 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMohammad Salameh
Incorporating Explanations into Human-Machine Interfaces for Trust and Situation Awareness in Autonomous Vehicles
Apr 10, 2024
Autonomous vehicles often make complex decisions via machine learning-based predictive models applied to collected sensor data. While this combination of methods provides a foundation for real-time actions, self-driving behavior primarily remains opaque to end users. In this sense, explainability of real-time decisions is a crucial and natural requirement for building trust in autonomous vehicles. Moreover, as autonomous vehicles still cause serious traffic accidents for various reasons, timely conveyance of upcoming hazards to road users can help improve scene understanding and prevent potential risks. Hence, there is also a need to supply autonomous vehicles with user-friendly interfaces for effective human-machine teaming. Motivated by this problem, we study the role of explainable AI and human-machine interface jointly in building trust in vehicle autonomy. We first present a broad context of the explanatory human-machine systems with the "3W1H" (what, whom, when, how) approach. Based on these findings, we present a situation awareness framework for calibrating users' trust in self-driving behavior. Finally, we perform an experiment on our framework, conduct a user study on it, and validate the empirical findings with hypothesis testing.
Building Optimal Neural Architectures using Interpretable Knowledge
Mar 20, 2024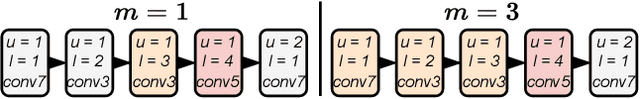


Neural Architecture Search is a costly practice. The fact that a search space can span a vast number of design choices with each architecture evaluation taking nontrivial overhead makes it hard for an algorithm to sufficiently explore candidate networks. In this paper, we propose AutoBuild, a scheme which learns to align the latent embeddings of operations and architecture modules with the ground-truth performance of the architectures they appear in. By doing so, AutoBuild is capable of assigning interpretable importance scores to architecture modules, such as individual operation features and larger macro operation sequences such that high-performance neural networks can be constructed without any need for search. Through experiments performed on state-of-the-art image classification, segmentation, and Stable Diffusion models, we show that by mining a relatively small set of evaluated architectures, AutoBuild can learn to build high-quality architectures directly or help to reduce search space to focus on relevant areas, finding better architectures that outperform both the original labeled ones and ones found by search baselines. Code available at https://github.com/Ascend-Research/AutoBuild
Safety Implications of Explainable Artificial Intelligence in End-to-End Autonomous Driving
Mar 18, 2024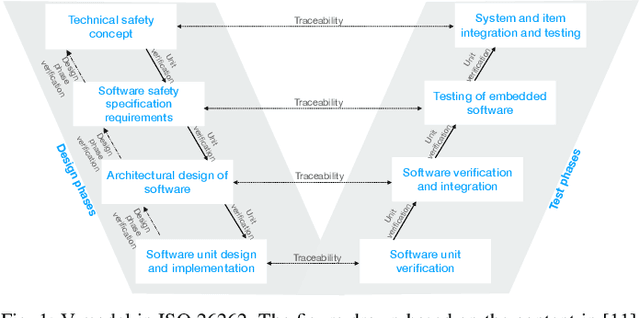



The end-to-end learning pipeline is gradually creating a paradigm shift in the ongoing development of highly autonomous vehicles, largely due to advances in deep learning, the availability of large-scale training datasets, and improvements in integrated sensor devices. However, a lack of interpretability in real-time decisions with contemporary learning methods impedes user trust and attenuates the widespread deployment and commercialization of such vehicles. Moreover, the issue is exacerbated when these cars are involved in or cause traffic accidents. Such drawback raises serious safety concerns from societal and legal perspectives. Consequently, explainability in end-to-end autonomous driving is essential to enable the safety of vehicular automation. However, the safety and explainability aspects of autonomous driving have generally been investigated disjointly by researchers in today's state of the art. In this paper, we aim to bridge the gaps between these topics and seek to answer the following research question: When and how can explanations improve safety of autonomous driving? In this regard, we first revisit established safety and state-of-the-art explainability techniques in autonomous driving. Furthermore, we present three critical case studies and show the pivotal role of explanations in enhancing self-driving safety. Finally, we describe our empirical investigation and reveal potential value, limitations, and caveats with practical explainable AI methods on their role of assuring safety and transparency for vehicle autonomy.
CascadedGaze: Efficiency in Global Context Extraction for Image Restoration
Jan 26, 2024Image restoration tasks traditionally rely on convolutional neural networks. However, given the local nature of the convolutional operator, they struggle to capture global information. The promise of attention mechanisms in Transformers is to circumvent this problem, but it comes at the cost of intensive computational overhead. Many recent studies in image restoration have focused on solving the challenge of balancing performance and computational cost via Transformer variants. In this paper, we present CascadedGaze Network (CGNet), an encoder-decoder architecture that employs Global Context Extractor (GCE), a novel and efficient way to capture global information for image restoration. The GCE module leverages small kernels across convolutional layers to learn global dependencies, without requiring self-attention. Extensive experimental results show that our approach outperforms a range of state-of-the-art methods on denoising benchmark datasets including both real image denoising and synthetic image denoising, as well as on image deblurring task, while being more computationally efficient.
Explaining Autonomous Driving Actions with Visual Question Answering
Jul 19, 2023
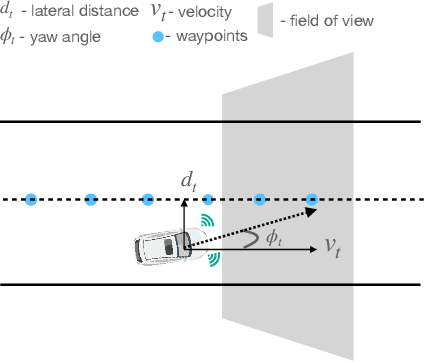
The end-to-end learning ability of self-driving vehicles has achieved significant milestones over the last decade owing to rapid advances in deep learning and computer vision algorithms. However, as autonomous driving technology is a safety-critical application of artificial intelligence (AI), road accidents and established regulatory principles necessitate the need for the explainability of intelligent action choices for self-driving vehicles. To facilitate interpretability of decision-making in autonomous driving, we present a Visual Question Answering (VQA) framework, which explains driving actions with question-answering-based causal reasoning. To do so, we first collect driving videos in a simulation environment using reinforcement learning (RL) and extract consecutive frames from this log data uniformly for five selected action categories. Further, we manually annotate the extracted frames using question-answer pairs as justifications for the actions chosen in each scenario. Finally, we evaluate the correctness of the VQA-predicted answers for actions on unseen driving scenes. The empirical results suggest that the VQA mechanism can provide support to interpret real-time decisions of autonomous vehicles and help enhance overall driving safety.
Reparameterization through Spatial Gradient Scaling
Mar 07, 2023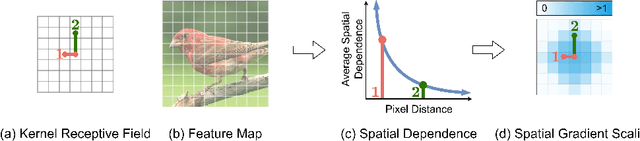
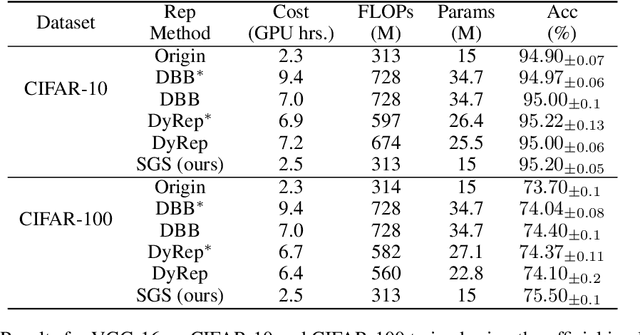
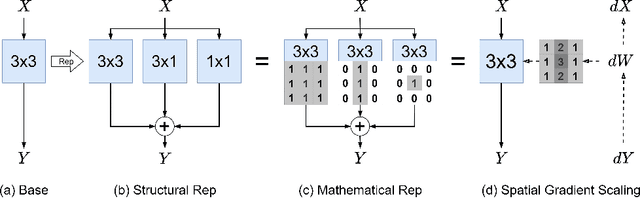
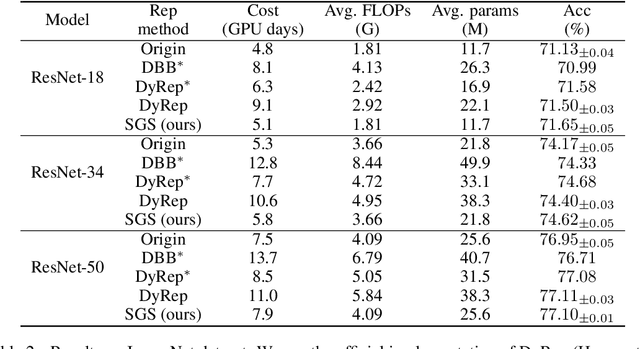
Reparameterization aims to improve the generalization of deep neural networks by transforming convolutional layers into equivalent multi-branched structures during training. However, there exists a gap in understanding how reparameterization may change and benefit the learning process of neural networks. In this paper, we present a novel spatial gradient scaling method to redistribute learning focus among weights in convolutional networks. We prove that spatial gradient scaling achieves the same learning dynamics as a branched reparameterization yet without introducing structural changes into the network. We further propose an analytical approach that dynamically learns scalings for each convolutional layer based on the spatial characteristics of its input feature map gauged by mutual information. Experiments on CIFAR-10, CIFAR-100, and ImageNet show that without searching for reparameterized structures, our proposed scaling method outperforms the state-of-the-art reparameterization strategies at a lower computational cost.
A General-Purpose Transferable Predictor for Neural Architecture Search
Feb 21, 2023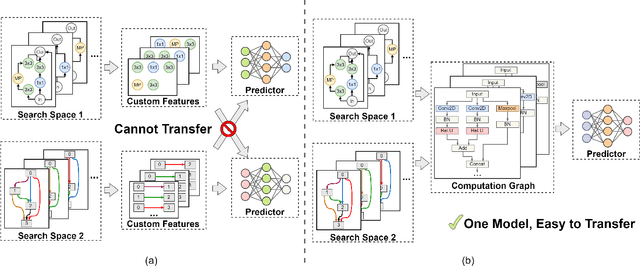
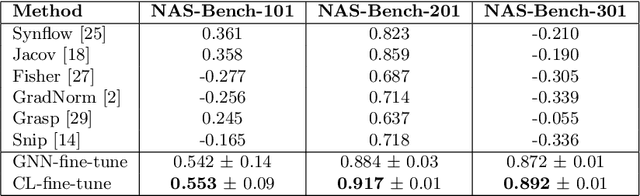

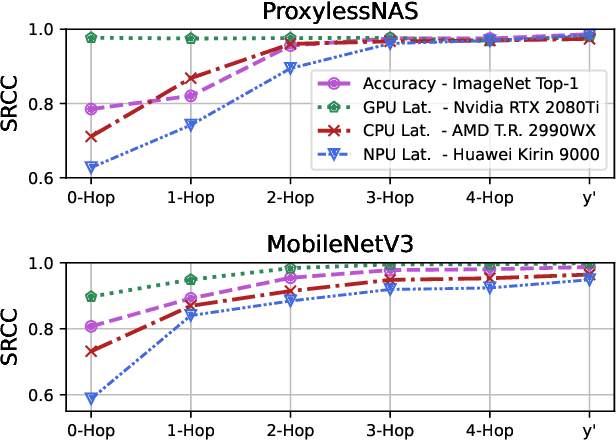
Understanding and modelling the performance of neural architectures is key to Neural Architecture Search (NAS). Performance predictors have seen widespread use in low-cost NAS and achieve high ranking correlations between predicted and ground truth performance in several NAS benchmarks. However, existing predictors are often designed based on network encodings specific to a predefined search space and are therefore not generalizable to other search spaces or new architecture families. In this paper, we propose a general-purpose neural predictor for NAS that can transfer across search spaces, by representing any given candidate Convolutional Neural Network (CNN) with a Computation Graph (CG) that consists of primitive operators. We further combine our CG network representation with Contrastive Learning (CL) and propose a graph representation learning procedure that leverages the structural information of unlabeled architectures from multiple families to train CG embeddings for our performance predictor. Experimental results on NAS-Bench-101, 201 and 301 demonstrate the efficacy of our scheme as we achieve strong positive Spearman Rank Correlation Coefficient (SRCC) on every search space, outperforming several Zero-Cost Proxies, including Synflow and Jacov, which are also generalizable predictors across search spaces. Moreover, when using our proposed general-purpose predictor in an evolutionary neural architecture search algorithm, we can find high-performance architectures on NAS-Bench-101 and find a MobileNetV3 architecture that attains 79.2% top-1 accuracy on ImageNet.
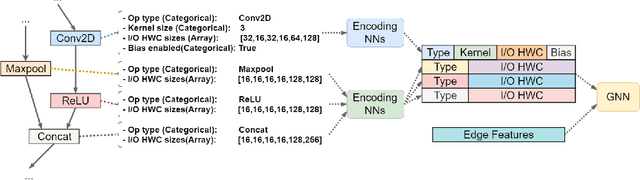
GENNAPE: Towards Generalized Neural Architecture Performance Estimators
Nov 30, 2022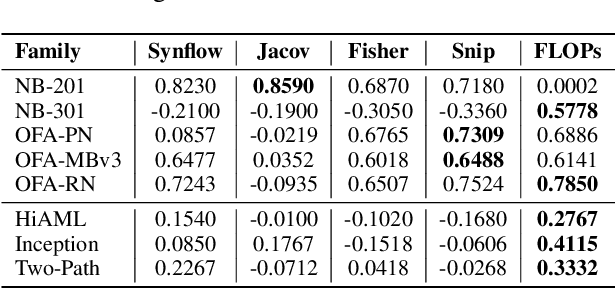
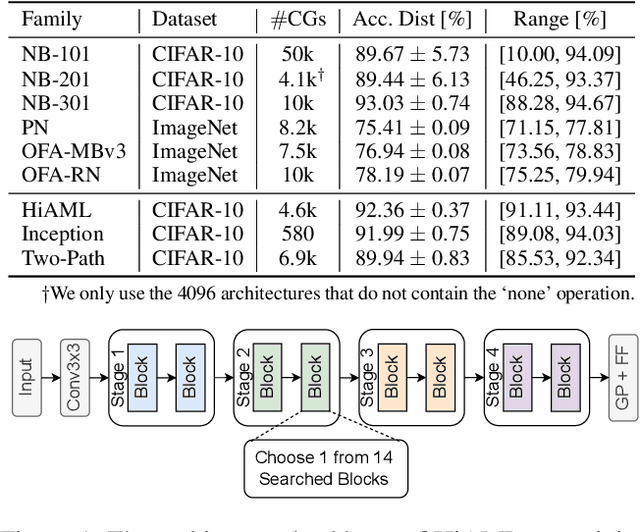
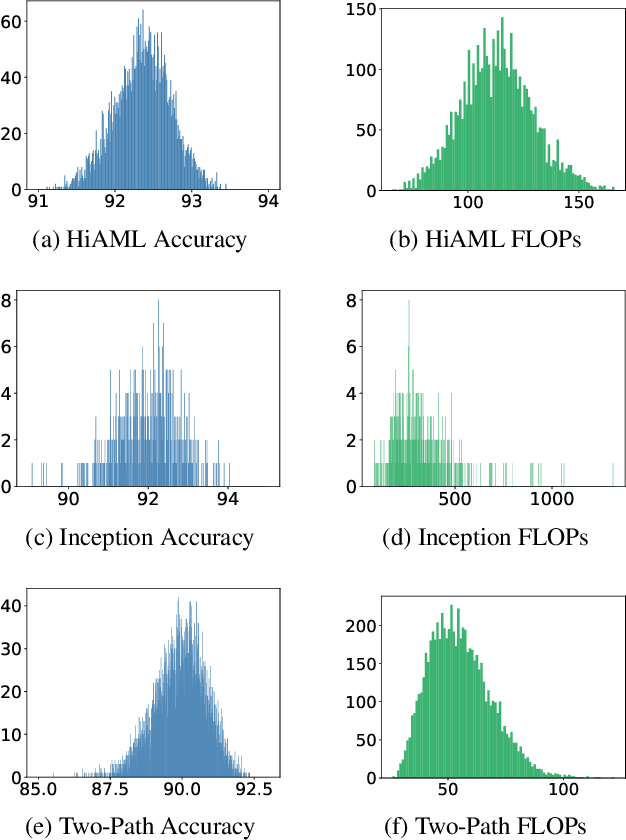
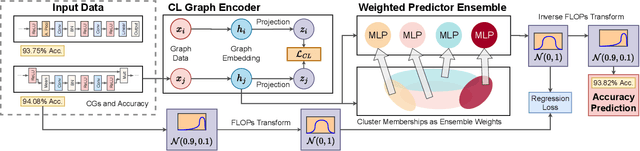
Predicting neural architecture performance is a challenging task and is crucial to neural architecture design and search. Existing approaches either rely on neural performance predictors which are limited to modeling architectures in a predefined design space involving specific sets of operators and connection rules, and cannot generalize to unseen architectures, or resort to zero-cost proxies which are not always accurate. In this paper, we propose GENNAPE, a Generalized Neural Architecture Performance Estimator, which is pretrained on open neural architecture benchmarks, and aims to generalize to completely unseen architectures through combined innovations in network representation, contrastive pretraining, and fuzzy clustering-based predictor ensemble. Specifically, GENNAPE represents a given neural network as a Computation Graph (CG) of atomic operations which can model an arbitrary architecture. It first learns a graph encoder via Contrastive Learning to encourage network separation by topological features, and then trains multiple predictor heads, which are soft-aggregated according to the fuzzy membership of a neural network. Experiments show that GENNAPE pretrained on NAS-Bench-101 can achieve superior transferability to 5 different public neural network benchmarks, including NAS-Bench-201, NAS-Bench-301, MobileNet and ResNet families under no or minimum fine-tuning. We further introduce 3 challenging newly labelled neural network benchmarks: HiAML, Inception and Two-Path, which can concentrate in narrow accuracy ranges. Extensive experiments show that GENNAPE can correctly discern high-performance architectures in these families. Finally, when paired with a search algorithm, GENNAPE can find architectures that improve accuracy while reducing FLOPs on three families.
AIO-P: Expanding Neural Performance Predictors Beyond Image Classification
Nov 30, 2022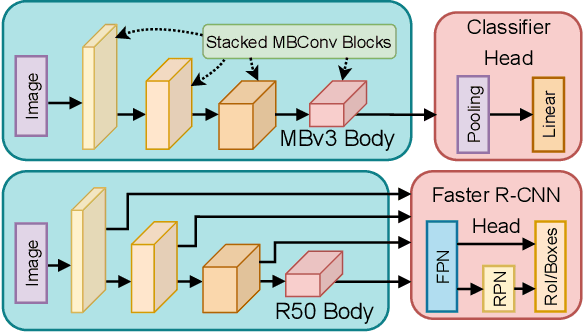
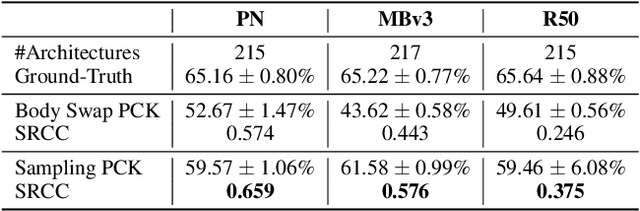
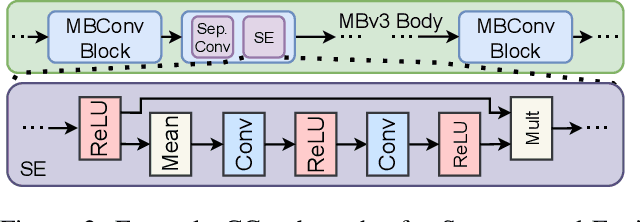
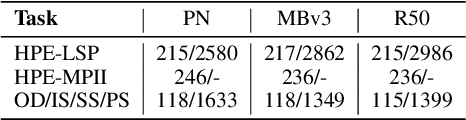
Evaluating neural network performance is critical to deep neural network design but a costly procedure. Neural predictors provide an efficient solution by treating architectures as samples and learning to estimate their performance on a given task. However, existing predictors are task-dependent, predominantly estimating neural network performance on image classification benchmarks. They are also search-space dependent; each predictor is designed to make predictions for a specific architecture search space with predefined topologies and set of operations. In this paper, we propose a novel All-in-One Predictor (AIO-P), which aims to pretrain neural predictors on architecture examples from multiple, separate computer vision (CV) task domains and multiple architecture spaces, and then transfer to unseen downstream CV tasks or neural architectures. We describe our proposed techniques for general graph representation, efficient predictor pretraining and knowledge infusion techniques, as well as methods to transfer to downstream tasks/spaces. Extensive experimental results show that AIO-P can achieve Mean Absolute Error (MAE) and Spearman's Rank Correlation (SRCC) below 1% and above 0.5, respectively, on a breadth of target downstream CV tasks with or without fine-tuning, outperforming a number of baselines. Moreover, AIO-P can directly transfer to new architectures not seen during training, accurately rank them and serve as an effective performance estimator when paired with an algorithm designed to preserve performance while reducing FLOPs.
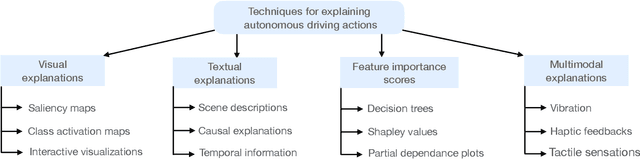
Explainable Artificial Intelligence for Autonomous Driving: A Comprehensive Overview and Field Guide for Future Research Directions
Dec 21, 2021
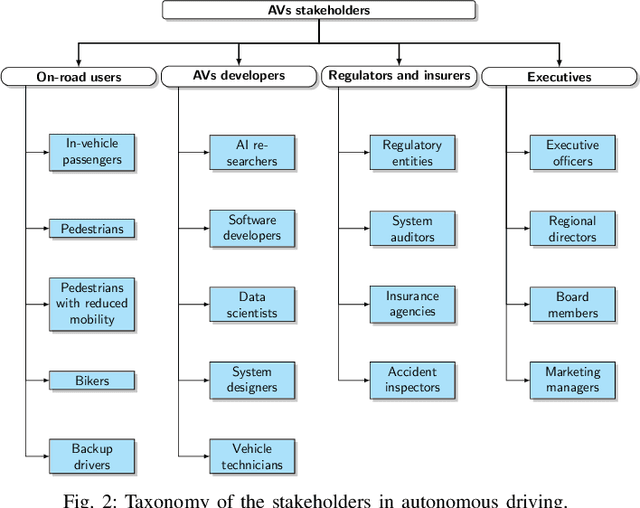

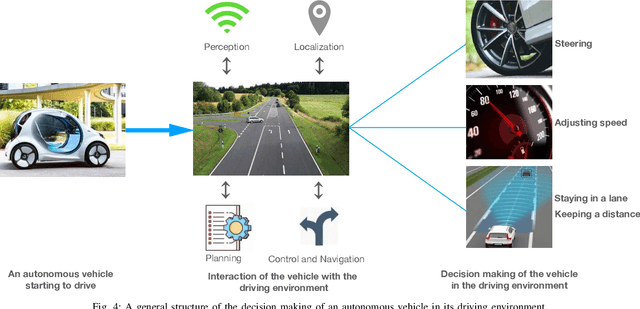
Autonomous driving has achieved a significant milestone in research and development over the last decade. There is increasing interest in the field as the deployment of self-operating vehicles on roads promises safer and more ecologically friendly transportation systems. With the rise of computationally powerful artificial intelligence (AI) techniques, autonomous vehicles can sense their environment with high precision, make safe real-time decisions, and operate more reliably without human interventions. However, intelligent decision-making in autonomous cars is not generally understandable by humans in the current state of the art, and such deficiency hinders this technology from being socially acceptable. Hence, aside from making safe real-time decisions, the AI systems of autonomous vehicles also need to explain how these decisions are constructed in order to be regulatory compliant across many jurisdictions. Our study sheds a comprehensive light on developing explainable artificial intelligence (XAI) approaches for autonomous vehicles. In particular, we make the following contributions. First, we provide a thorough overview of the present gaps with respect to explanations in the state-of-the-art autonomous vehicle industry. We then show the taxonomy of explanations and explanation receivers in this field. Thirdly, we propose a framework for an architecture of end-to-end autonomous driving systems and justify the role of XAI in both debugging and regulating such systems. Finally, as future research directions, we provide a field guide on XAI approaches for autonomous driving that can improve operational safety and transparency towards achieving public approval by regulators, manufacturers, and all engaged stakeholders.