 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinhak Song
Linear attention is (maybe) all you need (to understand transformer optimization)
Oct 02, 2023
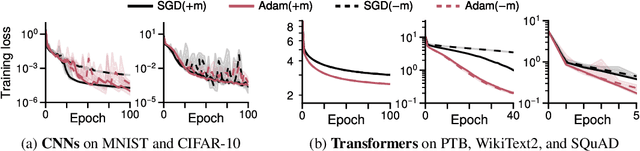
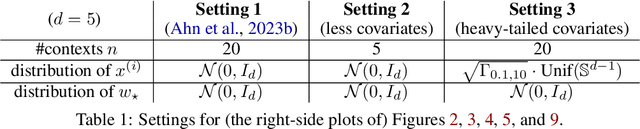
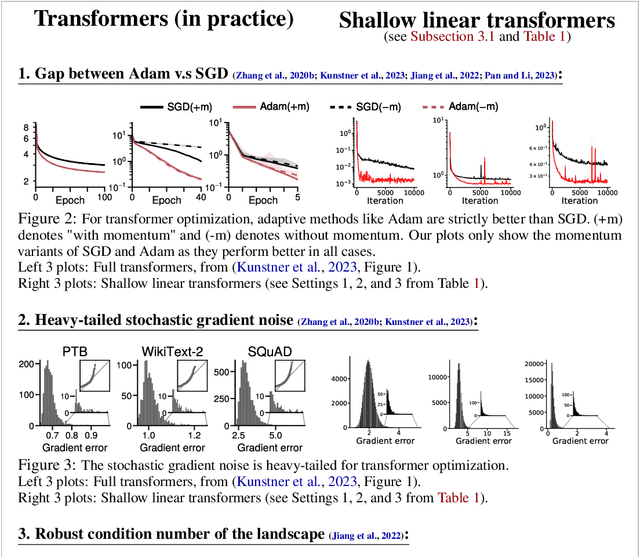

Transformer training is notoriously difficult, requiring a careful design of optimizers and use of various heuristics. We make progress towards understanding the subtleties of training transformers by carefully studying a simple yet canonical linearized shallow transformer model. Specifically, we train linear transformers to solve regression tasks, inspired by J. von Oswald et al. (ICML 2023), and K. Ahn et al. (NeurIPS 2023). Most importantly, we observe that our proposed linearized models can reproduce several prominent aspects of transformer training dynamics. Consequently, the results obtained in this paper suggest that a simple linearized transformer model could actually be a valuable, realistic abstraction for understanding transformer optimization.
Trajectory Alignment: Understanding the Edge of Stability Phenomenon via Bifurcation Theory
Jul 09, 2023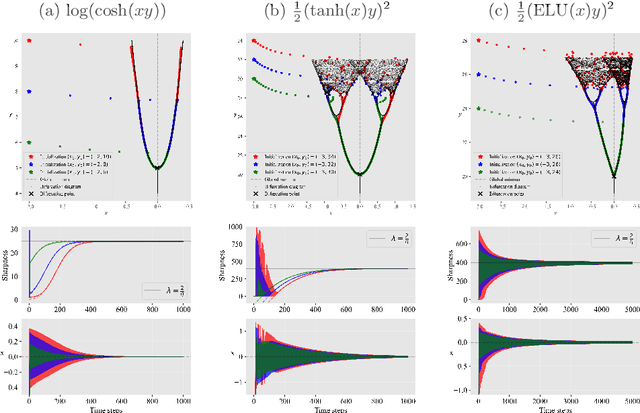
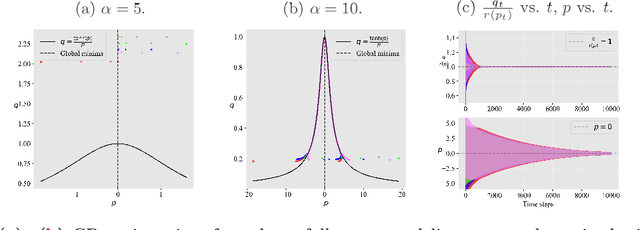
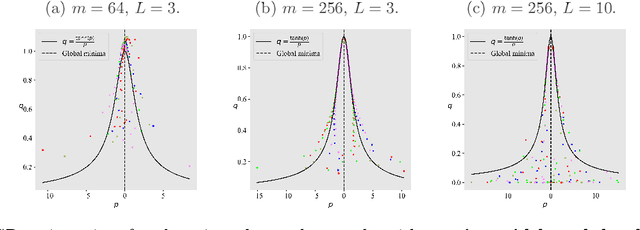
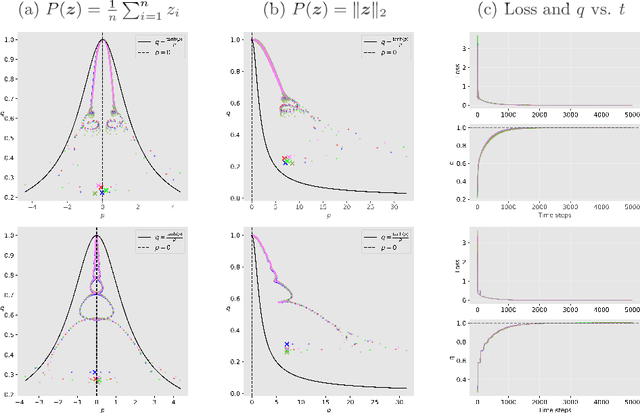
Cohen et al. (2021) empirically study the evolution of the largest eigenvalue of the loss Hessian, also known as sharpness, along the gradient descent (GD) trajectory and observe a phenomenon called the Edge of Stability (EoS). The sharpness increases at the early phase of training (referred to as progressive sharpening), and eventually saturates close to the threshold of $2 / \text{(step size)}$. In this paper, we start by demonstrating through empirical studies that when the EoS phenomenon occurs, different GD trajectories (after a proper reparameterization) align on a specific bifurcation diagram independent of initialization. We then rigorously prove this trajectory alignment phenomenon for a two-layer fully-connected linear network and a single-neuron nonlinear network trained with a single data point. Our trajectory alignment analysis establishes both progressive sharpening and EoS phenomena, encompassing and extending recent findings in the literature.