 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuhammad Imran
A Flexible 2.5D Medical Image Segmentation Approach with In-Slice and Cross-Slice Attention
Apr 30, 2024
Deep learning has become the de facto method for medical image segmentation, with 3D segmentation models excelling in capturing complex 3D structures and 2D models offering high computational efficiency. However, segmenting 2.5D images, which have high in-plane but low through-plane resolution, is a relatively unexplored challenge. While applying 2D models to individual slices of a 2.5D image is feasible, it fails to capture the spatial relationships between slices. On the other hand, 3D models face challenges such as resolution inconsistencies in 2.5D images, along with computational complexity and susceptibility to overfitting when trained with limited data. In this context, 2.5D models, which capture inter-slice correlations using only 2D neural networks, emerge as a promising solution due to their reduced computational demand and simplicity in implementation. In this paper, we introduce CSA-Net, a flexible 2.5D segmentation model capable of processing 2.5D images with an arbitrary number of slices through an innovative Cross-Slice Attention (CSA) module. This module uses the cross-slice attention mechanism to effectively capture 3D spatial information by learning long-range dependencies between the center slice (for segmentation) and its neighboring slices. Moreover, CSA-Net utilizes the self-attention mechanism to understand correlations among pixels within the center slice. We evaluated CSA-Net on three 2.5D segmentation tasks: (1) multi-class brain MRI segmentation, (2) binary prostate MRI segmentation, and (3) multi-class prostate MRI segmentation. CSA-Net outperformed leading 2D and 2.5D segmentation methods across all three tasks, demonstrating its efficacy and superiority. Our code is publicly available at https://github.com/mirthAI/CSA-Net.
RetinaRegNet: A Versatile Approach for Retinal Image Registration
Apr 24, 2024We introduce the RetinaRegNet model, which can achieve state-of-the-art performance across various retinal image registration tasks. RetinaRegNet does not require training on any retinal images. It begins by establishing point correspondences between two retinal images using image features derived from diffusion models. This process involves the selection of feature points from the moving image using the SIFT algorithm alongside random point sampling. For each selected feature point, a 2D correlation map is computed by assessing the similarity between the feature vector at that point and the feature vectors of all pixels in the fixed image. The pixel with the highest similarity score in the correlation map corresponds to the feature point in the moving image. To remove outliers in the estimated point correspondences, we first applied an inverse consistency constraint, followed by a transformation-based outlier detector. This method proved to outperform the widely used random sample consensus (RANSAC) outlier detector by a significant margin. To handle large deformations, we utilized a two-stage image registration framework. A homography transformation was used in the first stage and a more accurate third-order polynomial transformation was used in the second stage. The model's effectiveness was demonstrated across three retinal image datasets: color fundus images, fluorescein angiography images, and laser speckle flowgraphy images. RetinaRegNet outperformed current state-of-the-art methods in all three datasets. It was especially effective for registering image pairs with large displacement and scaling deformations. This innovation holds promise for various applications in retinal image analysis. Our code is publicly available at https://github.com/mirthAI/RetinaRegNet.
Monitoring Critical Infrastructure Facilities During Disasters Using Large Language Models
Apr 18, 2024Critical Infrastructure Facilities (CIFs), such as healthcare and transportation facilities, are vital for the functioning of a community, especially during large-scale emergencies. In this paper, we explore a potential application of Large Language Models (LLMs) to monitor the status of CIFs affected by natural disasters through information disseminated in social media networks. To this end, we analyze social media data from two disaster events in two different countries to identify reported impacts to CIFs as well as their impact severity and operational status. We employ state-of-the-art open-source LLMs to perform computational tasks including retrieval, classification, and inference, all in a zero-shot setting. Through extensive experimentation, we report the results of these tasks using standard evaluation metrics and reveal insights into the strengths and weaknesses of LLMs. We note that although LLMs perform well in classification tasks, they encounter challenges with inference tasks, especially when the context/prompt is complex and lengthy. Additionally, we outline various potential directions for future exploration that can be beneficial during the initial adoption phase of LLMs for disaster response tasks.
CIS-UNet: Multi-Class Segmentation of the Aorta in Computed Tomography Angiography via Context-Aware Shifted Window Self-Attention
Jan 23, 2024Advancements in medical imaging and endovascular grafting have facilitated minimally invasive treatments for aortic diseases. Accurate 3D segmentation of the aorta and its branches is crucial for interventions, as inaccurate segmentation can lead to erroneous surgical planning and endograft construction. Previous methods simplified aortic segmentation as a binary image segmentation problem, overlooking the necessity of distinguishing between individual aortic branches. In this paper, we introduce Context Infused Swin-UNet (CIS-UNet), a deep learning model designed for multi-class segmentation of the aorta and thirteen aortic branches. Combining the strengths of Convolutional Neural Networks (CNNs) and Swin transformers, CIS-UNet adopts a hierarchical encoder-decoder structure comprising a CNN encoder, symmetric decoder, skip connections, and a novel Context-aware Shifted Window Self-Attention (CSW-SA) as the bottleneck block. Notably, CSW-SA introduces a unique utilization of the patch merging layer, distinct from conventional Swin transformers. It efficiently condenses the feature map, providing a global spatial context and enhancing performance when applied at the bottleneck layer, offering superior computational efficiency and segmentation accuracy compared to the Swin transformers. We trained our model on computed tomography (CT) scans from 44 patients and tested it on 15 patients. CIS-UNet outperformed the state-of-the-art SwinUNetR segmentation model, which is solely based on Swin transformers, by achieving a superior mean Dice coefficient of 0.713 compared to 0.697, and a mean surface distance of 2.78 mm compared to 3.39 mm. CIS-UNet's superior 3D aortic segmentation offers improved precision and optimization for planning endovascular treatments. Our dataset and code will be publicly available.
CrisisViT: A Robust Vision Transformer for Crisis Image Classification
Jan 05, 2024In times of emergency, crisis response agencies need to quickly and accurately assess the situation on the ground in order to deploy relevant services and resources. However, authorities often have to make decisions based on limited information, as data on affected regions can be scarce until local response services can provide first-hand reports. Fortunately, the widespread availability of smartphones with high-quality cameras has made citizen journalism through social media a valuable source of information for crisis responders. However, analyzing the large volume of images posted by citizens requires more time and effort than is typically available. To address this issue, this paper proposes the use of state-of-the-art deep neural models for automatic image classification/tagging, specifically by adapting transformer-based architectures for crisis image classification (CrisisViT). We leverage the new Incidents1M crisis image dataset to develop a range of new transformer-based image classification models. Through experimentation over the standard Crisis image benchmark dataset, we demonstrate that the CrisisViT models significantly outperform previous approaches in emergency type, image relevance, humanitarian category, and damage severity classification. Additionally, we show that the new Incidents1M dataset can further augment the CrisisViT models resulting in an additional 1.25% absolute accuracy gain.
RIS-Enhanced MIMO Channels in Urban Environments: Experimental Insights
Nov 29, 2023Can the smart radio environment paradigm measurably enhance the performance of contemporary urban macrocells? In this study, we explore the impact of reconfigurable intelligent surfaces (RISs) on a real-world sub-6 GHz MIMO channel. A rooftop-mounted macrocell antenna has been adapted to enable frequency domain channel measurements to be ascertained. A nature-inspired beam search algorithm has been employed to maximize channel gain at user positions, revealing a potential 50% increase in channel capacity in certain circumstances. Analysis reveals, however, that the spatial characteristics of the channel can be adversely affected through the introduction of a RIS in these settings. The RIS prototype schematics, Gerber files, and source code have been made available to aid in future experimental efforts of the wireless research community.
Image Registration of In Vivo Micro-Ultrasound and Ex Vivo Pseudo-Whole Mount Histopathology Images of the Prostate: A Proof-of-Concept Study
May 31, 2023



Early diagnosis of prostate cancer significantly improves a patient's 5-year survival rate. Biopsy of small prostate cancers is improved with image-guided biopsy. MRI-ultrasound fusion-guided biopsy is sensitive to smaller tumors but is underutilized due to the high cost of MRI and fusion equipment. Micro-ultrasound (micro-US), a novel high-resolution ultrasound technology, provides a cost-effective alternative to MRI while delivering comparable diagnostic accuracy. However, the interpretation of micro-US is challenging due to subtle gray scale changes indicating cancer vs normal tissue. This challenge can be addressed by training urologists with a large dataset of micro-US images containing the ground truth cancer outlines. Such a dataset can be mapped from surgical specimens (histopathology) onto micro-US images via image registration. In this paper, we present a semi-automated pipeline for registering in vivo micro-US images with ex vivo whole-mount histopathology images. Our pipeline begins with the reconstruction of pseudo-whole-mount histopathology images and a 3D micro-US volume. Each pseudo-whole-mount histopathology image is then registered with the corresponding axial micro-US slice using a two-stage approach that estimates an affine transformation followed by a deformable transformation. We evaluated our registration pipeline using micro-US and histopathology images from 18 patients who underwent radical prostatectomy. The results showed a Dice coefficient of 0.94 and a landmark error of 2.7 mm, indicating the accuracy of our registration pipeline. This proof-of-concept study demonstrates the feasibility of accurately aligning micro-US and histopathology images. To promote transparency and collaboration in research, we will make our code and dataset publicly available.
MicroSegNet: A Deep Learning Approach for Prostate Segmentation on Micro-Ultrasound Images
May 31, 2023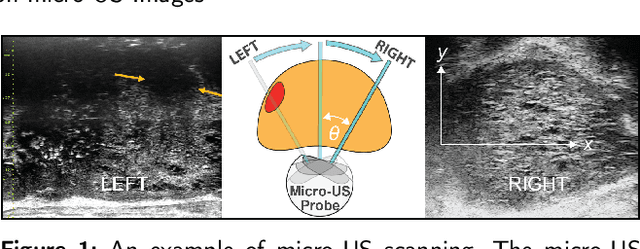
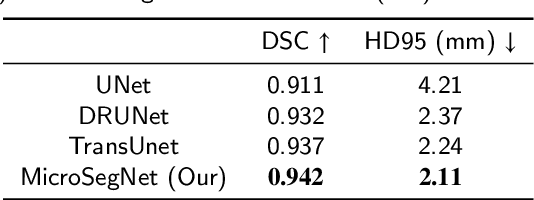
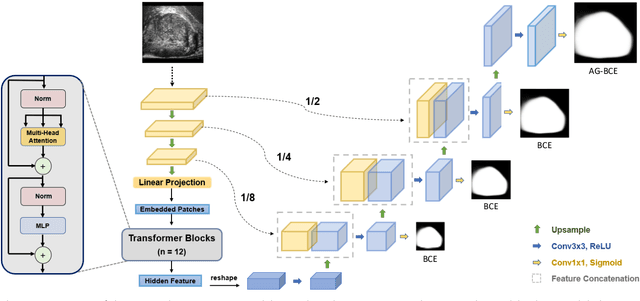
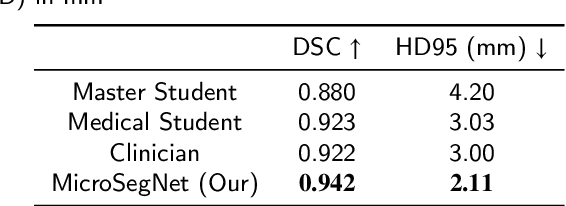
Micro-ultrasound (micro-US) is a novel 29-MHz ultrasound technique that provides 3-4 times higher resolution than traditional ultrasound, delivering comparable accuracy for diagnosing prostate cancer to MRI but at a lower cost. Accurate prostate segmentation is crucial for prostate volume measurement, cancer diagnosis, prostate biopsy, and treatment planning. This paper proposes a deep learning approach for automated, fast, and accurate prostate segmentation on micro-US images. Prostate segmentation on micro-US is challenging due to artifacts and indistinct borders between the prostate, bladder, and urethra in the midline. We introduce MicroSegNet, a multi-scale annotation-guided Transformer UNet model to address this challenge. During the training process, MicroSegNet focuses more on regions that are hard to segment (challenging regions), where expert and non-expert annotations show discrepancies. We achieve this by proposing an annotation-guided cross entropy loss that assigns larger weight to pixels in hard regions and lower weight to pixels in easy regions. We trained our model using micro-US images from 55 patients, followed by evaluation on 20 patients. Our MicroSegNet model achieved a Dice coefficient of 0.942 and a Hausdorff distance of 2.11 mm, outperforming several state-of-the-art segmentation methods, as well as three human annotators with different experience levels. We will make our code and dataset publicly available to promote transparency and collaboration in research.
A large-scale multimodal dataset of human speech recognition
Mar 15, 2023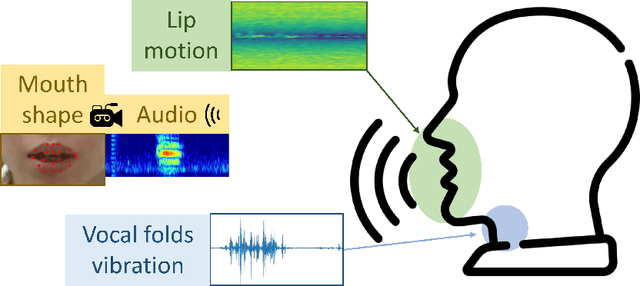

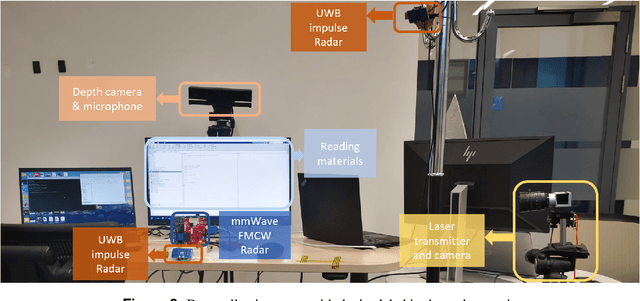
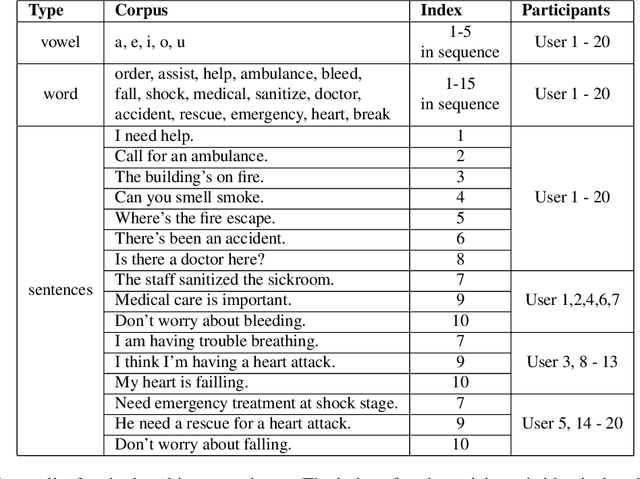
Nowadays, non-privacy small-scale motion detection has attracted an increasing amount of research in remote sensing in speech recognition. These new modalities are employed to enhance and restore speech information from speakers of multiple types of data. In this paper, we propose a dataset contains 7.5 GHz Channel Impulse Response (CIR) data from ultra-wideband (UWB) radars, 77-GHz frequency modulated continuous wave (FMCW) data from millimetre wave (mmWave) radar, and laser data. Meanwhile, a depth camera is adopted to record the landmarks of the subject's lip and voice. Approximately 400 minutes of annotated speech profiles are provided, which are collected from 20 participants speaking 5 vowels, 15 words and 16 sentences. The dataset has been validated and has potential for the research of lip reading and multimodal speech recognition.
RweetMiner: Automatic identification and categorization of help requests on twitter during disasters
Mar 04, 2023



Catastrophic events create uncertain situations for humanitarian organizations locating and providing aid to affected people. Many people turn to social media during disasters for requesting help and/or providing relief to others. However, the majority of social media posts seeking help could not properly be detected and remained concealed because often they are noisy and ill-formed. Existing systems lack in planning an effective strategy for tweet preprocessing and grasping the contexts of tweets. This research, first of all, formally defines request tweets in the context of social networking sites, hereafter rweets, along with their different primary types and sub-types. Our main contributions are the identification and categorization of rweets. For rweet identification, we employ two approaches, namely a rule-based and logistic regression, and show their high precision and F1 scores. The rweets classification into sub-types such as medical, food, and shelter, using logistic regression shows promising results and outperforms existing works. Finally, we introduce an architecture to store intermediate data to accelerate the development process of the machine learning classifiers.