 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMohsen Ali
Domain Adaptive Object Detection via Balancing Between Self-Training and Adversarial Learning
Nov 08, 2023
Deep learning based object detectors struggle generalizing to a new target domain bearing significant variations in object and background. Most current methods align domains by using image or instance-level adversarial feature alignment. This often suffers due to unwanted background and lacks class-specific alignment. A straightforward approach to promote class-level alignment is to use high confidence predictions on unlabeled domain as pseudo-labels. These predictions are often noisy since model is poorly calibrated under domain shift. In this paper, we propose to leverage model's predictive uncertainty to strike the right balance between adversarial feature alignment and class-level alignment. We develop a technique to quantify predictive uncertainty on class assignments and bounding-box predictions. Model predictions with low uncertainty are used to generate pseudo-labels for self-training, whereas the ones with higher uncertainty are used to generate tiles for adversarial feature alignment. This synergy between tiling around uncertain object regions and generating pseudo-labels from highly certain object regions allows capturing both image and instance-level context during the model adaptation. We report thorough ablation study to reveal the impact of different components in our approach. Results on five diverse and challenging adaptation scenarios show that our approach outperforms existing state-of-the-art methods with noticeable margins.
Cal-DETR: Calibrated Detection Transformer
Nov 06, 2023
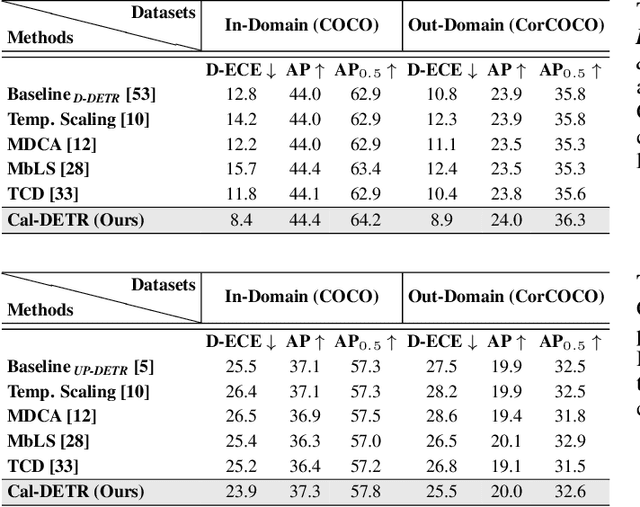
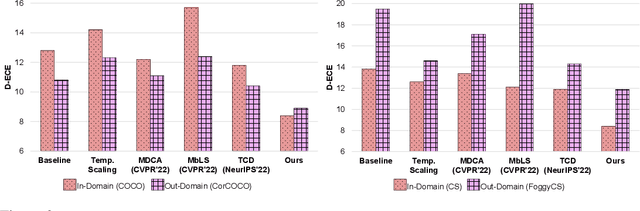
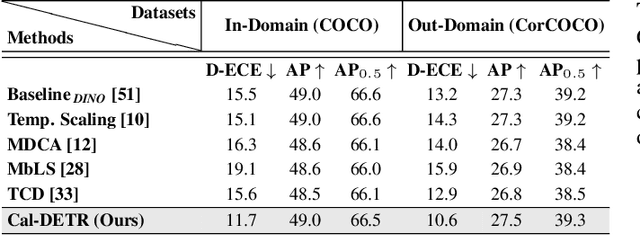
Albeit revealing impressive predictive performance for several computer vision tasks, deep neural networks (DNNs) are prone to making overconfident predictions. This limits the adoption and wider utilization of DNNs in many safety-critical applications. There have been recent efforts toward calibrating DNNs, however, almost all of them focus on the classification task. Surprisingly, very little attention has been devoted to calibrating modern DNN-based object detectors, especially detection transformers, which have recently demonstrated promising detection performance and are influential in many decision-making systems. In this work, we address the problem by proposing a mechanism for calibrated detection transformers (Cal-DETR), particularly for Deformable-DETR, UP-DETR and DINO. We pursue the train-time calibration route and make the following contributions. First, we propose a simple yet effective approach for quantifying uncertainty in transformer-based object detectors. Second, we develop an uncertainty-guided logit modulation mechanism that leverages the uncertainty to modulate the class logits. Third, we develop a logit mixing approach that acts as a regularizer with detection-specific losses and is also complementary to the uncertainty-guided logit modulation technique to further improve the calibration performance. Lastly, we conduct extensive experiments across three in-domain and four out-domain scenarios. Results corroborate the effectiveness of Cal-DETR against the competing train-time methods in calibrating both in-domain and out-domain detections while maintaining or even improving the detection performance. Our codebase and pre-trained models can be accessed at \url{https://github.com/akhtarvision/cal-detr}.
Leveraging Topology for Domain Adaptive Road Segmentation in Satellite and Aerial Imagery
Sep 27, 2023

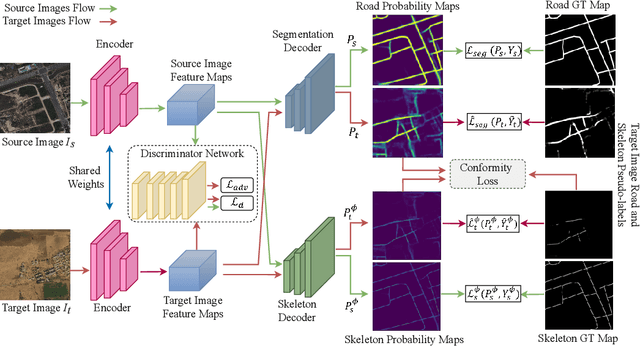
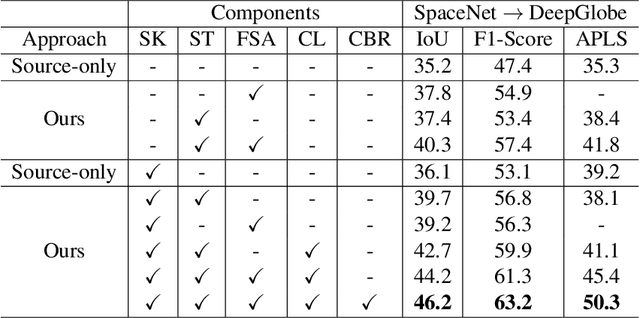
Getting precise aspects of road through segmentation from remote sensing imagery is useful for many real-world applications such as autonomous vehicles, urban development and planning, and achieving sustainable development goals. Roads are only a small part of the image, and their appearance, type, width, elevation, directions, etc. exhibit large variations across geographical areas. Furthermore, due to differences in urbanization styles, planning, and the natural environments; regions along the roads vary significantly. Due to these variations among the train and test domains, the road segmentation algorithms fail to generalize to new geographical locations. Unlike the generic domain alignment scenarios, road segmentation has no scene structure, and generic domain adaptation methods are unable to enforce topological properties like continuity, connectivity, smoothness, etc., thus resulting in degraded domain alignment. In this work, we propose a topology-aware unsupervised domain adaptation approach for road segmentation in remote sensing imagery. Specifically, we predict road skeleton, an auxiliary task to impose the topological constraints. To enforce consistent predictions of road and skeleton, especially in the unlabeled target domain, the conformity loss is defined across the skeleton prediction head and the road-segmentation head. Furthermore, for self-training, we filter out the noisy pseudo-labels by using a connectivity-based pseudo-labels refinement strategy, on both road and skeleton segmentation heads, thus avoiding holes and discontinuities. Extensive experiments on the benchmark datasets show the effectiveness of the proposed approach compared to existing state-of-the-art methods. Specifically, for SpaceNet to DeepGlobe adaptation, the proposed approach outperforms the competing methods by a minimum margin of 6.6%, 6.7%, and 9.8% in IoU, F1-score, and APLS, respectively.
Detection and Localization of Firearm Carriers in Complex Scenes for Improved Safety Measures
Sep 17, 2023
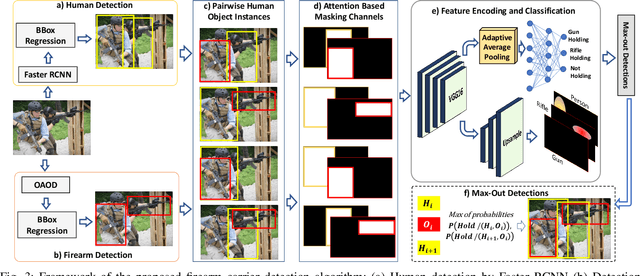
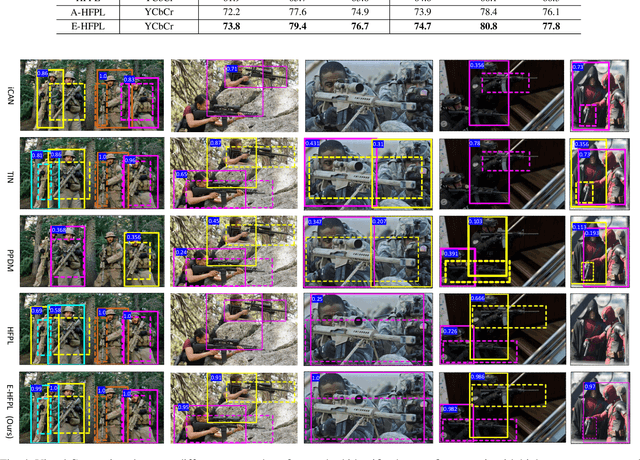

Detecting firearms and accurately localizing individuals carrying them in images or videos is of paramount importance in security, surveillance, and content customization. However, this task presents significant challenges in complex environments due to clutter and the diverse shapes of firearms. To address this problem, we propose a novel approach that leverages human-firearm interaction information, which provides valuable clues for localizing firearm carriers. Our approach incorporates an attention mechanism that effectively distinguishes humans and firearms from the background by focusing on relevant areas. Additionally, we introduce a saliency-driven locality-preserving constraint to learn essential features while preserving foreground information in the input image. By combining these components, our approach achieves exceptional results on a newly proposed dataset. To handle inputs of varying sizes, we pass paired human-firearm instances with attention masks as channels through a deep network for feature computation, utilizing an adaptive average pooling layer. We extensively evaluate our approach against existing methods in human-object interaction detection and achieve significant results (AP=77.8\%) compared to the baseline approach (AP=63.1\%). This demonstrates the effectiveness of leveraging attention mechanisms and saliency-driven locality preservation for accurate human-firearm interaction detection. Our findings contribute to advancing the fields of security and surveillance, enabling more efficient firearm localization and identification in diverse scenarios.
Towards Improving Calibration in Object Detection Under Domain Shift
Sep 15, 2022



The increasing use of deep neural networks in safety-critical applications requires the trained models to be well-calibrated. Most current calibration techniques address classification problems while focusing on improving calibration on in-domain predictions. Little to no attention is paid towards addressing calibration of visual object detectors which occupy similar space and importance in many decision making systems. In this paper, we study the calibration of current object detection models, particularly under domain shift. To this end, we first introduce a plug-and-play train-time calibration loss for object detection. It can be used as an auxiliary loss function to improve detector's calibration. Second, we devise a new uncertainty quantification mechanism for object detection which can implicitly calibrate the commonly used self-training based domain adaptive detectors. We include in our study both single-stage and two-stage object detectors. We demonstrate that our loss improves calibration for both in-domain and out-of-domain detections with notable margins. Finally, we show the utility of our techniques in calibrating the domain adaptive object detectors in diverse domain shift scenarios.
Distribution Regularized Self-Supervised Learning for Domain Adaptation of Semantic Segmentation
Jun 20, 2022



This paper proposes a novel pixel-level distribution regularization scheme (DRSL) for self-supervised domain adaptation of semantic segmentation. In a typical setting, the classification loss forces the semantic segmentation model to greedily learn the representations that capture inter-class variations in order to determine the decision (class) boundary. Due to the domain shift, this decision boundary is unaligned in the target domain, resulting in noisy pseudo labels adversely affecting self-supervised domain adaptation. To overcome this limitation, along with capturing inter-class variation, we capture pixel-level intra-class variations through class-aware multi-modal distribution learning (MMDL). Thus, the information necessary for capturing the intra-class variations is explicitly disentangled from the information necessary for inter-class discrimination. Features captured thus are much more informative, resulting in pseudo-labels with low noise. This disentanglement allows us to perform separate alignments in discriminative space and multi-modal distribution space, using cross-entropy based self-learning for the former. For later, we propose a novel stochastic mode alignment method, by explicitly decreasing the distance between the target and source pixels that map to the same mode. The distance metric learning loss, computed over pseudo-labels and backpropagated from multi-modal modeling head, acts as the regularizer over the base network shared with the segmentation head. The results from comprehensive experiments on synthetic to real domain adaptation setups, i.e., GTA-V/SYNTHIA to Cityscapes, show that DRSL outperforms many existing approaches (a minimum margin of 2.3% and 2.5% in mIoU for SYNTHIA to Cityscapes).
Mapping Temporary Slums from Satellite Imagery using a Semi-Supervised Approach
Apr 09, 2022



One billion people worldwide are estimated to be living in slums, and documenting and analyzing these regions is a challenging task. As compared to regular slums; the small, scattered and temporary nature of temporary slums makes data collection and labeling tedious and time-consuming. To tackle this challenging problem of temporary slums detection, we present a semi-supervised deep learning segmentation-based approach; with the strategy to detect initial seed images in the zero-labeled data settings. A small set of seed samples (32 in our case) are automatically discovered by analyzing the temporal changes, which are manually labeled to train a segmentation and representation learning module. The segmentation module gathers high dimensional image representations, and the representation learning module transforms image representations into embedding vectors. After that, a scoring module uses the embedding vectors to sample images from a large pool of unlabeled images and generates pseudo-labels for the sampled images. These sampled images with their pseudo-labels are added to the training set to update the segmentation and representation learning modules iteratively. To analyze the effectiveness of our technique, we construct a large geographically marked dataset of temporary slums. This dataset constitutes more than 200 potential temporary slum locations (2.28 square kilometers) found by sieving sixty-eight thousand images from 12 metropolitan cities of Pakistan covering 8000 square kilometers. Furthermore, our proposed method outperforms several competitive semi-supervised semantic segmentation baselines on a similar setting. The code and the dataset will be made publicly available.
Combining Scale-Invariance and Uncertainty for Self-Supervised Domain Adaptation of Foggy Scenes Segmentation
Jan 17, 2022



This paper presents FogAdapt, a novel approach for domain adaptation of semantic segmentation for dense foggy scenes. Although significant research has been directed to reduce the domain shift in semantic segmentation, adaptation to scenes with adverse weather conditions remains an open question. Large variations in the visibility of the scene due to weather conditions, such as fog, smog, and haze, exacerbate the domain shift, thus making unsupervised adaptation in such scenarios challenging. We propose a self-entropy and multi-scale information augmented self-supervised domain adaptation method (FogAdapt) to minimize the domain shift in foggy scenes segmentation. Supported by the empirical evidence that an increase in fog density results in high self-entropy for segmentation probabilities, we introduce a self-entropy based loss function to guide the adaptation method. Furthermore, inferences obtained at different image scales are combined and weighted by the uncertainty to generate scale-invariant pseudo-labels for the target domain. These scale-invariant pseudo-labels are robust to visibility and scale variations. We evaluate the proposed model on real clear-weather scenes to real foggy scenes adaptation and synthetic non-foggy images to real foggy scenes adaptation scenarios. Our experiments demonstrate that FogAdapt significantly outperforms the current state-of-the-art in semantic segmentation of foggy images. Specifically, by considering the standard settings compared to state-of-the-art (SOTA) methods, FogAdapt gains 3.8% on Foggy Zurich, 6.0% on Foggy Driving-dense, and 3.6% on Foggy Driving in mIoU when adapted from Cityscapes to Foggy Zurich.
Towards Low-Cost and Efficient Malaria Detection
Nov 26, 2021



Malaria, a fatal but curable disease claims hundreds of thousands of lives every year. Early and correct diagnosis is vital to avoid health complexities, however, it depends upon the availability of costly microscopes and trained experts to analyze blood-smear slides. Deep learning-based methods have the potential to not only decrease the burden of experts but also improve diagnostic accuracy on low-cost microscopes. However, this is hampered by the absence of a reasonable size dataset. One of the most challenging aspects is the reluctance of the experts to annotate the dataset at low magnification on low-cost microscopes. We present a dataset to further the research on malaria microscopy over the low-cost microscopes at low magnification. Our large-scale dataset consists of images of blood-smear slides from several malaria-infected patients, collected through microscopes at two different cost spectrums and multiple magnifications. Malarial cells are annotated for the localization and life-stage classification task on the images collected through the high-cost microscope at high magnification. We design a mechanism to transfer these annotations from the high-cost microscope at high magnification to the low-cost microscope, at multiple magnifications. Multiple object detectors and domain adaptation methods are presented as the baselines. Furthermore, a partially supervised domain adaptation method is introduced to adapt the object-detector to work on the images collected from the low-cost microscope. The dataset will be made publicly available after publication.
Out of distribution detection for skin and malaria images
Nov 02, 2021

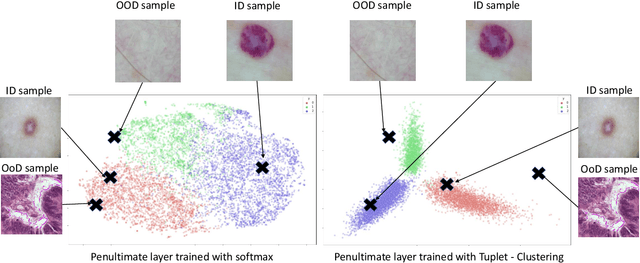
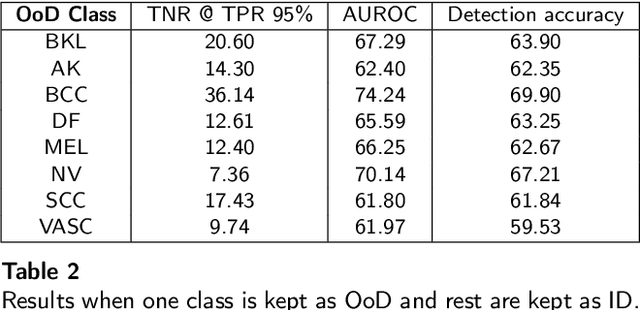
Deep neural networks have shown promising results in disease detection and classification using medical image data. However, they still suffer from the challenges of handling real-world scenarios especially reliably detecting out-of-distribution (OoD) samples. We propose an approach to robustly classify OoD samples in skin and malaria images without the need to access labeled OoD samples during training. Specifically, we use metric learning along with logistic regression to force the deep networks to learn much rich class representative features. To guide the learning process against the OoD examples, we generate ID similar-looking examples by either removing class-specific salient regions in the image or permuting image parts and distancing them away from in-distribution samples. During inference time, the K-reciprocal nearest neighbor is employed to detect out-of-distribution samples. For skin cancer OoD detection, we employ two standard benchmark skin cancer ISIC datasets as ID, and six different datasets with varying difficulty levels were taken as out of distribution. For malaria OoD detection, we use the BBBC041 malaria dataset as ID and five different challenging datasets as out of distribution. We achieved state-of-the-art results, improving 5% and 4% in TNR@TPR95% over the previous state-of-the-art for skin cancer and malaria OoD detection respectively.