 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingkuan Yuan
Text-to-image Synthesis via Symmetrical Distillation Networks
Aug 21, 2018

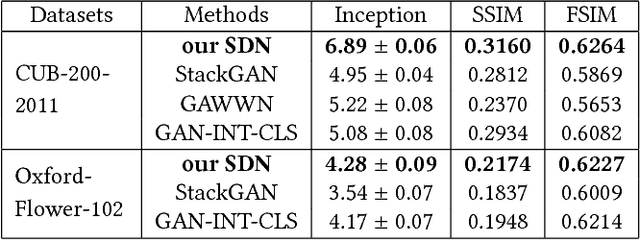
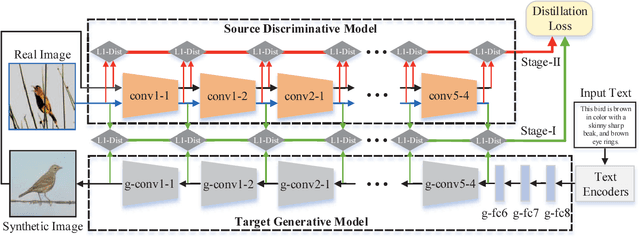
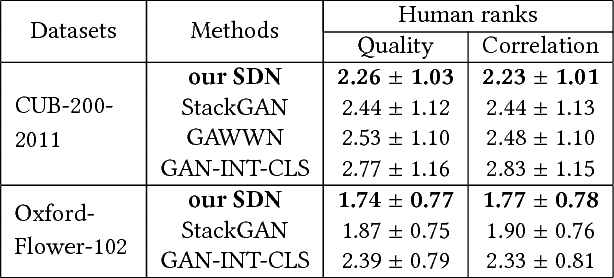
Text-to-image synthesis aims to automatically generate images according to text descriptions given by users, which is a highly challenging task. The main issues of text-to-image synthesis lie in two gaps: the heterogeneous and homogeneous gaps. The heterogeneous gap is between the high-level concepts of text descriptions and the pixel-level contents of images, while the homogeneous gap exists between synthetic image distributions and real image distributions. For addressing these problems, we exploit the excellent capability of generic discriminative models (e.g. VGG19), which can guide the training process of a new generative model on multiple levels to bridge the two gaps. The high-level representations can teach the generative model to extract necessary visual information from text descriptions, which can bridge the heterogeneous gap. The mid-level and low-level representations can lead it to learn structures and details of images respectively, which relieves the homogeneous gap. Therefore, we propose Symmetrical Distillation Networks (SDN) composed of a source discriminative model as "teacher" and a target generative model as "student". The target generative model has a symmetrical structure with the source discriminative model, in order to transfer hierarchical knowledge accessibly. Moreover, we decompose the training process into two stages with different distillation paradigms for promoting the performance of the target generative model. Experiments on two widely-used datasets are conducted to verify the effectiveness of our proposed SDN.
SCH-GAN: Semi-supervised Cross-modal Hashing by Generative Adversarial Network
Feb 07, 2018
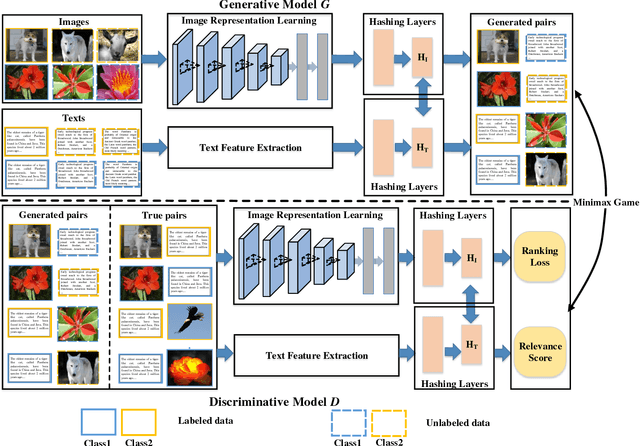
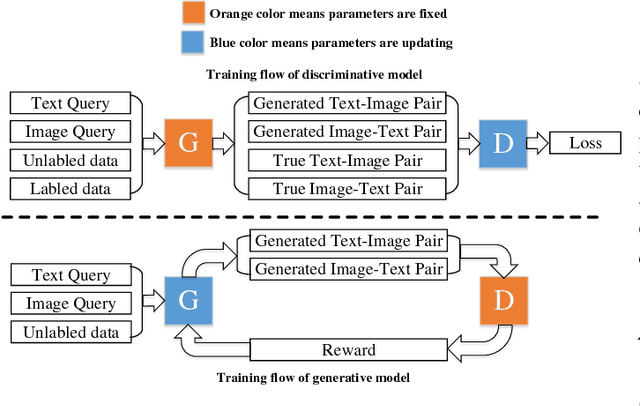
Cross-modal hashing aims to map heterogeneous multimedia data into a common Hamming space, which can realize fast and flexible retrieval across different modalities. Supervised cross-modal hashing methods have achieved considerable progress by incorporating semantic side information. However, they mainly have two limitations: (1) Heavily rely on large-scale labeled cross-modal training data which are labor intensive and hard to obtain. (2) Ignore the rich information contained in the large amount of unlabeled data across different modalities, especially the margin examples that are easily to be incorrectly retrieved, which can help to model the correlations. To address these problems, in this paper we propose a novel Semi-supervised Cross-Modal Hashing approach by Generative Adversarial Network (SCH-GAN). We aim to take advantage of GAN's ability for modeling data distributions to promote cross-modal hashing learning in an adversarial way. The main contributions can be summarized as follows: (1) We propose a novel generative adversarial network for cross-modal hashing. In our proposed SCH-GAN, the generative model tries to select margin examples of one modality from unlabeled data when giving a query of another modality. While the discriminative model tries to distinguish the selected examples and true positive examples of the query. These two models play a minimax game so that the generative model can promote the hashing performance of discriminative model. (2) We propose a reinforcement learning based algorithm to drive the training of proposed SCH-GAN. The generative model takes the correlation score predicted by discriminative model as a reward, and tries to select the examples close to the margin to promote discriminative model by maximizing the margin between positive and negative data. Experiments on 3 widely-used datasets verify the effectiveness of our proposed approach.
Unsupervised Generative Adversarial Cross-modal Hashing
Dec 01, 2017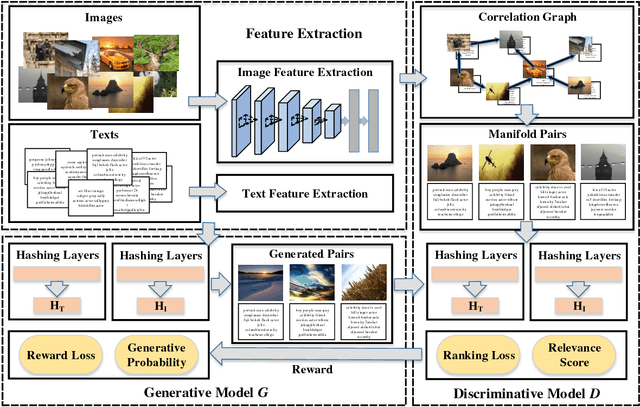
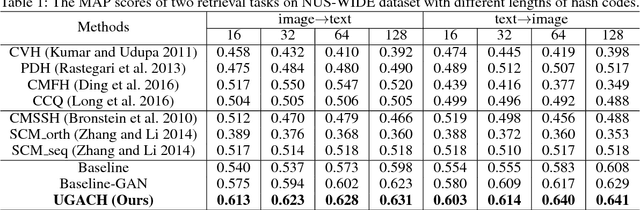
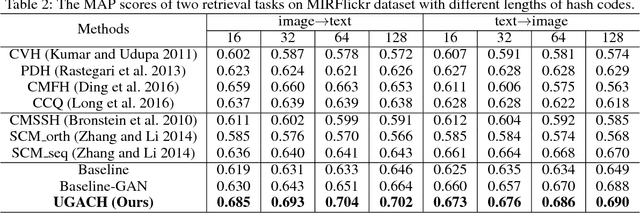
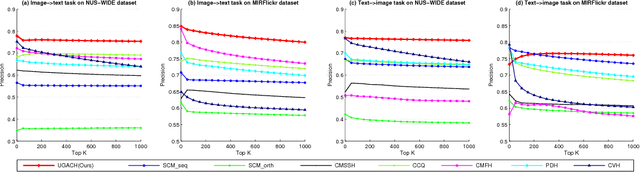
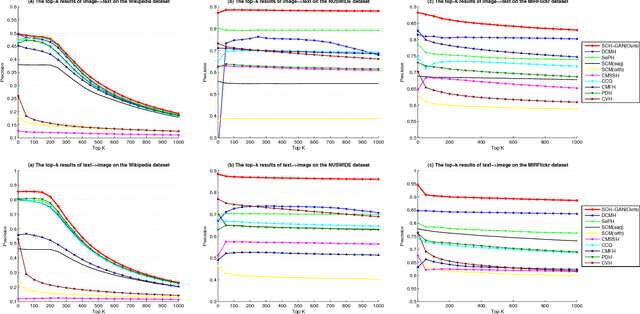
Cross-modal hashing aims to map heterogeneous multimedia data into a common Hamming space, which can realize fast and flexible retrieval across different modalities. Unsupervised cross-modal hashing is more flexible and applicable than supervised methods, since no intensive labeling work is involved. However, existing unsupervised methods learn hashing functions by preserving inter and intra correlations, while ignoring the underlying manifold structure across different modalities, which is extremely helpful to capture meaningful nearest neighbors of different modalities for cross-modal retrieval. To address the above problem, in this paper we propose an Unsupervised Generative Adversarial Cross-modal Hashing approach (UGACH), which makes full use of GAN's ability for unsupervised representation learning to exploit the underlying manifold structure of cross-modal data. The main contributions can be summarized as follows: (1) We propose a generative adversarial network to model cross-modal hashing in an unsupervised fashion. In the proposed UGACH, given a data of one modality, the generative model tries to fit the distribution over the manifold structure, and select informative data of another modality to challenge the discriminative model. The discriminative model learns to distinguish the generated data and the true positive data sampled from correlation graph to achieve better retrieval accuracy. These two models are trained in an adversarial way to improve each other and promote hashing function learning. (2) We propose a correlation graph based approach to capture the underlying manifold structure across different modalities, so that data of different modalities but within the same manifold can have smaller Hamming distance and promote retrieval accuracy. Extensive experiments compared with 6 state-of-the-art methods verify the effectiveness of our proposed approach.
MHTN: Modal-adversarial Hybrid Transfer Network for Cross-modal Retrieval
Aug 08, 2017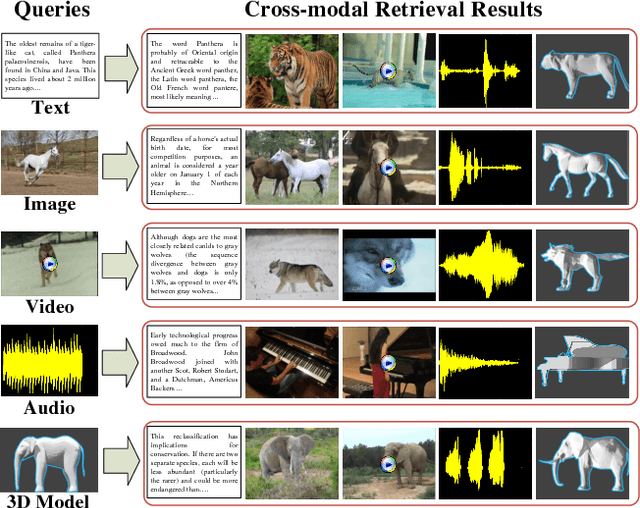

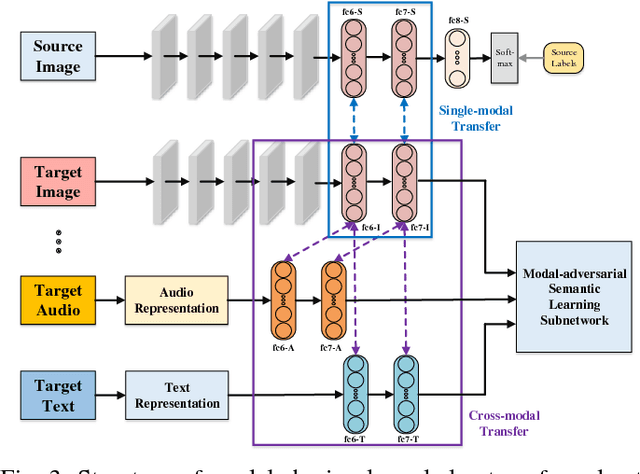
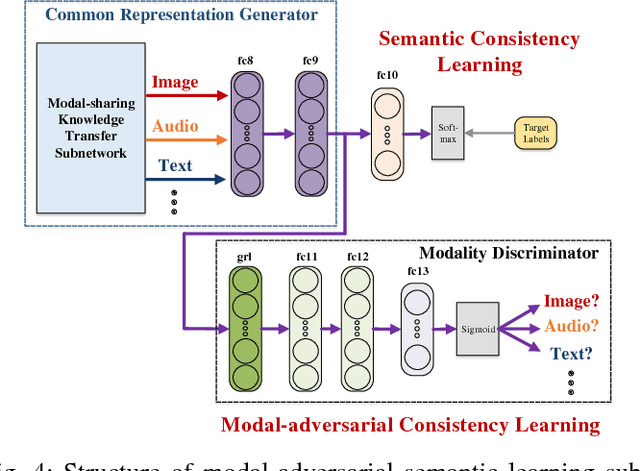
Cross-modal retrieval has drawn wide interest for retrieval across different modalities of data. However, existing methods based on DNN face the challenge of insufficient cross-modal training data, which limits the training effectiveness and easily leads to overfitting. Transfer learning is for relieving the problem of insufficient training data, but it mainly focuses on knowledge transfer only from large-scale datasets as single-modal source domain to single-modal target domain. Such large-scale single-modal datasets also contain rich modal-independent semantic knowledge that can be shared across different modalities. Besides, large-scale cross-modal datasets are very labor-consuming to collect and label, so it is significant to fully exploit the knowledge in single-modal datasets for boosting cross-modal retrieval. This paper proposes modal-adversarial hybrid transfer network (MHTN), which to the best of our knowledge is the first work to realize knowledge transfer from single-modal source domain to cross-modal target domain, and learn cross-modal common representation. It is an end-to-end architecture with two subnetworks: (1) Modal-sharing knowledge transfer subnetwork is proposed to jointly transfer knowledge from a large-scale single-modal dataset in source domain to all modalities in target domain with a star network structure, which distills modal-independent supplementary knowledge for promoting cross-modal common representation learning. (2) Modal-adversarial semantic learning subnetwork is proposed to construct an adversarial training mechanism between common representation generator and modality discriminator, making the common representation discriminative for semantics but indiscriminative for modalities to enhance cross-modal semantic consistency during transfer process. Comprehensive experiments on 4 widely-used datasets show its effectiveness and generality.
Cross-modal Common Representation Learning by Hybrid Transfer Network
Jun 24, 2017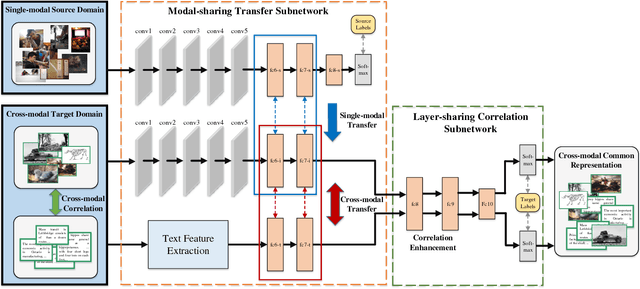


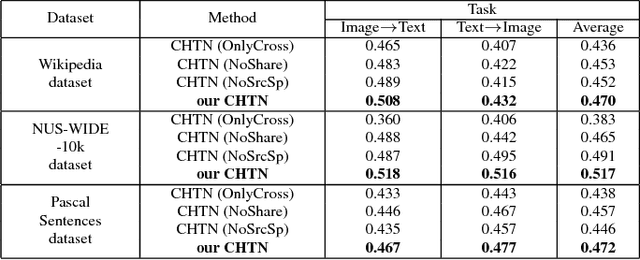
DNN-based cross-modal retrieval is a research hotspot to retrieve across different modalities as image and text, but existing methods often face the challenge of insufficient cross-modal training data. In single-modal scenario, similar problem is usually relieved by transferring knowledge from large-scale auxiliary datasets (as ImageNet). Knowledge from such single-modal datasets is also very useful for cross-modal retrieval, which can provide rich general semantic information that can be shared across different modalities. However, it is challenging to transfer useful knowledge from single-modal (as image) source domain to cross-modal (as image/text) target domain. Knowledge in source domain cannot be directly transferred to both two different modalities in target domain, and the inherent cross-modal correlation contained in target domain provides key hints for cross-modal retrieval which should be preserved during transfer process. This paper proposes Cross-modal Hybrid Transfer Network (CHTN) with two subnetworks: Modal-sharing transfer subnetwork utilizes the modality in both source and target domains as a bridge, for transferring knowledge to both two modalities simultaneously; Layer-sharing correlation subnetwork preserves the inherent cross-modal semantic correlation to further adapt to cross-modal retrieval task. Cross-modal data can be converted to common representation by CHTN for retrieval, and comprehensive experiment on 3 datasets shows its effectiveness.