 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitchell P. Marcus
Text Chunking using Transformation-Based Learning
May 23, 1995




Eric Brill introduced transformation-based learning and showed that it can do part-of-speech tagging with fairly high accuracy. The same method can be applied at a higher level of textual interpretation for locating chunks in the tagged text, including non-recursive ``baseNP'' chunks. For this purpose, it is convenient to view chunking as a tagging problem by encoding the chunk structure in new tags attached to each word. In automatic tests using Treebank-derived data, this technique achieved recall and precision rates of roughly 92% for baseNP chunks and 88% for somewhat more complex chunks that partition the sentence. Some interesting adaptations to the transformation-based learning approach are also suggested by this application.
* 13 pages, LaTeX2e, 1 included figure
Exploring the Statistical Derivation of Transformational Rule Sequences for Part-of-Speech Tagging
Jun 03, 1994



Eric Brill has recently proposed a simple and powerful corpus-based language modeling approach that can be applied to various tasks including part-of-speech tagging and building phrase structure trees. The method learns a series of symbolic transformational rules, which can then be applied in sequence to a test corpus to produce predictions. The learning process only requires counting matches for a given set of rule templates, allowing the method to survey a very large space of possible contextual factors. This paper analyses Brill's approach as an interesting variation on existing decision tree methods, based on experiments involving part-of-speech tagging for both English and ancient Greek corpora. In particular, the analysis throws light on why the new mechanism seems surprisingly resistant to overtraining. A fast, incremental implementation and a mechanism for recording the dependencies that underlie the resulting rule sequence are also described.
* 10 pages, in proceedings of the ACL Balancing Act workshop
Pearl: A Probabilistic Chart Parser
May 03, 1994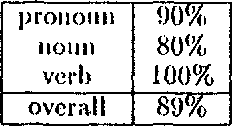
This paper describes a natural language parsing algorithm for unrestricted text which uses a probability-based scoring function to select the "best" parse of a sentence. The parser, Pearl, is a time-asynchronous bottom-up chart parser with Earley-type top-down prediction which pursues the highest-scoring theory in the chart, where the score of a theory represents the extent to which the context of the sentence predicts that interpretation. This parser differs from previous attempts at stochastic parsers in that it uses a richer form of conditional probabilities based on context to predict likelihood. Pearl also provides a framework for incorporating the results of previous work in part-of-speech assignment, unknown word models, and other probabilistic models of linguistic features into one parsing tool, interleaving these techniques instead of using the traditional pipeline architecture. In preliminary tests, Pearl has been successful at resolving part-of-speech and word (in speech processing) ambiguity, determining categories for unknown words, and selecting correct parses first using a very loosely fitting covering grammar.
* 7 pages