 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoacir Antonelli Ponti
Decoupling Decision-Making in Fraud Prevention through Classifier Calibration for Business Logic Action
Jan 10, 2024
Machine learning models typically focus on specific targets like creating classifiers, often based on known population feature distributions in a business context. However, models calculating individual features adapt over time to improve precision, introducing the concept of decoupling: shifting from point evaluation to data distribution. We use calibration strategies as strategy for decoupling machine learning (ML) classifiers from score-based actions within business logic frameworks. To evaluate these strategies, we perform a comparative analysis using a real-world business scenario and multiple ML models. Our findings highlight the trade-offs and performance implications of the approach, offering valuable insights for practitioners seeking to optimize their decoupling efforts. In particular, the Isotonic and Beta calibration methods stand out for scenarios in which there is shift between training and testing data.
Evaluation of Barlow Twins and VICReg self-supervised learning for sound patterns of bird and anuran species
Dec 18, 2023Taking advantage of the structure of large datasets to pre-train Deep Learning models is a promising strategy to decrease the need for supervised data. Self-supervised learning methods, such as contrastive and its variation are a promising way towards obtaining better representations in many Deep Learning applications. Soundscape ecology is one application in which annotations are expensive and scarce, therefore deserving investigation to approximate methods that do not require annotations to those that rely on supervision. Our study involves the use of the methods Barlow Twins and VICReg to pre-train different models with the same small dataset with sound patterns of bird and anuran species. In a downstream task to classify those animal species, the models obtained results close to supervised ones, pre-trained in large generic datasets, and fine-tuned with the same task.
Dendrogram distance: an evaluation metric for generative networks using hierarchical clustering
Nov 28, 2023We present a novel metric for generative modeling evaluation, focusing primarily on generative networks. The method uses dendrograms to represent real and fake data, allowing for the divergence between training and generated samples to be computed. This metric focus on mode collapse, targeting generators that are not able to capture all modes in the training set. To evaluate the proposed method it is introduced a validation scheme based on sampling from real datasets, therefore the metric is evaluated in a controlled environment and proves to be competitive with other state-of-the-art approaches.
Sketch-an-Anchor: Sub-epoch Fast Model Adaptation for Zero-shot Sketch-based Image Retrieval
Mar 29, 2023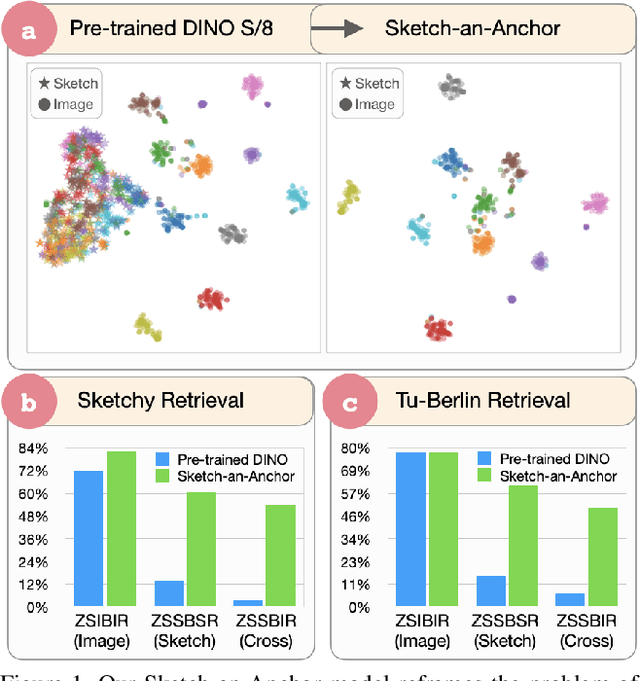
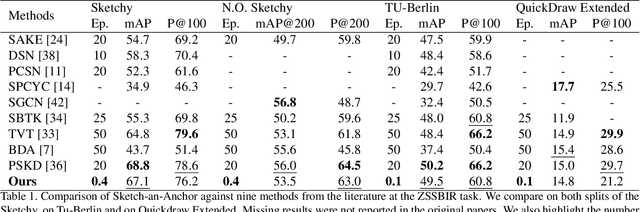
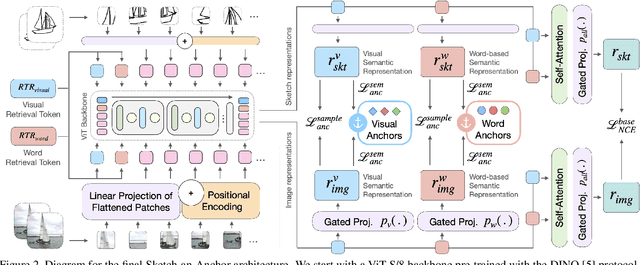
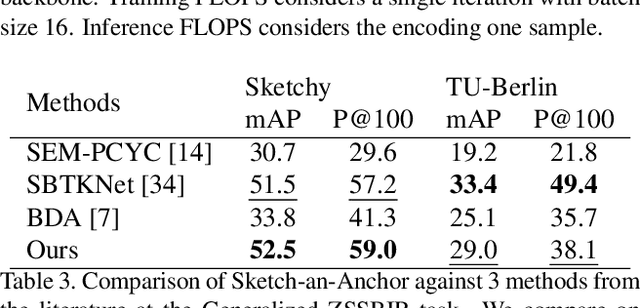
Sketch-an-Anchor is a novel method to train state-of-the-art Zero-shot Sketch-based Image Retrieval (ZSSBIR) models in under an epoch. Most studies break down the problem of ZSSBIR into two parts: domain alignment between images and sketches, inherited from SBIR, and generalization to unseen data, inherent to the zero-shot protocol. We argue one of these problems can be considerably simplified and re-frame the ZSSBIR problem around the already-stellar yet underexplored Zero-shot Image-based Retrieval performance of off-the-shelf models. Our fast-converging model keeps the single-domain performance while learning to extract similar representations from sketches. To this end we introduce our Semantic Anchors -- guiding embeddings learned from word-based semantic spaces and features from off-the-shelf models -- and combine them with our novel Anchored Contrastive Loss. Empirical evidence shows we can achieve state-of-the-art performance on all benchmark datasets while training for 100x less iterations than other methods.
Improving Data Quality with Training Dynamics of Gradient Boosting Decision Trees
Oct 20, 2022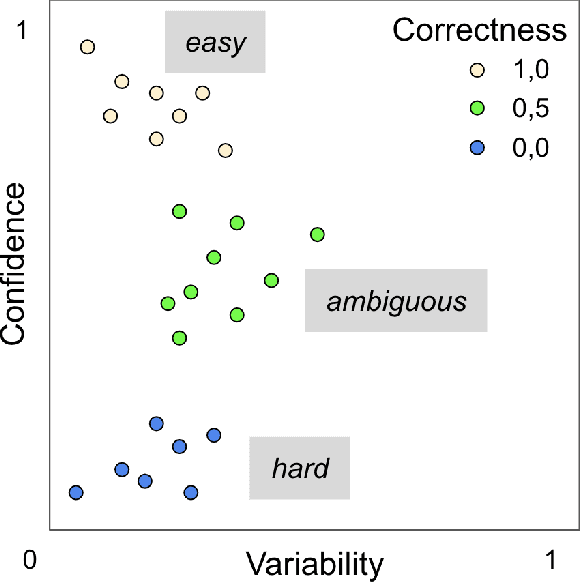
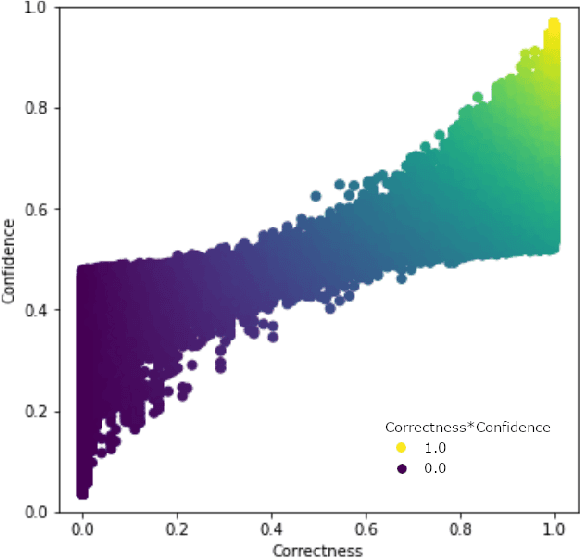
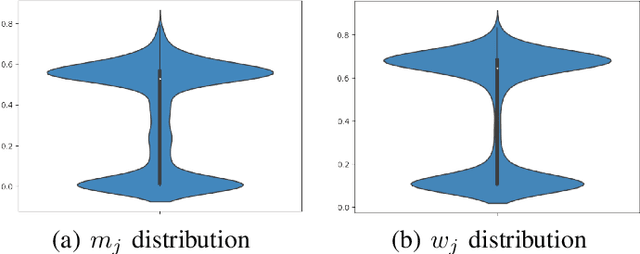
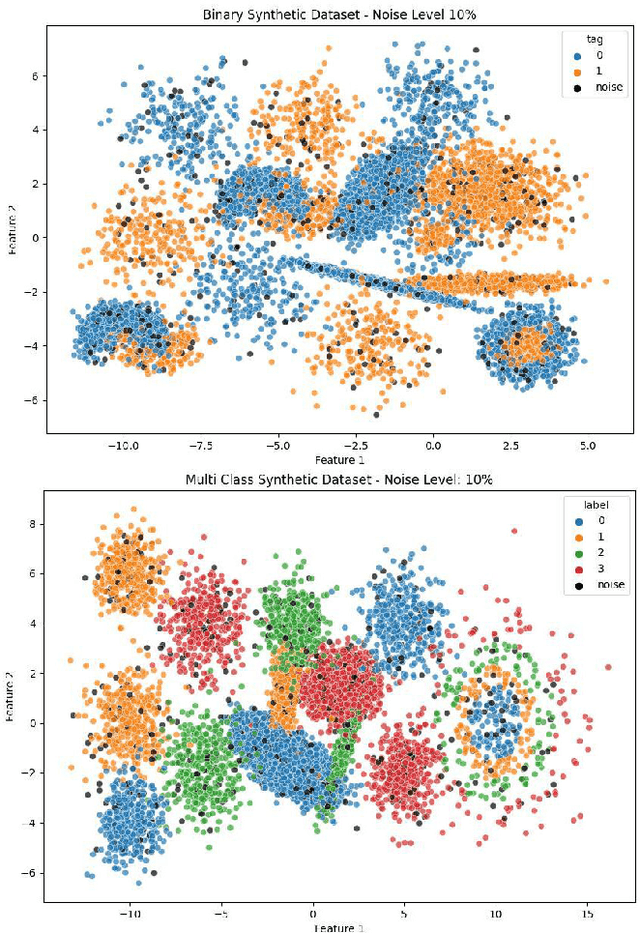
Real world datasets contain incorrectly labeled instances that hamper the performance of the model and, in particular, the ability to generalize out of distribution. Also, each example might have different contribution towards learning. This motivates studies to better understanding of the role of data instances with respect to their contribution in good metrics in models. In this paper we propose a method based on metrics computed from training dynamics of Gradient Boosting Decision Trees (GBDTs) to assess the behavior of each training example. We focus on datasets containing mostly tabular or structured data, for which the use of Decision Trees ensembles are still the state-of-the-art in terms of performance. We show results on detecting noisy labels in order to either remove them, improving models' metrics in synthetic and real datasets, as well as a productive dataset. Our methods achieved the best results overall when compared with confident learning and heuristics.
A single speaker is almost all you need for automatic speech recognition
Mar 29, 2022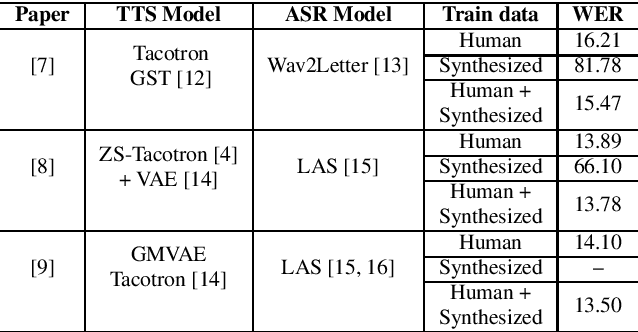
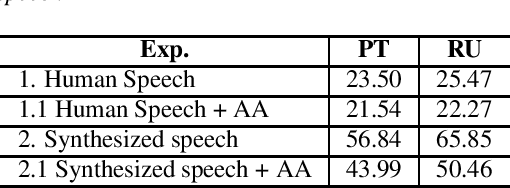

We explore the use of speech synthesis and voice conversion applied to augment datasets for automatic speech recognition (ASR) systems, in scenarios with only one speaker available for the target language. Through extensive experiments, we show that our approach achieves results compared to the state-of-the-art (SOTA) and requires only one speaker in the target language during speech synthesis/voice conversion model training. Finally, we show that it is possible to obtain promising results in the training of an ASR model with our data augmentation method and only a single real speaker in different target languages.
Implementing simple spectral denoising for environmental audio recordings
Jan 06, 2022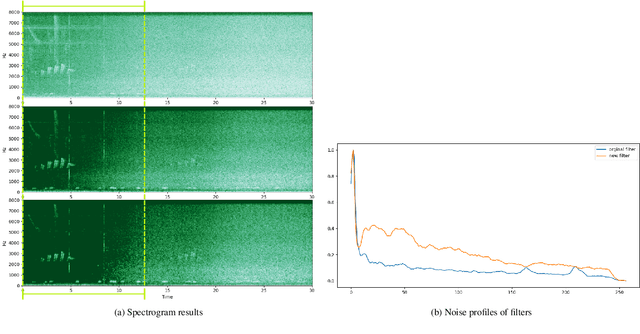
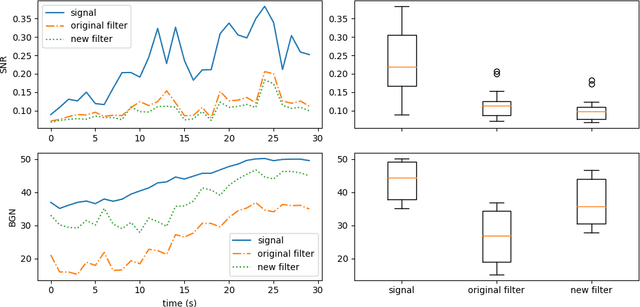
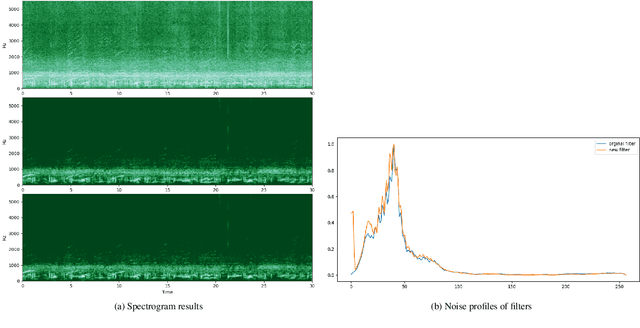
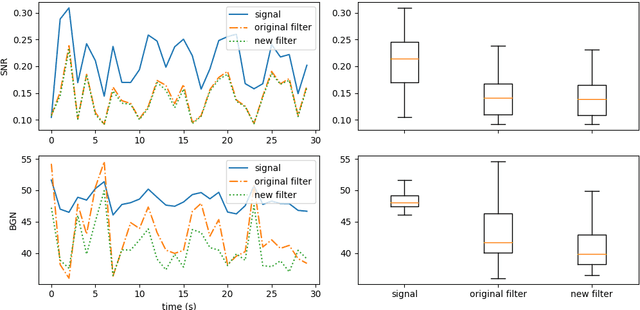
This technical report details changes applied to a noise filter to facilitate its application and improve its results. The filter is applied to denoise natural sounds recorded in the wild and to generate an acoustic index used in soundscape analysis.
YourTTS: Towards Zero-Shot Multi-Speaker TTS and Zero-Shot Voice Conversion for everyone
Dec 04, 2021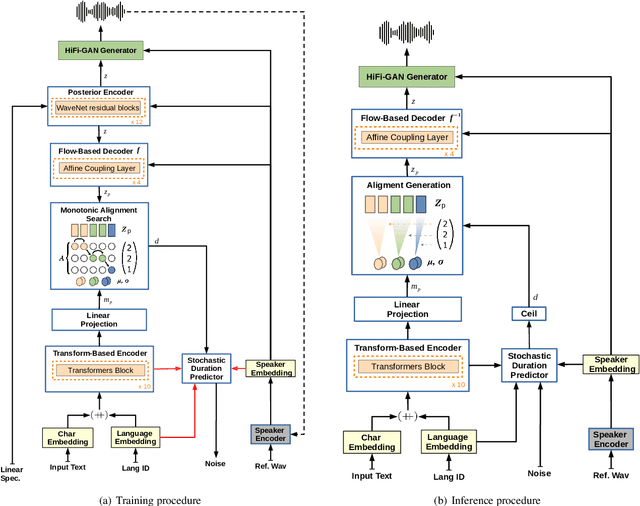
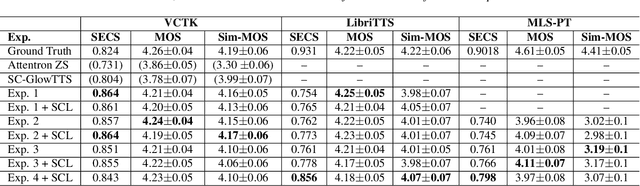

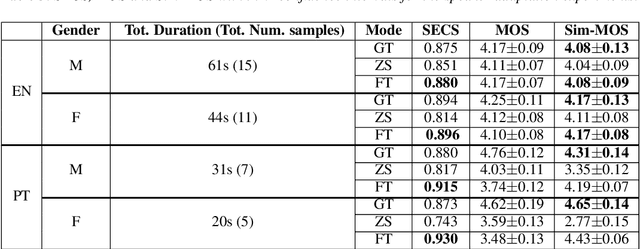
YourTTS brings the power of a multilingual approach to the task of zero-shot multi-speaker TTS. Our method builds upon the VITS model and adds several novel modifications for zero-shot multi-speaker and multilingual training. We achieved state-of-the-art (SOTA) results in zero-shot multi-speaker TTS and results comparable to SOTA in zero-shot voice conversion on the VCTK dataset. Additionally, our approach achieves promising results in a target language with a single-speaker dataset, opening possibilities for zero-shot multi-speaker TTS and zero-shot voice conversion systems in low-resource languages. Finally, it is possible to fine-tune the YourTTS model with less than 1 minute of speech and achieve state-of-the-art results in voice similarity and with reasonable quality. This is important to allow synthesis for speakers with a very different voice or recording characteristics from those seen during training.
Training Deep Networks from Zero to Hero: avoiding pitfalls and going beyond
Sep 06, 2021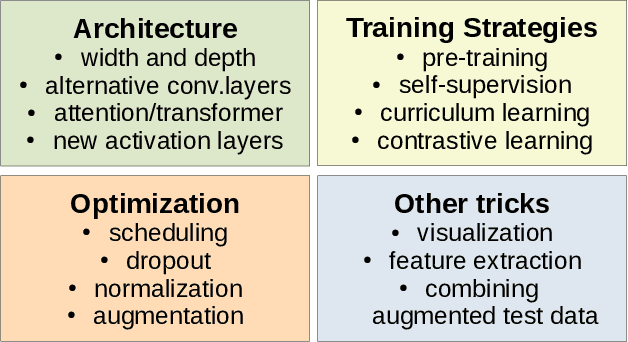
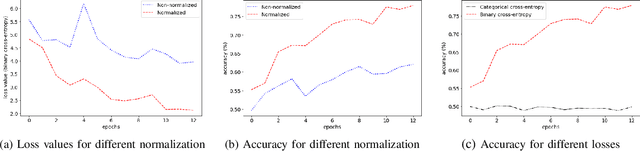
Training deep neural networks may be challenging in real world data. Using models as black-boxes, even with transfer learning, can result in poor generalization or inconclusive results when it comes to small datasets or specific applications. This tutorial covers the basic steps as well as more recent options to improve models, in particular, but not restricted to, supervised learning. It can be particularly useful in datasets that are not as well-prepared as those in challenges, and also under scarce annotation and/or small data. We describe basic procedures: as data preparation, optimization and transfer learning, but also recent architectural choices such as use of transformer modules, alternative convolutional layers, activation functions, wide and deep networks, as well as training procedures including as curriculum, contrastive and self-supervised learning.
SC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
Apr 02, 2021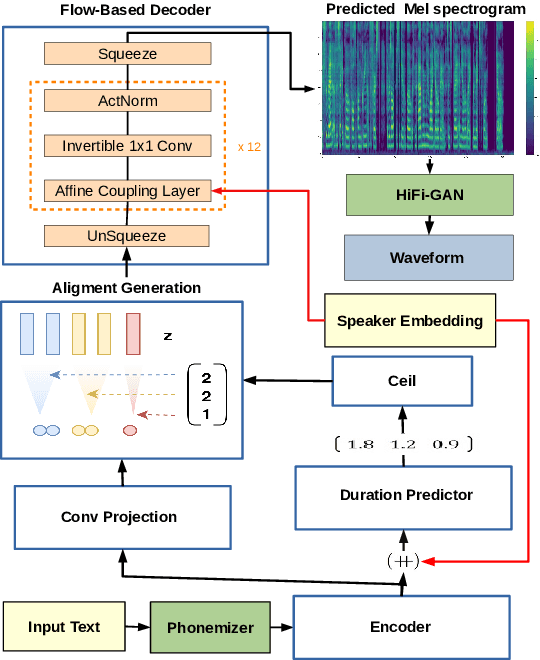
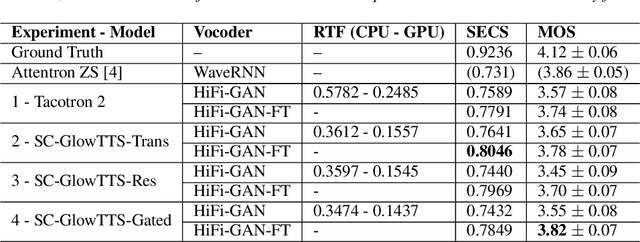
In this paper, we propose SC-GlowTTS: an efficient zero-shot multi-speaker text-to-speech model that improves similarity for speakers unseen in training. We propose a speaker-conditional architecture that explores a flow-based decoder that works in a zero-shot scenario. As text encoders, we explore a dilated residual convolutional-based encoder, gated convolutional-based encoder, and transformer-based encoder. Additionally, we have shown that adjusting a GAN-based vocoder for the spectrograms predicted by the TTS model on the training dataset can significantly improve the similarity and speech quality for new speakers. Our model is able to converge in training, using only 11 speakers, reaching state-of-the-art results for similarity with new speakers, as well as high speech quality.