 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMohammad Sabokrou
Class-Adaptive Sampling Policy for Efficient Continual Learning
Nov 27, 2023
Continual learning (CL) aims to acquire new knowledge while preserving information from previous experiences without forgetting. Though buffer-based methods (i.e., retaining samples from previous tasks) have achieved acceptable performance, determining how to allocate the buffer remains a critical challenge. Most recent research focuses on refining these methods but often fails to sufficiently consider the varying influence of samples on the learning process, and frequently overlooks the complexity of the classes/concepts being learned. Generally, these methods do not directly take into account the contribution of individual classes. However, our investigation indicates that more challenging classes necessitate preserving a larger number of samples compared to less challenging ones. To address this issue, we propose a novel method and policy named 'Class-Adaptive Sampling Policy' (CASP), which dynamically allocates storage space within the buffer. By utilizing concepts of class contribution and difficulty, CASP adaptively manages buffer space, allowing certain classes to occupy a larger portion of the buffer while reducing storage for others. This approach significantly improves the efficiency of knowledge retention and utilization. CASP provides a versatile solution to boost the performance and efficiency of CL. It meets the demand for dynamic buffer allocation, accommodating the varying contributions of different classes and their learning complexities over time.
Explainability of Vision Transformers: A Comprehensive Review and New Perspectives
Nov 12, 2023Transformers have had a significant impact on natural language processing and have recently demonstrated their potential in computer vision. They have shown promising results over convolution neural networks in fundamental computer vision tasks. However, the scientific community has not fully grasped the inner workings of vision transformers, nor the basis for their decision-making, which underscores the importance of explainability methods. Understanding how these models arrive at their decisions not only improves their performance but also builds trust in AI systems. This study explores different explainability methods proposed for visual transformers and presents a taxonomy for organizing them according to their motivations, structures, and application scenarios. In addition, it provides a comprehensive review of evaluation criteria that can be used for comparing explanation results, as well as explainability tools and frameworks. Finally, the paper highlights essential but unexplored aspects that can enhance the explainability of visual transformers, and promising research directions are suggested for future investment.
Mitigating Bias: Enhancing Image Classification by Improving Model Explanations
Jul 10, 2023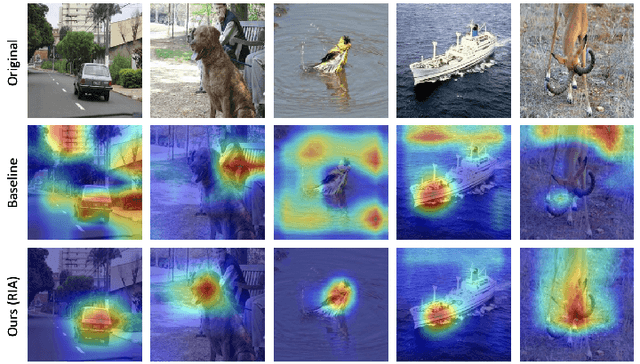

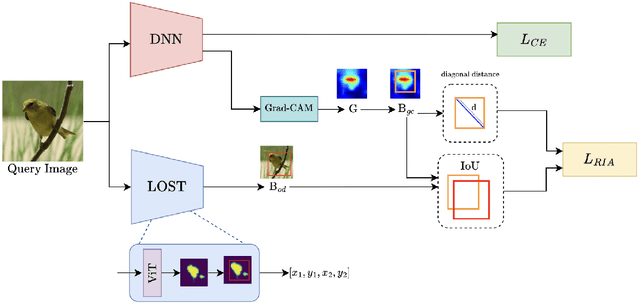

Deep learning models have demonstrated remarkable capabilities in learning complex patterns and concepts from training data. However, recent findings indicate that these models tend to rely heavily on simple and easily discernible features present in the background of images rather than the main concepts or objects they are intended to classify. This phenomenon poses a challenge to image classifiers as the crucial elements of interest in images may be overshadowed. In this paper, we propose a novel approach to address this issue and improve the learning of main concepts by image classifiers. Our central idea revolves around concurrently guiding the model's attention toward the foreground during the classification task. By emphasizing the foreground, which encapsulates the primary objects of interest, we aim to shift the focus of the model away from the dominant influence of the background. To accomplish this, we introduce a mechanism that encourages the model to allocate sufficient attention to the foreground. We investigate various strategies, including modifying the loss function or incorporating additional architectural components, to enable the classifier to effectively capture the primary concept within an image. Additionally, we explore the impact of different foreground attention mechanisms on model performance and provide insights into their effectiveness. Through extensive experimentation on benchmark datasets, we demonstrate the efficacy of our proposed approach in improving the classification accuracy of image classifiers. Our findings highlight the importance of foreground attention in enhancing model understanding and representation of the main concepts within images. The results of this study contribute to advancing the field of image classification and provide valuable insights for developing more robust and accurate deep-learning models.
IMPOSITION: Implicit Backdoor Attack through Scenario Injection
Jun 27, 2023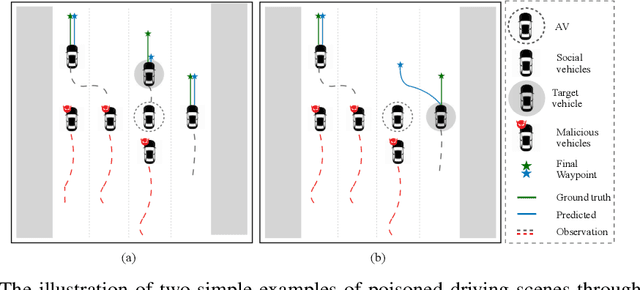
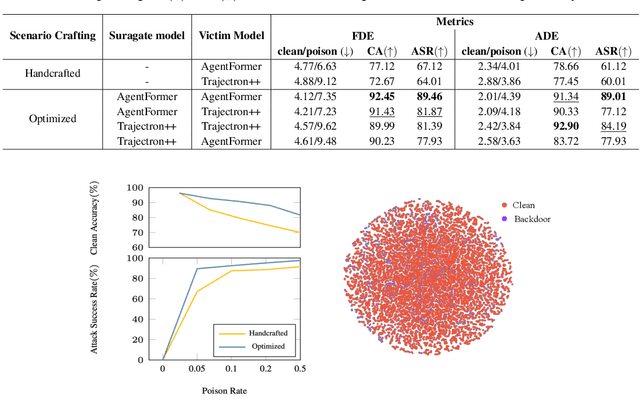

This paper presents a novel backdoor attack called IMPlicit BackdOor Attack through Scenario InjecTION (IMPOSITION) that does not require direct poisoning of the training data. Instead, the attack leverages a realistic scenario from the training data as a trigger to manipulate the model's output during inference. This type of attack is particularly dangerous as it is stealthy and difficult to detect. The paper focuses on the application of this attack in the context of Autonomous Driving (AD) systems, specifically targeting the trajectory prediction module. To implement the attack, we design a trigger mechanism that mimics a set of cloned behaviors in the driving scene, resulting in a scenario that triggers the attack. The experimental results demonstrate that IMPOSITION is effective in attacking trajectory prediction models while maintaining high performance in untargeted scenarios. Our proposed method highlights the growing importance of research on the trustworthiness of Deep Neural Network (DNN) models, particularly in safety-critical applications. Backdoor attacks pose a significant threat to the safety and reliability of DNN models, and this paper presents a new perspective on backdooring DNNs. The proposed IMPOSITION paradigm and the demonstration of its severity in the context of AD systems are significant contributions of this paper. We highlight the impact of the proposed attacks via empirical studies showing how IMPOSITION can easily compromise the safety of AD systems.
Global-Local Processing in Convolutional Neural Networks
Jun 14, 2023
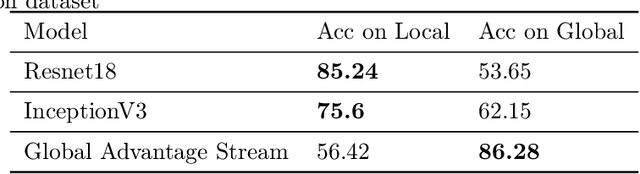
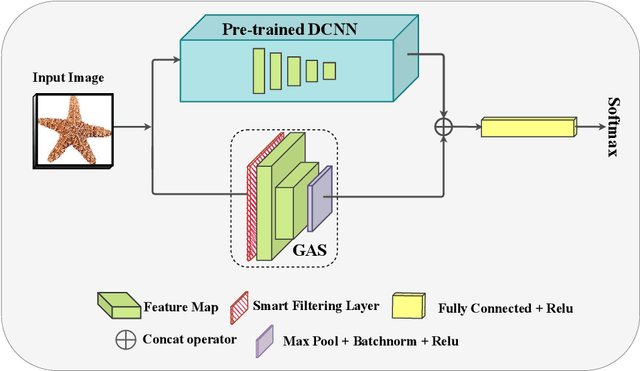
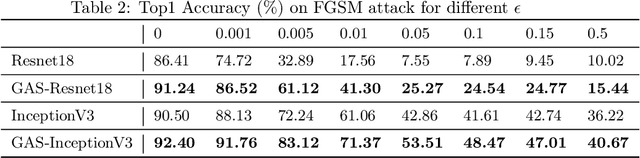
Convolutional Neural Networks (CNNs) have achieved outstanding performance on image processing challenges. Actually, CNNs imitate the typically developed human brain structures at the micro-level (Artificial neurons). At the same time, they distance themselves from imitating natural visual perception in humans at the macro architectures (high-level cognition). Recently it has been investigated that CNNs are highly biased toward local features and fail to detect the global aspects of their input. Nevertheless, the literature offers limited clues on this problem. To this end, we propose a simple yet effective solution inspired by the unconscious behavior of the human pupil. We devise a simple module called Global Advantage Stream (GAS) to learn and capture the holistic features of input samples (i.e., the global features). Then, the GAS features were combined with a CNN network as a plug-and-play component called the Global/Local Processing (GLP) model. The experimental results confirm that this stream improves the accuracy with an insignificant additional computational/temporal load and makes the network more robust to adversarial attacks. Furthermore, investigating the interpretation of the model shows that it learns a more holistic representation similar to the perceptual system of healthy humans
Revealing Model Biases: Assessing Deep Neural Networks via Recovered Sample Analysis
Jun 10, 2023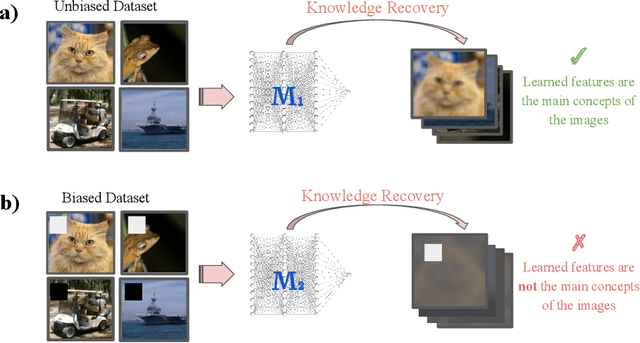



This paper proposes a straightforward and cost-effective approach to assess whether a deep neural network (DNN) relies on the primary concepts of training samples or simply learns discriminative, yet simple and irrelevant features that can differentiate between classes. The paper highlights that DNNs, as discriminative classifiers, often find the simplest features to discriminate between classes, leading to a potential bias towards irrelevant features and sometimes missing generalization. While a generalization test is one way to evaluate a trained model's performance, it can be costly and may not cover all scenarios to ensure that the model has learned the primary concepts. Furthermore, even after conducting a generalization test, identifying bias in the model may not be possible. Here, the paper proposes a method that involves recovering samples from the parameters of the trained model and analyzing the reconstruction quality. We believe that if the model's weights are optimized to discriminate based on some features, these features will be reflected in the reconstructed samples. If the recovered samples contain the primary concepts of the training data, it can be concluded that the model has learned the essential and determining features. On the other hand, if the recovered samples contain irrelevant features, it can be concluded that the model is biased towards these features. The proposed method does not require any test or generalization samples, only the parameters of the trained model and the training data that lie on the margin. Our experiments demonstrate that the proposed method can determine whether the model has learned the desired features of the training data. The paper highlights that our understanding of how these models work is limited, and the proposed approach addresses this issue.
Expanding Explainability Horizons: A Unified Concept-Based System for Local, Global, and Misclassification Explanations
Jun 06, 2023
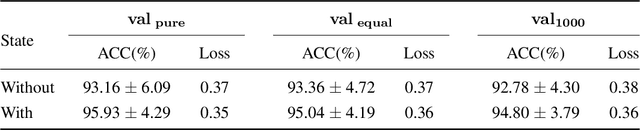


Explainability of intelligent models has been garnering increasing attention in recent years. Of the various explainability approaches, concept-based techniques are notable for utilizing a set of human-meaningful concepts instead of focusing on individual pixels. However, there is a scarcity of methods that consistently provide both local and global explanations. Moreover, most of the methods have no offer to explain misclassification cases. To address these challenges, our study follows a straightforward yet effective approach. We propose a unified concept-based system, which inputs a number of super-pixelated images into the networks, allowing them to learn better representations of the target's objects as well as the target's concepts. This method automatically learns, scores, and extracts local and global concepts. Our experiments revealed that, in addition to enhancing performance, the models could provide deeper insights into predictions and elucidate false classifications.
Quantifying Overfitting: Evaluating Neural Network Performance through Analysis of Null Space
May 30, 2023
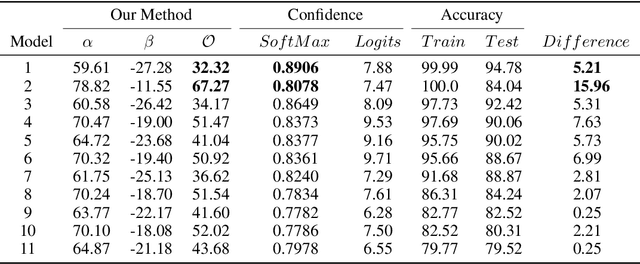
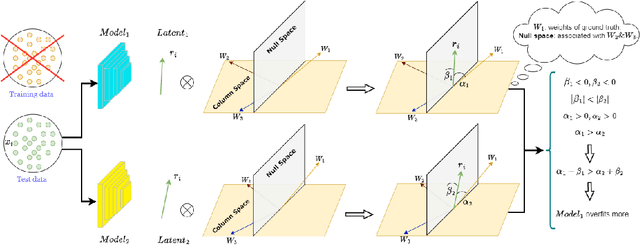
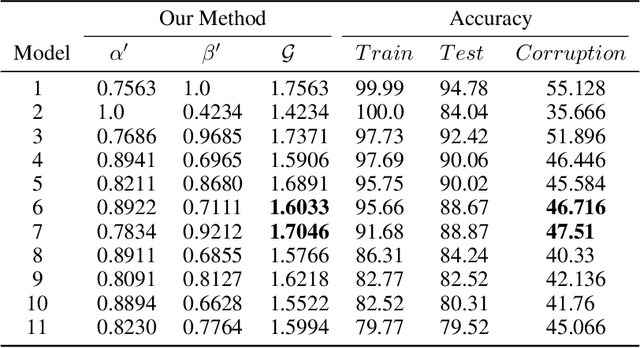
Machine learning models that are overfitted/overtrained are more vulnerable to knowledge leakage, which poses a risk to privacy. Suppose we download or receive a model from a third-party collaborator without knowing its training accuracy. How can we determine if it has been overfitted or overtrained on its training data? It's possible that the model was intentionally over-trained to make it vulnerable during testing. While an overfitted or overtrained model may perform well on testing data and even some generalization tests, we can't be sure it's not over-fitted. Conducting a comprehensive generalization test is also expensive. The goal of this paper is to address these issues and ensure the privacy and generalization of our method using only testing data. To achieve this, we analyze the null space in the last layer of neural networks, which enables us to quantify overfitting without access to training data or knowledge of the accuracy of those data. We evaluated our approach on various architectures and datasets and observed a distinct pattern in the angle of null space when models are overfitted. Furthermore, we show that models with poor generalization exhibit specific characteristics in this space. Our work represents the first attempt to quantify overfitting without access to training data or knowing any knowledge about the training samples.
Are Out-of-Distribution Detection Methods Reliable?
Nov 20, 2022
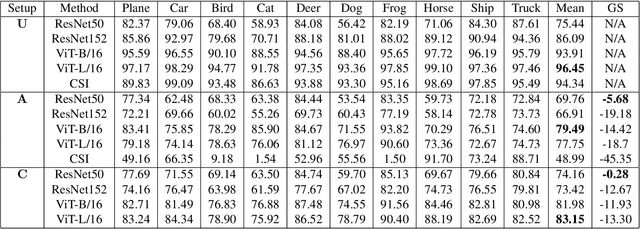
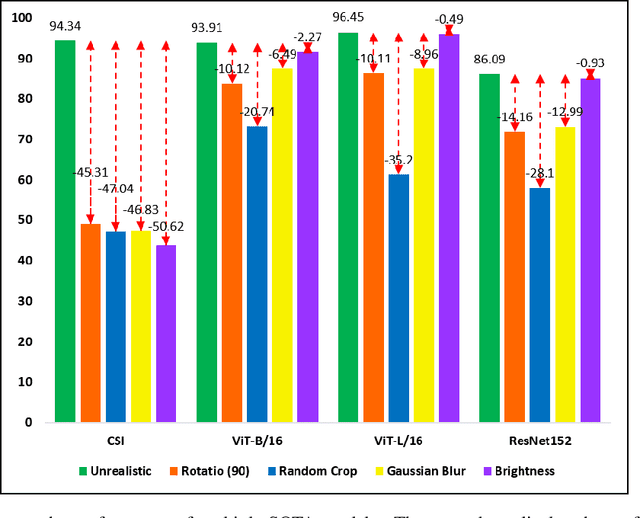
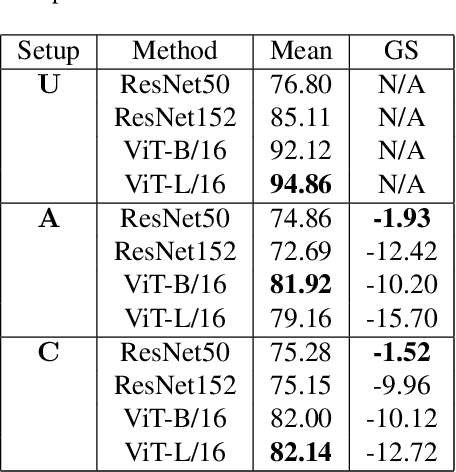
This paper establishes a novel evaluation framework for assessing the performance of out-of-distribution (OOD) detection in realistic settings. Our goal is to expose the shortcomings of existing OOD detection benchmarks and encourage a necessary research direction shift toward satisfying the requirements of real-world applications. We expand OOD detection research by introducing new OOD test datasets CIFAR-10-R, CIFAR-100-R, and MVTec-R, which allow researchers to benchmark OOD detection performance under realistic distribution shifts. We also introduce a generalizability score to measure a method's ability to generalize from standard OOD detection test datasets to a realistic setting. Contrary to existing OOD detection research, we demonstrate that further performance improvements on standard benchmark datasets do not increase the usability of such models in the real world. State-of-the-art (SOTA) methods tested on our realistic distributionally-shifted datasets drop in performance for up to 45%. This setting is critical for evaluating the reliability of OOD models before they are deployed in real-world environments.
MobileDenseNet: A new approach to object detection on mobile devices
Jul 22, 2022

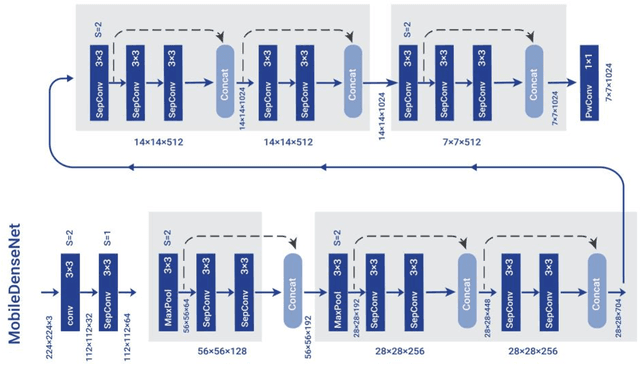
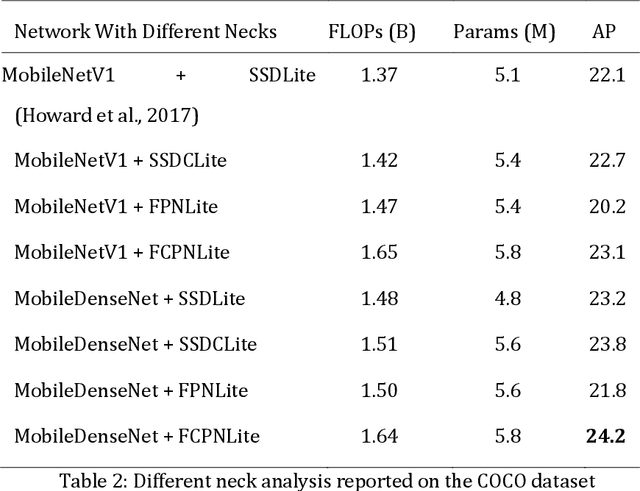
Object detection problem solving has developed greatly within the past few years. There is a need for lighter models in instances where hardware limitations exist, as well as a demand for models to be tailored to mobile devices. In this article, we will assess the methods used when creating algorithms that address these issues. The main goal of this article is to increase accuracy in state-of-the-art algorithms while maintaining speed and real-time efficiency. The most significant issues in one-stage object detection pertains to small objects and inaccurate localization. As a solution, we created a new network by the name of MobileDenseNet suitable for embedded systems. We also developed a light neck FCPNLite for mobile devices that will aid with the detection of small objects. Our research revealed that very few papers cited necks in embedded systems. What differentiates our network from others is our use of concatenation features. A small yet significant change to the head of the network amplified accuracy without increasing speed or limiting parameters. In short, our focus on the challenging CoCo and Pascal VOC datasets were 24.8 and 76.8 in percentage terms respectively - a rate higher than that recorded by other state-of-the-art systems thus far. Our network is able to increase accuracy while maintaining real-time efficiency on mobile devices. We calculated operational speed on Pixel 3 (Snapdragon 845) to 22.8 fps. The source code of this research is available on https://github.com/hajizadeh/MobileDenseNet.