 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuhammad Ahmad
Transformers Fusion across Disjoint Samples for Hyperspectral Image Classification
May 02, 2024
3D Swin Transformer (3D-ST) known for its hierarchical attention and window-based processing, excels in capturing intricate spatial relationships within images. Spatial-spectral Transformer (SST), meanwhile, specializes in modeling long-range dependencies through self-attention mechanisms. Therefore, this paper introduces a novel method: an attentional fusion of these two transformers to significantly enhance the classification performance of Hyperspectral Images (HSIs). What sets this approach apart is its emphasis on the integration of attentional mechanisms from both architectures. This integration not only refines the modeling of spatial and spectral information but also contributes to achieving more precise and accurate classification results. The experimentation and evaluation of benchmark HSI datasets underscore the importance of employing disjoint training, validation, and test samples. The results demonstrate the effectiveness of the fusion approach, showcasing its superiority over traditional methods and individual transformers. Incorporating disjoint samples enhances the robustness and reliability of the proposed methodology, emphasizing its potential for advancing hyperspectral image classification.
Traditional to Transformers: A Survey on Current Trends and Future Prospects for Hyperspectral Image Classification
Apr 23, 2024Hyperspectral image classification is a challenging task due to the high dimensionality and complex nature of hyperspectral data. In recent years, deep learning techniques have emerged as powerful tools for addressing these challenges. This survey provides a comprehensive overview of the current trends and future prospects in hyperspectral image classification, focusing on the advancements from deep learning models to the emerging use of transformers. We review the key concepts, methodologies, and state-of-the-art approaches in deep learning for hyperspectral image classification. Additionally, we discuss the potential of transformer-based models in this field and highlight the advantages and challenges associated with these approaches. Comprehensive experimental results have been undertaken using three Hyperspectral datasets to verify the efficacy of various conventional deep-learning models and Transformers. Finally, we outline future research directions and potential applications that can further enhance the accuracy and efficiency of hyperspectral image classification. The Source code is available at https://github.com/mahmad00/Conventional-to-Transformer-for-Hyperspectral-Image-Classification-Survey-2024.
Pyramid Hierarchical Transformer for Hyperspectral Image Classification
Apr 23, 2024The traditional Transformer model encounters challenges with variable-length input sequences, particularly in Hyperspectral Image Classification (HSIC), leading to efficiency and scalability concerns. To overcome this, we propose a pyramid-based hierarchical transformer (PyFormer). This innovative approach organizes input data hierarchically into segments, each representing distinct abstraction levels, thereby enhancing processing efficiency for lengthy sequences. At each level, a dedicated transformer module is applied, effectively capturing both local and global context. Spatial and spectral information flow within the hierarchy facilitates communication and abstraction propagation. Integration of outputs from different levels culminates in the final input representation. Experimental results underscore the superiority of the proposed method over traditional approaches. Additionally, the incorporation of disjoint samples augments robustness and reliability, thereby highlighting the potential of our approach in advancing HSIC. The source code is available at https://github.com/mahmad00/PyFormer.
Importance of Disjoint Sampling in Conventional and Transformer Models for Hyperspectral Image Classification
Apr 23, 2024Disjoint sampling is critical for rigorous and unbiased evaluation of state-of-the-art (SOTA) models. When training, validation, and test sets overlap or share data, it introduces a bias that inflates performance metrics and prevents accurate assessment of a model's true ability to generalize to new examples. This paper presents an innovative disjoint sampling approach for training SOTA models on Hyperspectral image classification (HSIC) tasks. By separating training, validation, and test data without overlap, the proposed method facilitates a fairer evaluation of how well a model can classify pixels it was not exposed to during training or validation. Experiments demonstrate the approach significantly improves a model's generalization compared to alternatives that include training and validation data in test data. By eliminating data leakage between sets, disjoint sampling provides reliable metrics for benchmarking progress in HSIC. Researchers can have confidence that reported performance truly reflects a model's capabilities for classifying new scenes, not just memorized pixels. This rigorous methodology is critical for advancing SOTA models and their real-world application to large-scale land mapping with Hyperspectral sensors. The source code is available at https://github.com/mahmad00/Disjoint-Sampling-for-Hyperspectral-Image-Classification.
Spatio-Temporal Anomaly Detection with Graph Networks for Data Quality Monitoring of the Hadron Calorimeter
Nov 07, 2023The compact muon solenoid (CMS) experiment is a general-purpose detector for high-energy collision at the large hadron collider (LHC) at CERN. It employs an online data quality monitoring (DQM) system to promptly spot and diagnose particle data acquisition problems to avoid data quality loss. In this study, we present semi-supervised spatio-temporal anomaly detection (AD) monitoring for the physics particle reading channels of the hadronic calorimeter (HCAL) of the CMS using three-dimensional digi-occupancy map data of the DQM. We propose the GraphSTAD system, which employs convolutional and graph neural networks to learn local spatial characteristics induced by particles traversing the detector, and global behavior owing to shared backend circuit connections and housing boxes of the channels, respectively. Recurrent neural networks capture the temporal evolution of the extracted spatial features. We have validated the accuracy of the proposed AD system in capturing diverse channel fault types using the LHC Run-2 collision data sets. The GraphSTAD system has achieved production-level accuracy and is being integrated into the CMS core production system--for real-time monitoring of the HCAL. We have also provided a quantitative performance comparison with alternative benchmark models to demonstrate the promising leverage of the presented system.
Sharpend Cosine Similarity based Neural Network for Hyperspectral Image Classification
May 26, 2023



Hyperspectral Image Classification (HSIC) is a difficult task due to high inter and intra-class similarity and variability, nested regions, and overlapping. 2D Convolutional Neural Networks (CNN) emerged as a viable network whereas, 3D CNNs are a better alternative due to accurate classification. However, 3D CNNs are highly computationally complex due to their volume and spectral dimensions. Moreover, down-sampling and hierarchical filtering (high frequency) i.e., texture features need to be smoothed during the forward pass which is crucial for accurate HSIC. Furthermore, CNN requires tons of tuning parameters which increases the training time. Therefore, to overcome the aforesaid issues, Sharpened Cosine Similarity (SCS) concept as an alternative to convolutions in a Neural Network for HSIC is introduced. SCS is exceptionally parameter efficient due to skipping the non-linear activation layers, normalization, and dropout after the SCS layer. Use of MaxAbsPool instead of MaxPool which selects the element with the highest magnitude of activity, even if it's negative. Experimental results on publicly available HSI datasets proved the performance of SCS as compared to the convolutions in Neural Networks.
Attention Mechanism Meets with Hybrid Dense Network for Hyperspectral Image Classification
Jan 04, 2022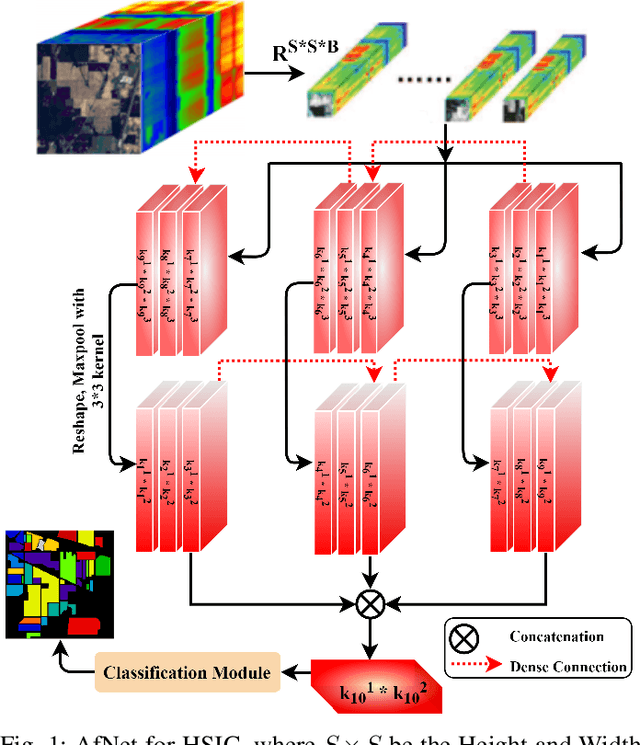
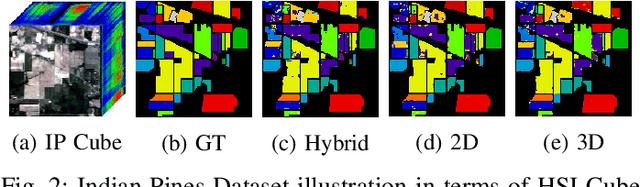
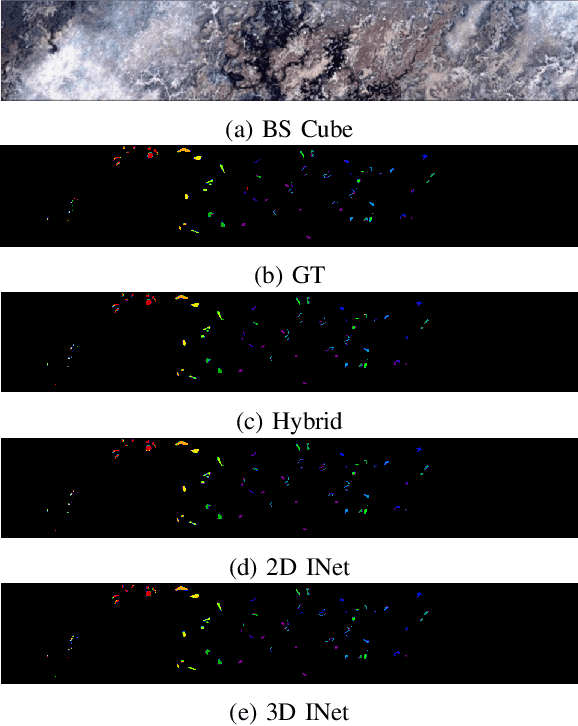
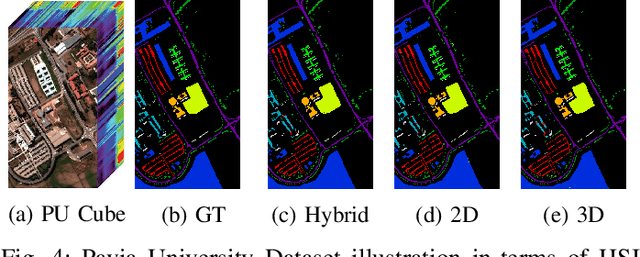
Convolutional Neural Networks (CNN) are more suitable, indeed. However, fixed kernel sizes make traditional CNN too specific, neither flexible nor conducive to feature learning, thus impacting on the classification accuracy. The convolution of different kernel size networks may overcome this problem by capturing more discriminating and relevant information. In light of this, the proposed solution aims at combining the core idea of 3D and 2D Inception net with the Attention mechanism to boost the HSIC CNN performance in a hybrid scenario. The resulting \textit{attention-fused hybrid network} (AfNet) is based on three attention-fused parallel hybrid sub-nets with different kernels in each block repeatedly using high-level features to enhance the final ground-truth maps. In short, AfNet is able to selectively filter out the discriminative features critical for classification. Several tests on HSI datasets provided competitive results for AfNet compared to state-of-the-art models. The proposed pipeline achieved, indeed, an overall accuracy of 97\% for the Indian Pines, 100\% for Botswana, 99\% for Pavia University, Pavia Center, and Salinas datasets.
3D/2D regularized CNN feature hierarchy for Hyperspectral image classification
Apr 25, 2021



Convolutional Neural Networks (CNN) have been rigorously studied for Hyperspectral Image Classification (HSIC) and are known to be effective in exploiting joint spatial-spectral information with the expense of lower generalization performance and learning speed due to the hard labels and non-uniform distribution over labels. Several regularization techniques have been used to overcome the aforesaid issues. However, sometimes models learn to predict the samples extremely confidently which is not good from a generalization point of view. Therefore, this paper proposed an idea to enhance the generalization performance of a hybrid CNN for HSIC using soft labels that are a weighted average of the hard labels and uniform distribution over ground labels. The proposed method helps to prevent CNN from becoming over-confident. We empirically show that in improving generalization performance, label smoothing also improves model calibration which significantly improves beam-search. Several publicly available Hyperspectral datasets are used to validate the experimental evaluation which reveals improved generalization performance, statistical significance, and computational complexity as compared to the state-of-the-art models. The code will be made available at https://github.com/mahmad00.
Hyperspectral Image Classification: Artifacts of Dimension Reduction on Hybrid CNN
Jan 25, 2021



Convolutional Neural Networks (CNN) has been extensively studied for Hyperspectral Image Classification (HSIC) more specifically, 2D and 3D CNN models have proved highly efficient in exploiting the spatial and spectral information of Hyperspectral Images. However, 2D CNN only considers the spatial information and ignores the spectral information whereas 3D CNN jointly exploits spatial-spectral information at a high computational cost. Therefore, this work proposed a lightweight CNN (3D followed by 2D-CNN) model which significantly reduces the computational cost by distributing spatial-spectral feature extraction across a lighter model alongside a preprocessing that has been carried out to improve the classification results. Five benchmark Hyperspectral datasets (i.e., SalinasA, Salinas, Indian Pines, Pavia University, Pavia Center, and Botswana) are used for experimental evaluation. The experimental results show that the proposed pipeline outperformed in terms of generalization performance, statistical significance, and computational complexity, as compared to the state-of-the-art 2D/3D CNN models except commonly used computationally expensive design choices.
Hyperspectral Image Classification -- Traditional to Deep Models: A Survey for Future Prospects
Jan 15, 2021



Hyperspectral Imaging (HSI) has been extensively utilized in many real-life applications because it benefits from the detailed spectral information contained in each pixel. Notably, the complex characteristics i.e., the nonlinear relation among the captured spectral information and the corresponding object of HSI data make accurate classification challenging for traditional methods. In the last few years, deep learning (DL) has been substantiated as a powerful feature extractor that effectively addresses the nonlinear problems that appeared in a number of computer vision tasks. This prompts the deployment of DL for HSI classification (HSIC) which revealed good performance. This survey enlists a systematic overview of DL for HSIC and compared state-of-the-art strategies of the said topic. Primarily, we will encapsulate the main challenges of traditional machine learning for HSIC and then we will acquaint the superiority of DL to address these problems. This survey breakdown the state-of-the-art DL frameworks into spectral-features, spatial-features, and together spatial-spectral features to systematically analyze the achievements (future directions as well) of these frameworks for HSIC. Moreover, we will consider the fact that DL requires a large number of labeled training examples whereas acquiring such a number for HSIC is challenging in terms of time and cost. Therefore, this survey discusses some strategies to improve the generalization performance of DL strategies which can provide some future guidelines.