 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingjia Shi
PRIOR: Personalized Prior for Reactivating the Information Overlooked in Federated Learning
Oct 13, 2023
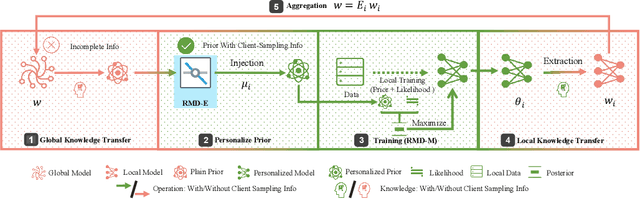
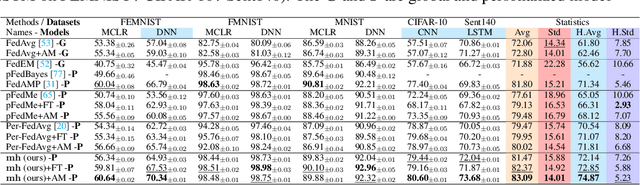
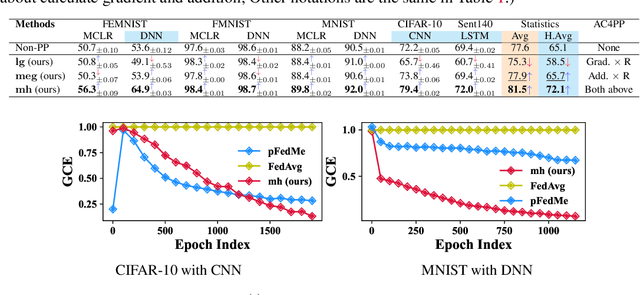
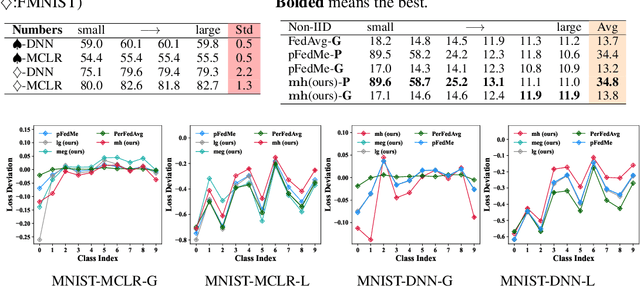
Classical federated learning (FL) enables training machine learning models without sharing data for privacy preservation, but heterogeneous data characteristic degrades the performance of the localized model. Personalized FL (PFL) addresses this by synthesizing personalized models from a global model via training on local data. Such a global model may overlook the specific information that the clients have been sampled. In this paper, we propose a novel scheme to inject personalized prior knowledge into the global model in each client, which attempts to mitigate the introduced incomplete information problem in PFL. At the heart of our proposed approach is a framework, the PFL with Bregman Divergence (pFedBreD), decoupling the personalized prior from the local objective function regularized by Bregman divergence for greater adaptability in personalized scenarios. We also relax the mirror descent (RMD) to extract the prior explicitly to provide optional strategies. Additionally, our pFedBreD is backed up by a convergence analysis. Sufficient experiments demonstrate that our method reaches the state-of-the-art performances on 5 datasets and outperforms other methods by up to 3.5% across 8 benchmarks. Extensive analyses verify the robustness and necessity of proposed designs.
Communication-efficient Federated Learning with Single-Step Synthetic Features Compressor for Faster Convergence
Mar 19, 2023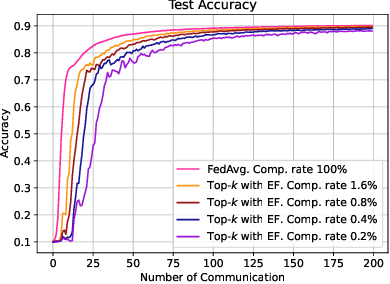
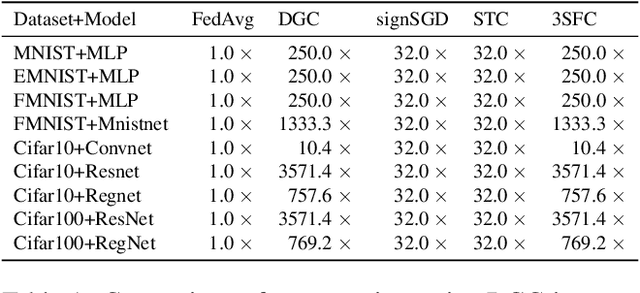
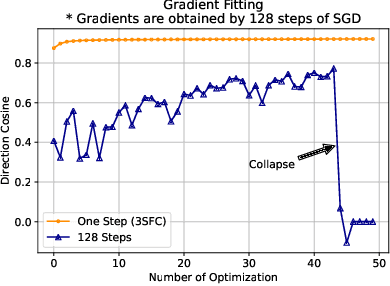
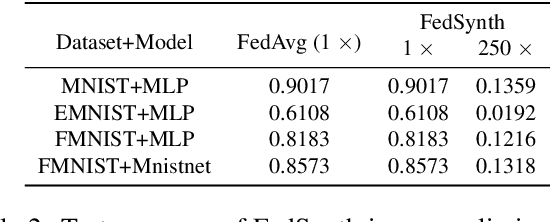
Reducing communication overhead in federated learning (FL) is challenging but crucial for large-scale distributed privacy-preserving machine learning. While methods utilizing sparsification or others can largely lower the communication overhead, the convergence rate is also greatly compromised. In this paper, we propose a novel method, named single-step synthetic features compressor (3SFC), to achieve communication-efficient FL by directly constructing a tiny synthetic dataset based on raw gradients. Thus, 3SFC can achieve an extremely low compression rate when the constructed dataset contains only one data sample. Moreover, 3SFC's compressing phase utilizes a similarity-based objective function so that it can be optimized with just one step, thereby considerably improving its performance and robustness. In addition, to minimize the compressing error, error feedback (EF) is also incorporated into 3SFC. Experiments on multiple datasets and models suggest that 3SFC owns significantly better convergence rates compared to competing methods with lower compression rates (up to 0.02%). Furthermore, ablation studies and visualizations show that 3SFC can carry more information than competing methods for every communication round, further validating its effectiveness.
Personalized Federated Learning with Hidden Information on Personalized Prior
Nov 24, 2022



Federated learning (FL for simplification) is a distributed machine learning technique that utilizes global servers and collaborative clients to achieve privacy-preserving global model training without direct data sharing. However, heterogeneous data problem, as one of FL's main problems, makes it difficult for the global model to perform effectively on each client's local data. Thus, personalized federated learning (PFL for simplification) aims to improve the performance of the model on local data as much as possible. Bayesian learning, where the parameters of the model are seen as random variables with a prior assumption, is a feasible solution to the heterogeneous data problem due to the tendency that the more local data the model use, the more it focuses on the local data, otherwise focuses on the prior. When Bayesian learning is applied to PFL, the global model provides global knowledge as a prior to the local training process. In this paper, we employ Bayesian learning to model PFL by assuming a prior in the scaled exponential family, and therefore propose pFedBreD, a framework to solve the problem we model using Bregman divergence regularization. Empirically, our experiments show that, under the prior assumption of the spherical Gaussian and the first order strategy of mean selection, our proposal significantly outcompetes other PFL algorithms on multiple public benchmarks.
DBS: Dynamic Batch Size For Distributed Deep Neural Network Training
Jul 23, 2020



Synchronous strategies with data parallelism, such as the Synchronous StochasticGradient Descent (S-SGD) and the model averaging methods, are widely utilizedin distributed training of Deep Neural Networks (DNNs), largely owing to itseasy implementation yet promising performance. Particularly, each worker ofthe cluster hosts a copy of the DNN and an evenly divided share of the datasetwith the fixed mini-batch size, to keep the training of DNNs convergence. In thestrategies, the workers with different computational capability, need to wait foreach other because of the synchronization and delays in network transmission,which will inevitably result in the high-performance workers wasting computation.Consequently, the utilization of the cluster is relatively low. To alleviate thisissue, we propose the Dynamic Batch Size (DBS) strategy for the distributedtraining of DNNs. Specifically, the performance of each worker is evaluatedfirst based on the fact in the previous epoch, and then the batch size and datasetpartition are dynamically adjusted in consideration of the current performanceof the worker, thereby improving the utilization of the cluster. To verify theeffectiveness of the proposed strategy, extensive experiments have been conducted,and the experimental results indicate that the proposed strategy can fully utilizethe performance of the cluster, reduce the training time, and have good robustnesswith disturbance by irrelevant tasks. Furthermore, rigorous theoretical analysis hasalso been provided to prove the convergence of the proposed strategy.