 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingfeng Xue
OccuQuest: Mitigating Occupational Bias for Inclusive Large Language Models
Oct 25, 2023
The emergence of large language models (LLMs) has revolutionized natural language processing tasks. However, existing instruction-tuning datasets suffer from occupational bias: the majority of data relates to only a few occupations, which hampers the instruction-tuned LLMs to generate helpful responses to professional queries from practitioners in specific fields. To mitigate this issue and promote occupation-inclusive LLMs, we create an instruction-tuning dataset named \emph{OccuQuest}, which contains 110,000+ prompt-completion pairs and 30,000+ dialogues covering over 1,000 occupations in 26 occupational categories. We systematically request ChatGPT, organizing queries hierarchically based on Occupation, Responsibility, Topic, and Question, to ensure a comprehensive coverage of occupational specialty inquiries. By comparing with three commonly used datasets (Dolly, ShareGPT, and WizardLM), we observe that OccuQuest exhibits a more balanced distribution across occupations. Furthermore, we assemble three test sets for comprehensive evaluation, an occu-test set covering 25 occupational categories, an estate set focusing on real estate, and an occu-quora set containing real-world questions from Quora. We then fine-tune LLaMA on OccuQuest to obtain OccuLLaMA, which significantly outperforms state-of-the-art LLaMA variants (Vicuna, Tulu, and WizardLM) on professional questions in GPT-4 and human evaluations. Notably, on the occu-quora set, OccuLLaMA reaches a high win rate of 86.4\% against WizardLM.
How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition
Oct 09, 2023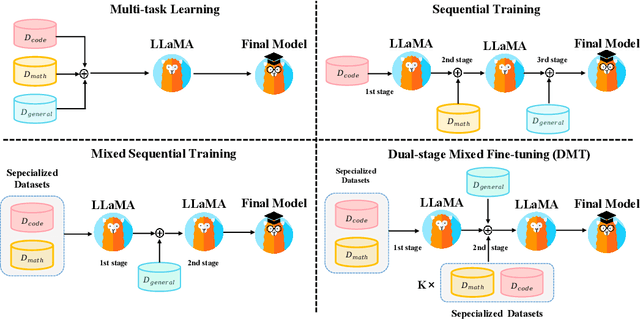
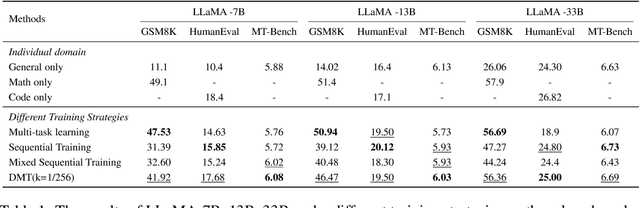
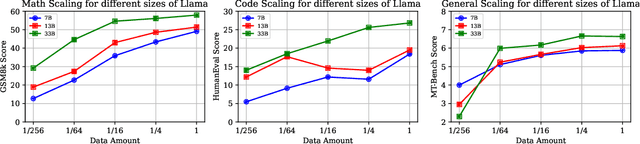
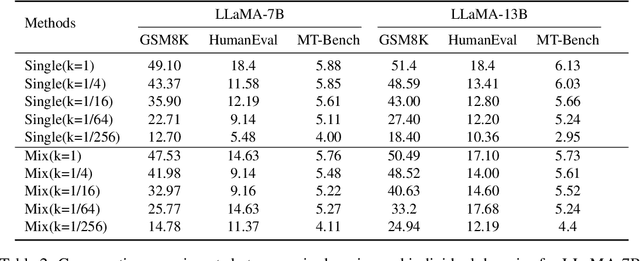
Large language models (LLMs) with enormous pre-training tokens and parameter amounts emerge abilities, including math reasoning, code generation, and instruction following. These abilities are further enhanced by supervised fine-tuning (SFT). The open-source community has studied on ad-hoc SFT for each ability, while proprietary LLMs are versatile for all abilities. It is important to investigate how to unlock them with multiple abilities via SFT. In this study, we specifically focus on the data composition between mathematical reasoning, code generation, and general human-aligning abilities during SFT. From a scaling perspective, we investigate the relationship between model abilities and various factors including data amounts, data composition ratio, model parameters, and SFT strategies. Our experiments reveal that different abilities exhibit different scaling patterns, and larger models generally show superior performance with the same amount of data. Mathematical reasoning and code generation improve as data amounts increase consistently, while the general ability is enhanced with about a thousand samples and improves slowly. We find data composition results in various abilities improvements with low data amounts, while conflicts of abilities with high data amounts. Our experiments further show that composition data amount impacts performance, while the influence of composition ratio is insignificant. Regarding the SFT strategies, we evaluate sequential learning multiple abilities are prone to catastrophic forgetting. Our proposed Dual-stage Mixed Fine-tuning (DMT) strategy learns specialized abilities first and then learns general abilities with a small amount of specialized data to prevent forgetting, offering a promising solution to learn multiple abilities with different scaling patterns.
Tailor: A Prompt-Based Approach to Attribute-Based Controlled Text Generation
Apr 28, 2022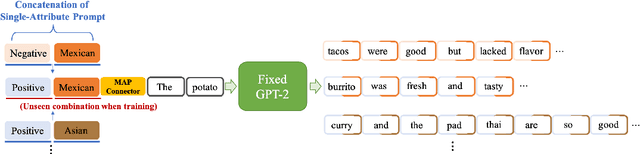
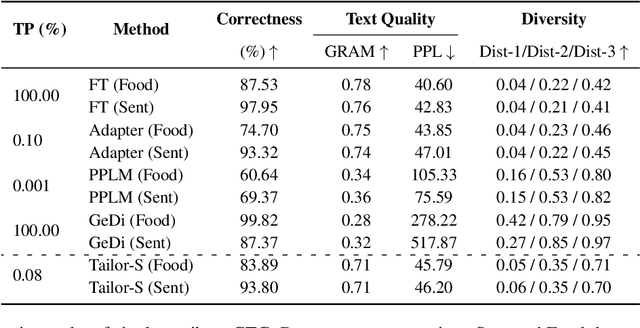
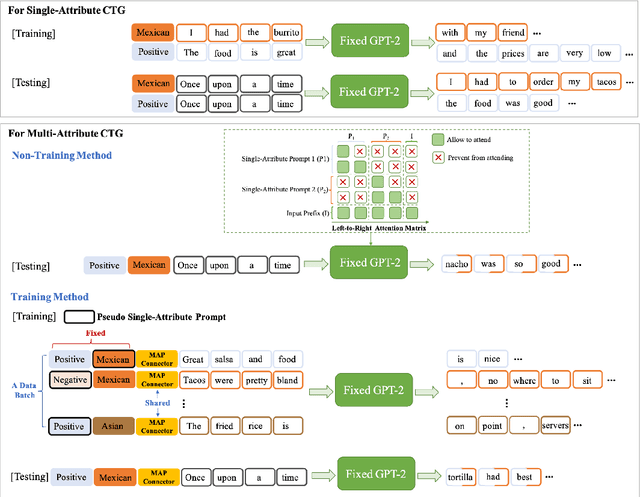
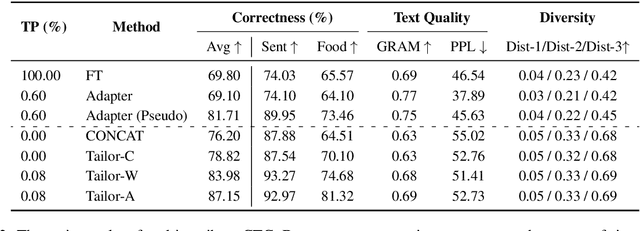
Attribute-based Controlled Text Generation (CTG) refers to generating sentences that satisfy desirable attributes (e.g., emotions and topics). Existing works often utilize fine-tuning or resort to extra attribute classifiers, yet suffer from storage and inference time increases. To address these concerns, we explore attribute-based CTG in a prompt-based manner. In short, the proposed Tailor represents each attribute as a pre-trained continuous vector (i.e., single-attribute prompt) and guides the generation of a fixed PLM switch to a pre-specified attribute. We experimentally find that these prompts can be simply concatenated as a whole to multi-attribute CTG without any re-training, yet raises problems of fluency decrease and position sensitivity. To this end, Tailor provides a multi-attribute prompt mask and a re-indexing position-ids sequence to bridge the gap between the training (one prompt for each task) and testing stage (concatenating more than one prompt). To further enhance such single-attribute prompt combinations, Tailor also introduces a trainable prompt connector, which can be concatenated with any two single-attribute prompts to multi-attribute text generation. Experiments on 11 attribute-specific generation tasks demonstrate strong performances of Tailor on both single-attribute and multi-attribute CTG, with 0.08\% training parameters of a GPT-2.