 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingjun Zhong
LeOCLR: Leveraging Original Images for Contrastive Learning of Visual Representations
Mar 11, 2024
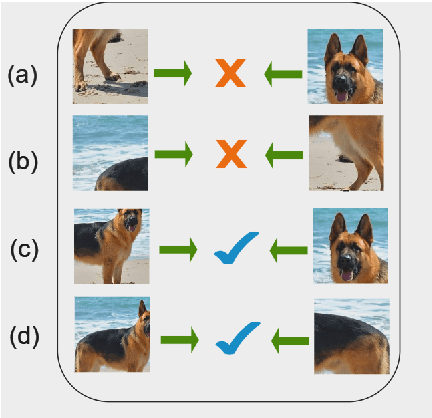
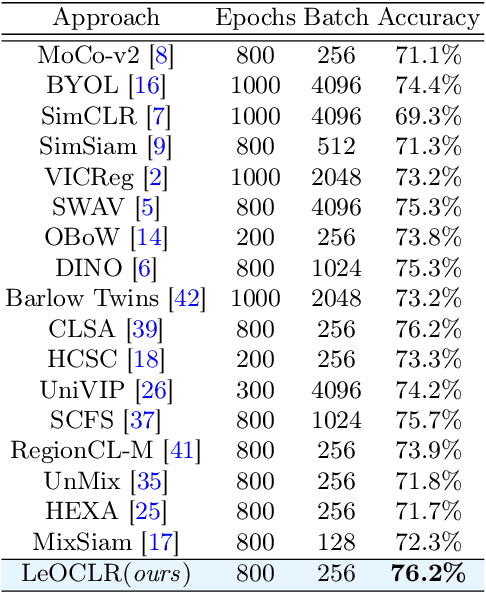
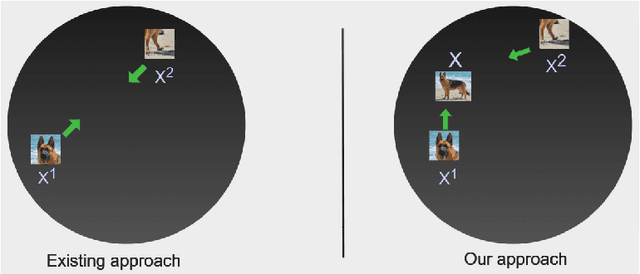
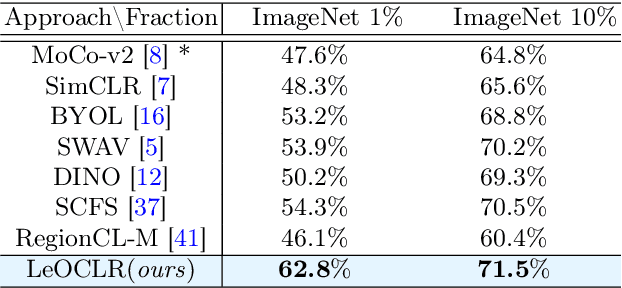
Contrastive instance discrimination outperforms supervised learning in downstream tasks like image classification and object detection. However, this approach heavily relies on data augmentation during representation learning, which may result in inferior results if not properly implemented. Random cropping followed by resizing is a common form of data augmentation used in contrastive learning, but it can lead to degraded representation learning if the two random crops contain distinct semantic content. To address this issue, this paper introduces LeOCLR (Leveraging Original Images for Contrastive Learning of Visual Representations), a framework that employs a new instance discrimination approach and an adapted loss function that ensures the shared region between positive pairs is semantically correct. The experimental results show that our approach consistently improves representation learning across different datasets compared to baseline models. For example, our approach outperforms MoCo-v2 by 5.1% on ImageNet-1K in linear evaluation and several other methods on transfer learning tasks.
Masked Capsule Autoencoders
Mar 07, 2024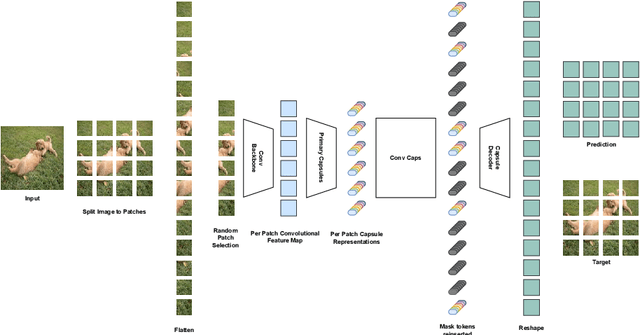
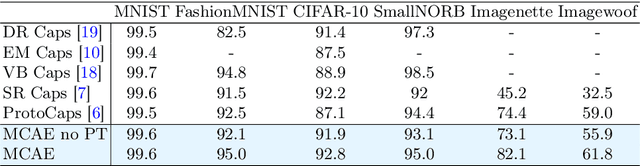
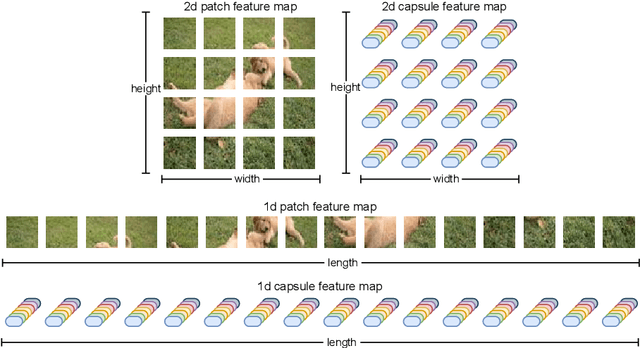
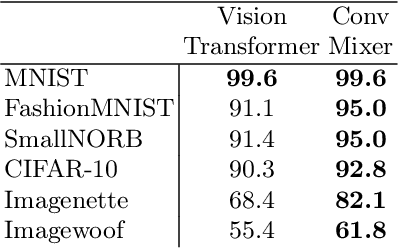
We propose Masked Capsule Autoencoders (MCAE), the first Capsule Network that utilises pretraining in a self-supervised manner. Capsule Networks have emerged as a powerful alternative to Convolutional Neural Networks (CNNs), and have shown favourable properties when compared to Vision Transformers (ViT), but have struggled to effectively learn when presented with more complex data, leading to Capsule Network models that do not scale to modern tasks. Our proposed MCAE model alleviates this issue by reformulating the Capsule Network to use masked image modelling as a pretraining stage before finetuning in a supervised manner. Across several experiments and ablations studies we demonstrate that similarly to CNNs and ViTs, Capsule Networks can also benefit from self-supervised pretraining, paving the way for further advancements in this neural network domain. For instance, pretraining on the Imagenette dataset, a dataset of 10 classes of Imagenet-sized images, we achieve not only state-of-the-art results for Capsule Networks but also a 9% improvement compared to purely supervised training. Thus we propose that Capsule Networks benefit from and should be trained within a masked image modelling framework, with a novel capsule decoder, to improve a Capsule Network's performance on realistic-sized images.
ProtoCaps: A Fast and Non-Iterative Capsule Network Routing Method
Jul 19, 2023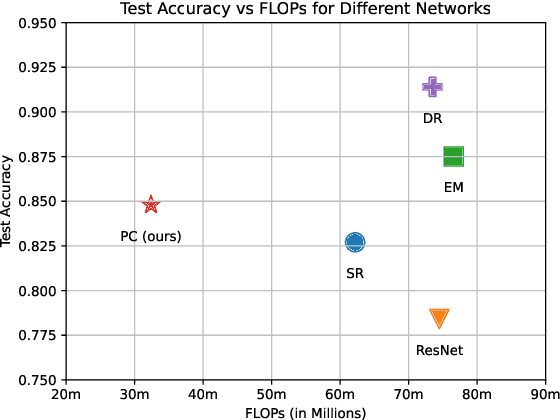
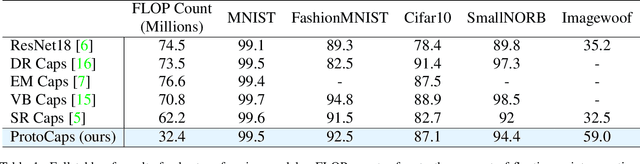


Capsule Networks have emerged as a powerful class of deep learning architectures, known for robust performance with relatively few parameters compared to Convolutional Neural Networks (CNNs). However, their inherent efficiency is often overshadowed by their slow, iterative routing mechanisms which establish connections between Capsule layers, posing computational challenges resulting in an inability to scale. In this paper, we introduce a novel, non-iterative routing mechanism, inspired by trainable prototype clustering. This innovative approach aims to mitigate computational complexity, while retaining, if not enhancing, performance efficacy. Furthermore, we harness a shared Capsule subspace, negating the need to project each lower-level Capsule to each higher-level Capsule, thereby significantly reducing memory requisites during training. Our approach demonstrates superior results compared to the current best non-iterative Capsule Network and tests on the Imagewoof dataset, which is too computationally demanding to handle efficiently by iterative approaches. Our findings underscore the potential of our proposed methodology in enhancing the operational efficiency and performance of Capsule Networks, paving the way for their application in increasingly complex computational scenarios.
Semantic Positive Pairs for Enhancing Contrastive Instance Discrimination
Jun 28, 2023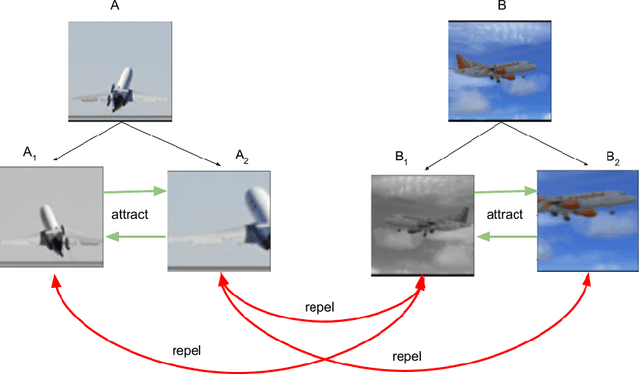

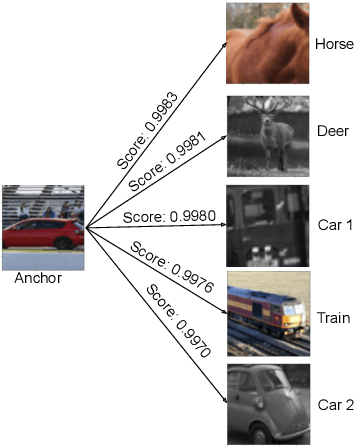

Self-supervised learning algorithms based on instance discrimination effectively prevent representation collapse and produce promising results in representation learning. However, the process of attracting positive pairs (i.e., two views of the same instance) in the embedding space and repelling all other instances (i.e., negative pairs) irrespective of their categories could result in discarding important features. To address this issue, we propose an approach to identifying those images with similar semantic content and treating them as positive instances, named semantic positive pairs set (SPPS), thereby reducing the risk of discarding important features during representation learning. Our approach could work with any contrastive instance discrimination framework such as SimCLR or MOCO. We conduct experiments on three datasets: ImageNet, STL-10 and CIFAR-10 to evaluate our approach. The experimental results show that our approach consistently outperforms the baseline method vanilla SimCLR across all three datasets; for example, our approach improves upon vanilla SimCLR under linear evaluation protocol by 4.18% on ImageNet with a batch size 1024 and 800 epochs.
Vanishing Activations: A Symptom of Deep Capsule Networks
May 13, 2023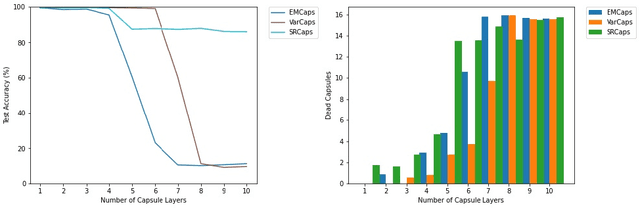
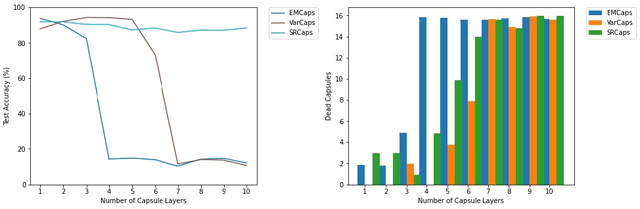
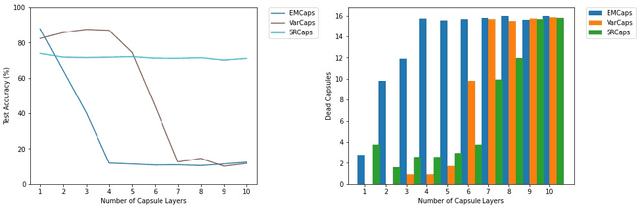
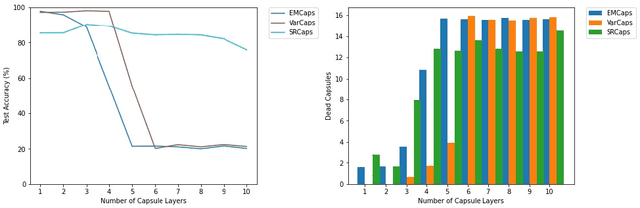
Capsule Networks, an extension to Neural Networks utilizing vector or matrix representations instead of scalars, were initially developed to create a dynamic parse tree where visual concepts evolve from parts to complete objects. Early implementations of Capsule Networks achieved and maintain state-of-the-art results on various datasets. However, recent studies have revealed shortcomings in the original Capsule Network architecture, notably its failure to construct a parse tree and its susceptibility to vanishing gradients when deployed in deeper networks. This paper extends the investigation to a range of leading Capsule Network architectures, demonstrating that these issues are not confined to the original design. We argue that the majority of Capsule Network research has produced architectures that, while modestly divergent from the original Capsule Network, still retain a fundamentally similar structure. We posit that this inherent design similarity might be impeding the scalability of Capsule Networks. Our study contributes to the broader discussion on improving the robustness and scalability of Capsule Networks.
Non-intrusive Load Monitoring based on Self-supervised Learning
Oct 09, 2022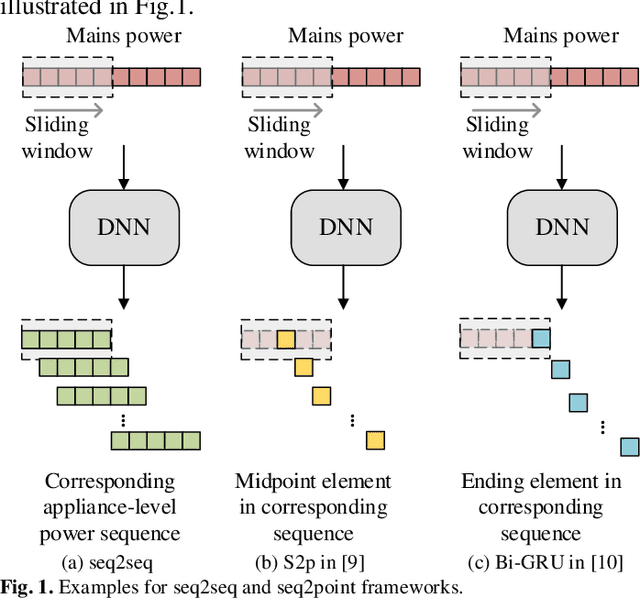
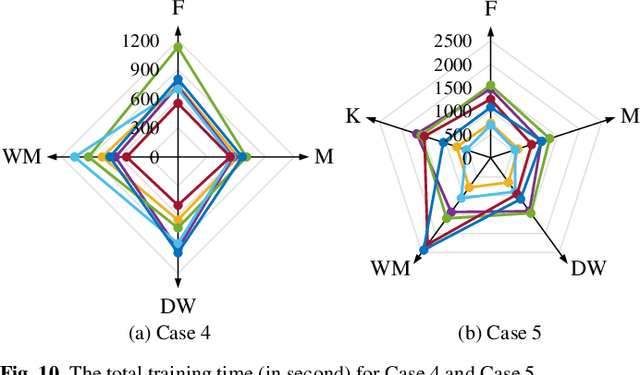
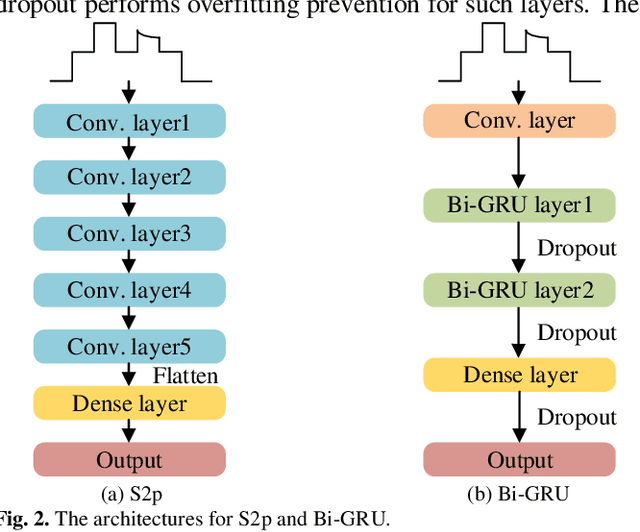
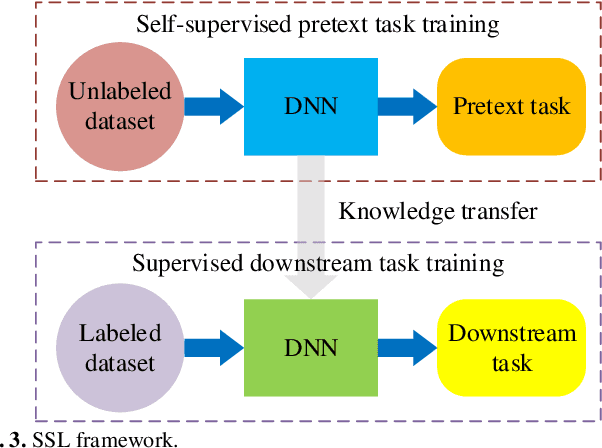
Deep learning models for non-intrusive load monitoring (NILM) tend to require a large amount of labeled data for training. However, it is difficult to generalize the trained models to unseen sites due to different load characteristics and operating patterns of appliances between data sets. For addressing such problems, self-supervised learning (SSL) is proposed in this paper, where labeled appliance-level data from the target data set or house is not required. Initially, only the aggregate power readings from target data set are required to pre-train a general network via a self-supervised pretext task to map aggregate power sequences to derived representatives. Then, supervised downstream tasks are carried out for each appliance category to fine-tune the pre-trained network, where the features learned in the pretext task are transferred. Utilizing labeled source data sets enables the downstream tasks to learn how each load is disaggregated, by mapping the aggregate to labels. Finally, the fine-tuned network is applied to load disaggregation for the target sites. For validation, multiple experimental cases are designed based on three publicly accessible REDD, UK-DALE, and REFIT data sets. Besides, state-of-the-art neural networks are employed to perform NILM task in the experiments. Based on the NILM results in various cases, SSL generally outperforms zero-shot learning in improving load disaggregation performance without any sub-metering data from the target data sets.
Causal Effect Estimation using Variational Information Bottleneck
Oct 26, 2021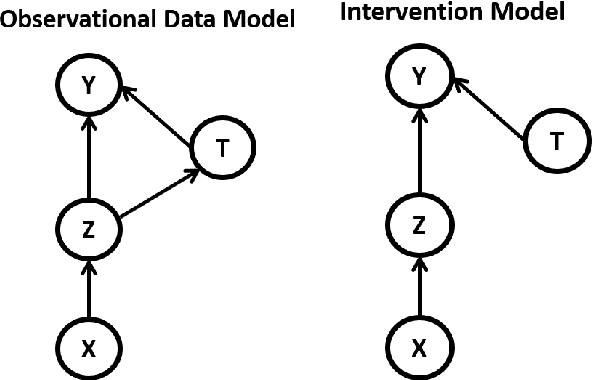
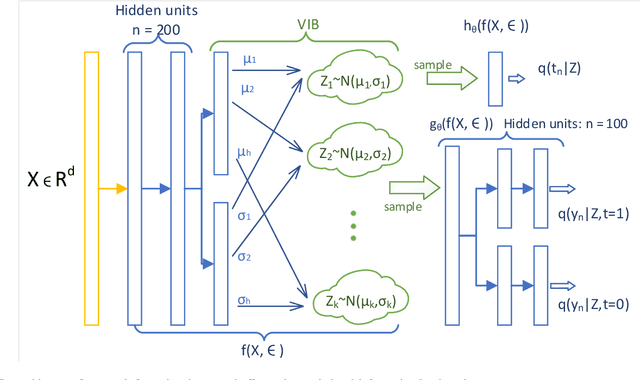
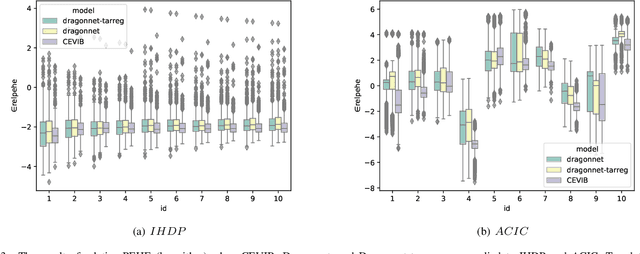
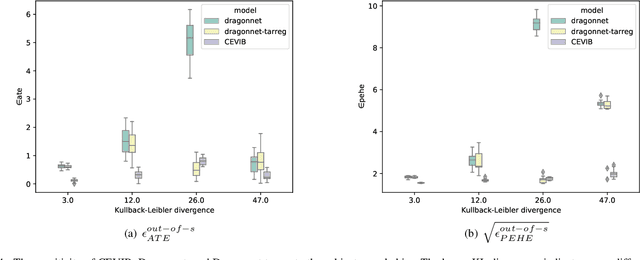
Causal inference is to estimate the causal effect in a causal relationship when intervention is applied. Precisely, in a causal model with binary interventions, i.e., control and treatment, the causal effect is simply the difference between the factual and counterfactual. The difficulty is that the counterfactual may never been obtained which has to be estimated and so the causal effect could only be an estimate. The key challenge for estimating the counterfactual is to identify confounders which effect both outcomes and treatments. A typical approach is to formulate causal inference as a supervised learning problem and so counterfactual could be predicted. Including linear regression and deep learning models, recent machine learning methods have been adapted to causal inference. In this paper, we propose a method to estimate Causal Effect by using Variational Information Bottleneck (CEVIB). The promising point is that VIB is able to naturally distill confounding variables from the data, which enables estimating causal effect by using observational data. We have compared CEVIB to other methods by applying them to three data sets showing that our approach achieved the best performance. We also experimentally showed the robustness of our method.
AREA: Adaptive Reference-set Based Evolutionary Algorithm for Multiobjective Optimisation
Oct 15, 2019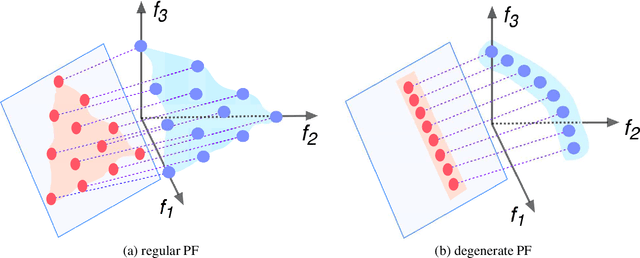


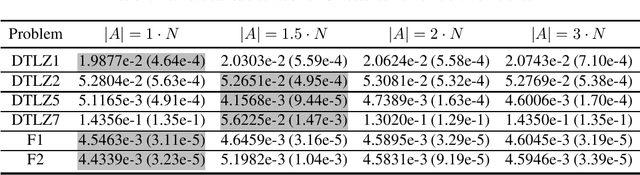
Population-based evolutionary algorithms have great potential to handle multiobjective optimisation problems. However, these algorithms depends largely on problem characteristics, and there is a need to improve their performance for a wider range of problems. References, which are often specified by the decision maker's preference in different forms, are a very effective method to improve the performance of algorithms but have not been fully explored in literature. This paper proposes a novel framework for effective use of references to strengthen algorithms. This framework considers references as search targets which can be adjusted based on the information collected during the search. The proposed framework is combined with new strategies, such as reference adaptation and adaptive local mating, to solve different types of problems. The proposed algorithm is compared with state of the arts on a wide range of problems with diverse characteristics. The comparison and extensive sensitivity analysis demonstrate that the proposed algorithm is competitive and robust across different types of problems studied in this paper.
Trust-Region Variational Inference with Gaussian Mixture Models
Jul 10, 2019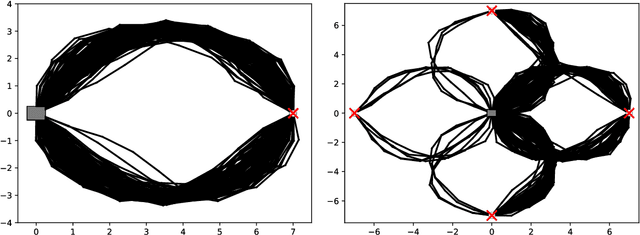

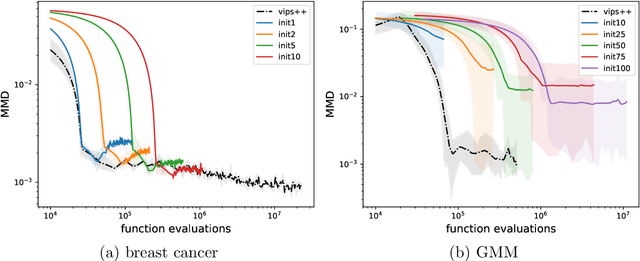

Many methods for machine learning rely on approximate inference from intractable probability distributions. Variational inference approximates such distributions by tractable models that can be subsequently used for approximate inference. Learning sufficiently accurate approximations requires a rich model family and careful exploration of the relevant modes of the target distribution. We propose a method for learning accurate GMM approximations of intractable probability distributions based on insights from policy search by establishing information-geometric trust regions for principled exploration. For efficient improvement of the GMM approximation, we derive a lower bound on the corresponding optimization objective enabling us to update the components independently. The use of the lower bound ensures convergence to a local optimum of the original objective. The number of components is adapted online by adding new components in promising regions and by deleting components with negligible weight. We demonstrate on several domains that we can learn approximations of complex, multi-modal distributions with a quality that is unmet by previous variational inference methods, and that the GMM approximation can be used for drawing samples that are on par with samples created by state-of-the-art MCMC samplers while requiring up to three orders of magnitude less computational resources.
Transfer Learning for Non-Intrusive Load Monitoring
Feb 23, 2019
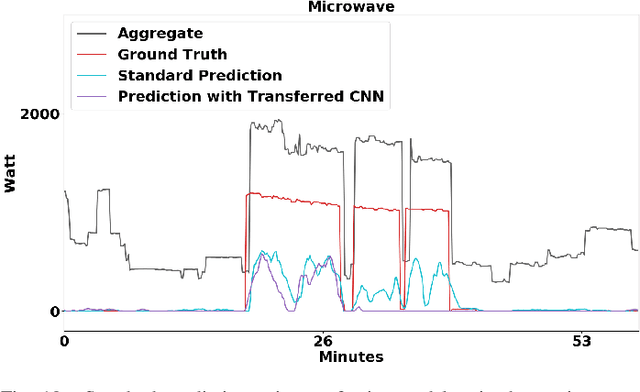
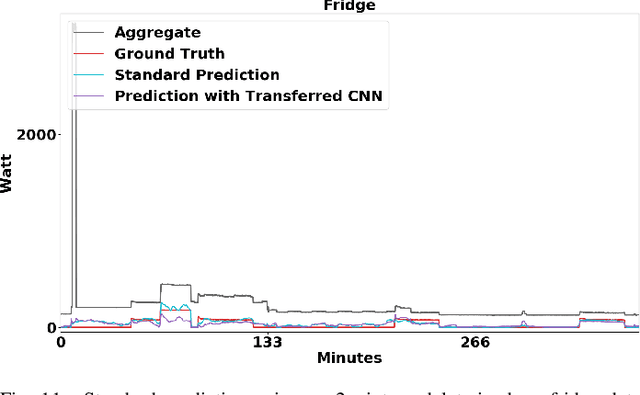
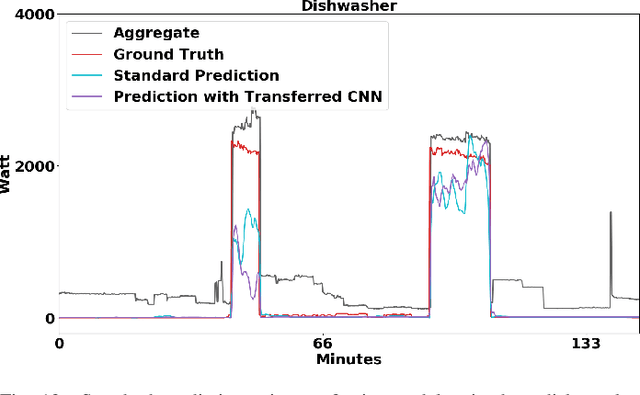
Non-intrusive load monitoring (NILM) is a technique to recover source appliances from only the recorded mains in a household. NILM is unidentifiable and thus a challenge problem because the inferred power value of an appliance given only the mains could not be unique. To mitigate the unidentifiable problem, various methods incorporating domain knowledge into NILM have been proposed and shown effective experimentally. Recently, among these methods, deep neural networks are shown performing best. Arguably, the recently proposed sequence-to-point (seq2point) learning is promising for NILM. However, the results were only carried out on the same data domain. It is not clear if the method could be generalised or transferred to different domains, e.g., the test data were drawn from a different country comparing to the training data. We address this issue in the paper, and two transfer learning schemes are proposed, i.e., appliance transfer learning (ATL) and cross-domain transfer learning (CTL). For ATL, our results show that the latent features learnt by a `complex' appliance, e.g., washing machine, can be transferred to a `simple' appliance, e.g., kettle. For CTL, our conclusion is that the seq2point learning is transferable. Precisely, when the training and test data are in a similar domain, seq2point learning can be directly applied to the test data without fine tuning; when the training and test data are in different domains, seq2point learning needs fine tuning before applying to the test data. Interestingly, we show that only the fully connected layers need fine tuning for transfer learning.