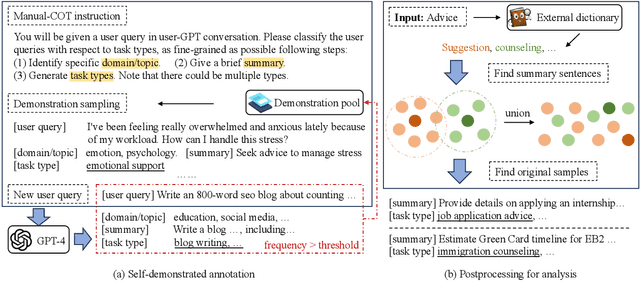

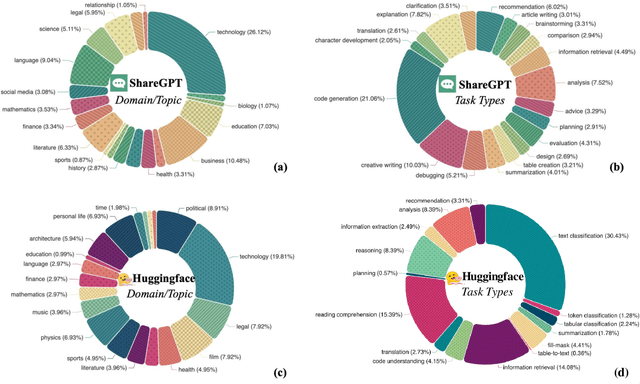
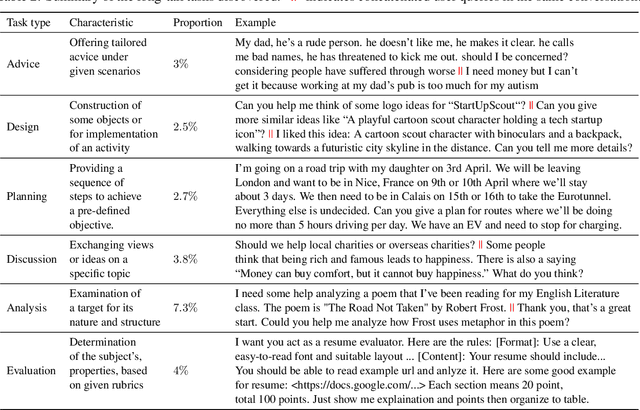
Recent progress in Large Language Models (LLMs) has produced models that exhibit remarkable performance across a variety of NLP tasks. However, it remains unclear whether the existing focus of NLP research accurately captures the genuine requirements of human users. This paper provides a comprehensive analysis of the divergence between current NLP research and the needs of real-world NLP applications via a large-scale collection of user-GPT conversations. We analyze a large-scale collection of real user queries to GPT. We compare these queries against existing NLP benchmark tasks and identify a significant gap between the tasks that users frequently request from LLMs and the tasks that are commonly studied in academic research. For example, we find that tasks such as ``design'' and ``planning'' are prevalent in user interactions but are largely neglected or different from traditional NLP benchmarks. We investigate these overlooked tasks, dissect the practical challenges they pose, and provide insights toward a roadmap to make LLMs better aligned with user needs.
Seeking Neural Nuggets: Knowledge Transfer in Large Language Models from a Parametric Perspective
Oct 17, 2023
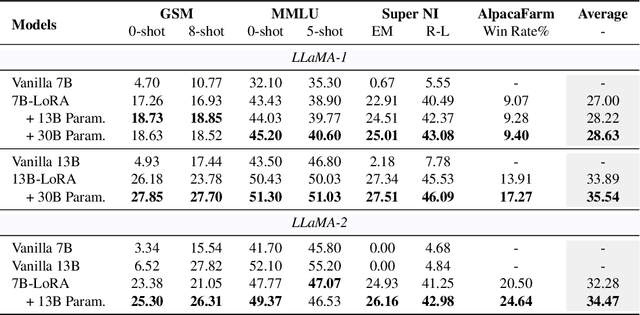
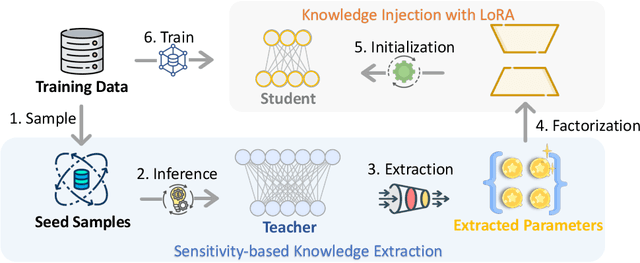
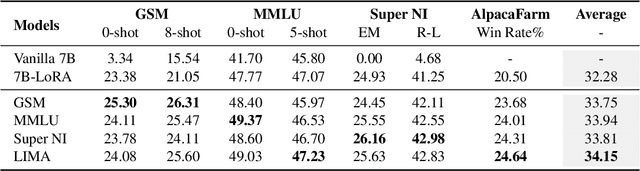
Large Language Models (LLMs) inherently encode a wealth of knowledge within their parameters through pre-training on extensive corpora. While prior research has delved into operations on these parameters to manipulate the underlying implicit knowledge (encompassing detection, editing, and merging), there remains an ambiguous understanding regarding their transferability across models with varying scales. In this paper, we seek to empirically investigate knowledge transfer from larger to smaller models through a parametric perspective. To achieve this, we employ sensitivity-based techniques to extract and align knowledge-specific parameters between different LLMs. Moreover, the LoRA module is used as the intermediary mechanism for injecting the extracted knowledge into smaller models. Evaluations across four benchmarks validate the efficacy of our proposed method. Our findings highlight the critical factors contributing to the process of parametric knowledge transfer, underscoring the transferability of model parameters across LLMs of different scales. We release code and data at \url{https://github.com/maszhongming/ParaKnowTransfer}.
L-Eval: Instituting Standardized Evaluation for Long Context Language Models
Jul 31, 2023
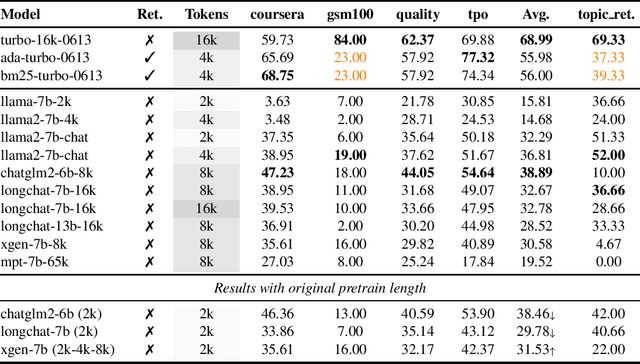
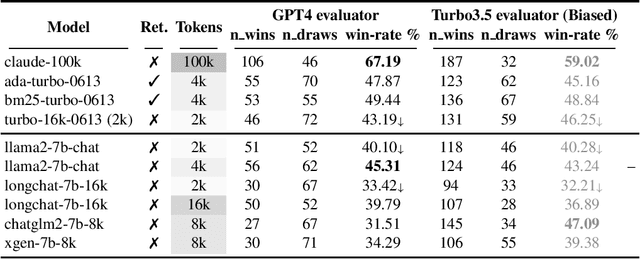
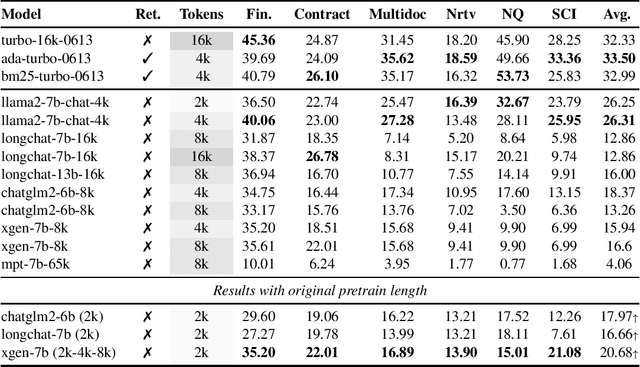
Recently, there has been growing interest in extending the context length of instruction-following models in order to effectively process single-turn long input (e.g. summarizing a paper) and conversations with more extensive histories. While proprietary models such as GPT-4 and Claude have shown significant strides in handling extremely lengthy input, open-sourced models are still in the early stages of experimentation. It also remains unclear whether extending the context can offer substantial gains over traditional methods such as retrieval, and to what extent it improves upon their regular counterparts in practical downstream tasks. To address this challenge, we propose instituting standardized evaluation for long context language models. Concretely, we develop L-Eval which contains 411 long documents and over 2,000 human-labeled query-response pairs encompassing areas such as law, finance, school lectures, lengthy conversations, news, long-form novels, and meetings. L-Eval also adopts diverse evaluation methods and instruction styles, enabling a more reliable assessment of Long Context Language Models (LCLMs). Our findings indicate that while open-source models typically lag behind commercial models, they still exhibit impressive performance compared with their regular versions. LLaMA2-13B achieves the best results on both open-ended tasks (win \textbf{42}\% vs turbo-16k-0613) and closed-ended tasks with only 4k context length. We release our new evaluation suite, code, and all generation results including predictions from all open-sourced LCLMs, GPT4-32k, Cluade-100k at {\url{https://github.com/OpenLMLab/LEval}}.
Towards Saner Deep Image Registration
Jul 24, 2023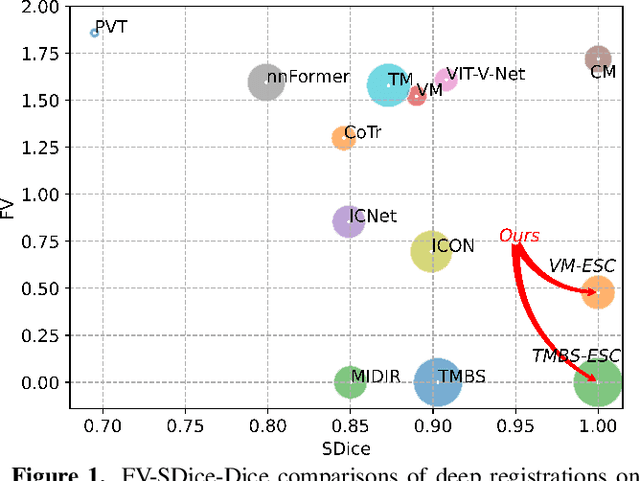

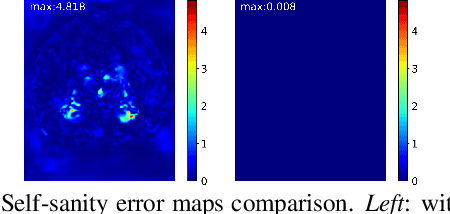
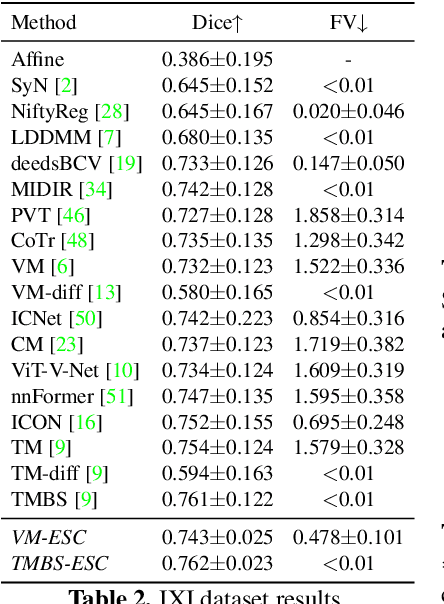
With recent advances in computing hardware and surges of deep-learning architectures, learning-based deep image registration methods have surpassed their traditional counterparts, in terms of metric performance and inference time. However, these methods focus on improving performance measurements such as Dice, resulting in less attention given to model behaviors that are equally desirable for registrations, especially for medical imaging. This paper investigates these behaviors for popular learning-based deep registrations under a sanity-checking microscope. We find that most existing registrations suffer from low inverse consistency and nondiscrimination of identical pairs due to overly optimized image similarities. To rectify these behaviors, we propose a novel regularization-based sanity-enforcer method that imposes two sanity checks on the deep model to reduce its inverse consistency errors and increase its discriminative power simultaneously. Moreover, we derive a set of theoretical guarantees for our sanity-checked image registration method, with experimental results supporting our theoretical findings and their effectiveness in increasing the sanity of models without sacrificing any performance. Our code and models are available at https://github.com/tuffr5/Saner-deep-registration.