 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNageen Himayat
Enhancing O-RAN Security: Evasion Attacks and Robust Defenses for Graph Reinforcement Learning-based Connection Management
May 06, 2024
Adversarial machine learning, focused on studying various attacks and defenses on machine learning (ML) models, is rapidly gaining importance as ML is increasingly being adopted for optimizing wireless systems such as Open Radio Access Networks (O-RAN). A comprehensive modeling of the security threats and the demonstration of adversarial attacks and defenses on practical AI based O-RAN systems is still in its nascent stages. We begin by conducting threat modeling to pinpoint attack surfaces in O-RAN using an ML-based Connection management application (xApp) as an example. The xApp uses a Graph Neural Network trained using Deep Reinforcement Learning and achieves on average 54% improvement in the coverage rate measured as the 5th percentile user data rates. We then formulate and demonstrate evasion attacks that degrade the coverage rates by as much as 50% through injecting bounded noise at different threat surfaces including the open wireless medium itself. Crucially, we also compare and contrast the effectiveness of such attacks on the ML-based xApp and a non-ML based heuristic. We finally develop and demonstrate robust training-based defenses against the challenging physical/jamming-based attacks and show a 15% improvement in the coverage rates when compared to employing no defense over a range of noise budgets
Investigating the Adversarial Robustness of Density Estimation Using the Probability Flow ODE
Oct 10, 2023Beyond their impressive sampling capabilities, score-based diffusion models offer a powerful analysis tool in the form of unbiased density estimation of a query sample under the training data distribution. In this work, we investigate the robustness of density estimation using the probability flow (PF) neural ordinary differential equation (ODE) model against gradient-based likelihood maximization attacks and the relation to sample complexity, where the compressed size of a sample is used as a measure of its complexity. We introduce and evaluate six gradient-based log-likelihood maximization attacks, including a novel reverse integration attack. Our experimental evaluations on CIFAR-10 show that density estimation using the PF ODE is robust against high-complexity, high-likelihood attacks, and that in some cases adversarial samples are semantically meaningful, as expected from a robust estimator.
Resource-Efficient Federated Hyperdimensional Computing
Jun 02, 2023In conventional federated hyperdimensional computing (HDC), training larger models usually results in higher predictive performance but also requires more computational, communication, and energy resources. If the system resources are limited, one may have to sacrifice the predictive performance by reducing the size of the HDC model. The proposed resource-efficient federated hyperdimensional computing (RE-FHDC) framework alleviates such constraints by training multiple smaller independent HDC sub-models and refining the concatenated HDC model using the proposed dropout-inspired procedure. Our numerical comparison demonstrates that the proposed framework achieves a comparable or higher predictive performance while consuming less computational and wireless resources than the baseline federated HDC implementation.
Multi-Task Model Personalization for Federated Supervised SVM in Heterogeneous Networks
Apr 01, 2023



Federated systems enable collaborative training on highly heterogeneous data through model personalization, which can be facilitated by employing multi-task learning algorithms. However, significant variation in device computing capabilities may result in substantial degradation in the convergence rate of training. To accelerate the learning procedure for diverse participants in a multi-task federated setting, more efficient and robust methods need to be developed. In this paper, we design an efficient iterative distributed method based on the alternating direction method of multipliers (ADMM) for support vector machines (SVMs), which tackles federated classification and regression. The proposed method utilizes efficient computations and model exchange in a network of heterogeneous nodes and allows personalization of the learning model in the presence of non-i.i.d. data. To further enhance privacy, we introduce a random mask procedure that helps avoid data inversion. Finally, we analyze the impact of the proposed privacy mechanisms and participant hardware and data heterogeneity on the system performance.
Streaming Encoding Algorithms for Scalable Hyperdimensional Computing
Sep 28, 2022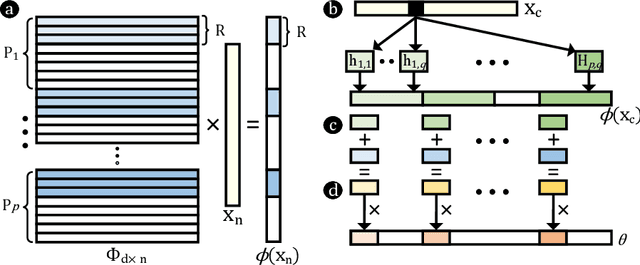

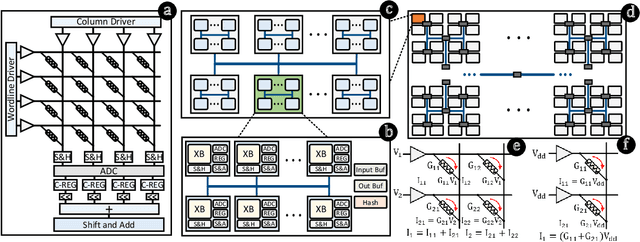

Hyperdimensional computing (HDC) is a paradigm for data representation and learning originating in computational neuroscience. HDC represents data as high-dimensional, low-precision vectors which can be used for a variety of information processing tasks like learning or recall. The mapping to high-dimensional space is a fundamental problem in HDC, and existing methods encounter scalability issues when the input data itself is high-dimensional. In this work, we explore a family of streaming encoding techniques based on hashing. We show formally that these methods enjoy comparable guarantees on performance for learning applications while being substantially more efficient than existing alternatives. We validate these results experimentally on a popular high-dimensional classification problem and show that our approach easily scales to very large data sets.
Dynamic Network-Assisted D2D-Aided Coded Distributed Learning
Nov 26, 2021



Today, various machine learning (ML) applications offer continuous data processing and real-time data analytics at the edge of a wireless network. Distributed ML solutions are seriously challenged by resource heterogeneity, in particular, the so-called straggler effect. To address this issue, we design a novel device-to-device (D2D)-aided coded federated learning method (D2D-CFL) for load balancing across devices while characterizing privacy leakage. The proposed solution captures system dynamics, including data (time-dependent learning model, varied intensity of data arrivals), device (diverse computational resources and volume of training data), and deployment (varied locations and D2D graph connectivity). We derive an optimal compression rate for achieving minimum processing time and establish its connection with the convergence time. The resulting optimization problem provides suboptimal compression parameters, which improve the total training time. Our proposed method is beneficial for real-time collaborative applications, where the users continuously generate training data.
Coded Computing for Low-Latency Federated Learning over Wireless Edge Networks
Nov 12, 2020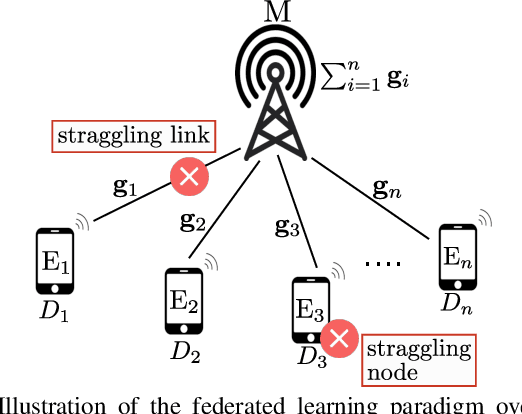
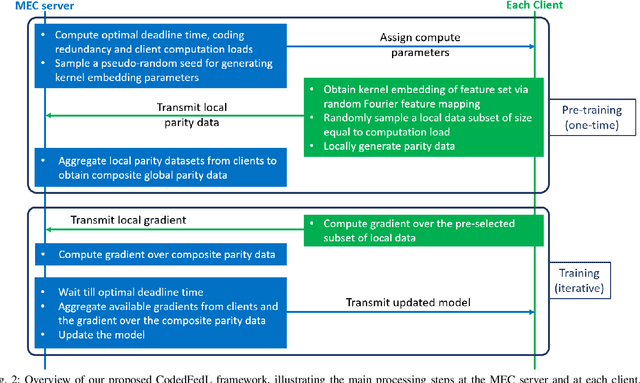
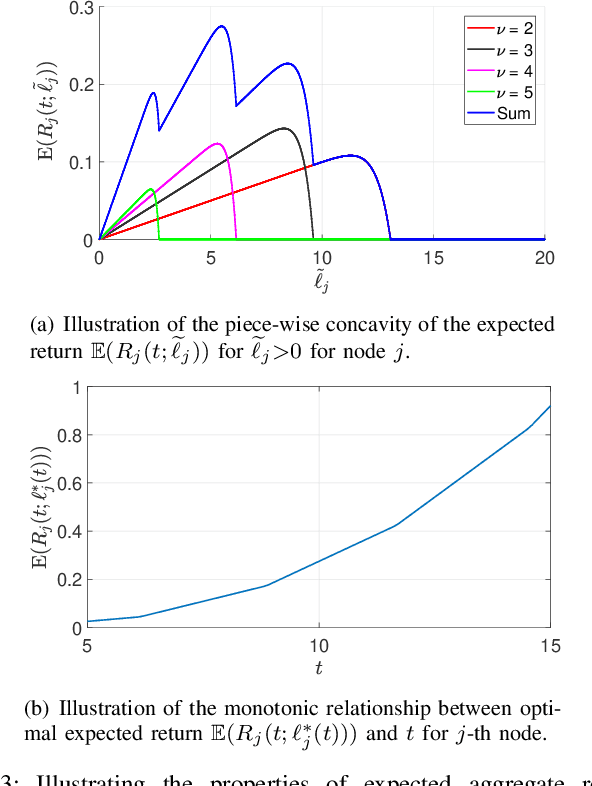
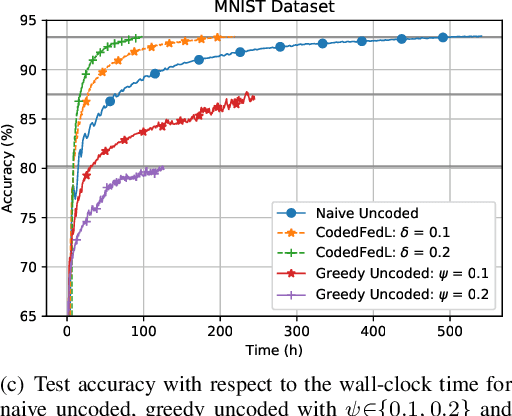
Federated learning enables training a global model from data located at the client nodes, without data sharing and moving client data to a centralized server. Performance of federated learning in a multi-access edge computing (MEC) network suffers from slow convergence due to heterogeneity and stochastic fluctuations in compute power and communication link qualities across clients. We propose a novel coded computing framework, CodedFedL, that injects structured coding redundancy into federated learning for mitigating stragglers and speeding up the training procedure. CodedFedL enables coded computing for non-linear federated learning by efficiently exploiting distributed kernel embedding via random Fourier features that transforms the training task into computationally favourable distributed linear regression. Furthermore, clients generate local parity datasets by coding over their local datasets, while the server combines them to obtain the global parity dataset. Gradient from the global parity dataset compensates for straggling gradients during training, and thereby speeds up convergence. For minimizing the epoch deadline time at the MEC server, we provide a tractable approach for finding the amount of coding redundancy and the number of local data points that a client processes during training, by exploiting the statistical properties of compute as well as communication delays. We also characterize the leakage in data privacy when clients share their local parity datasets with the server. We analyze the convergence rate and iteration complexity of CodedFedL under simplifying assumptions, by treating CodedFedL as a stochastic gradient descent algorithm. Furthermore, we conduct numerical experiments using practical network parameters and benchmark datasets, where CodedFedL speeds up the overall training time by up to $15\times$ in comparison to the benchmark schemes.
Coded Computing for Federated Learning at the Edge
Jul 14, 2020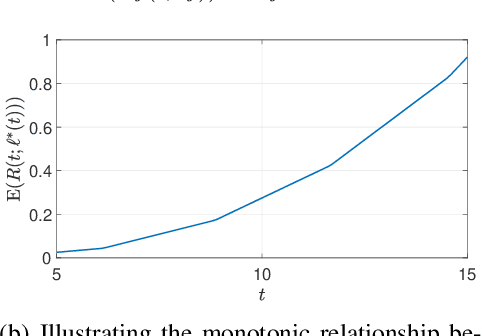

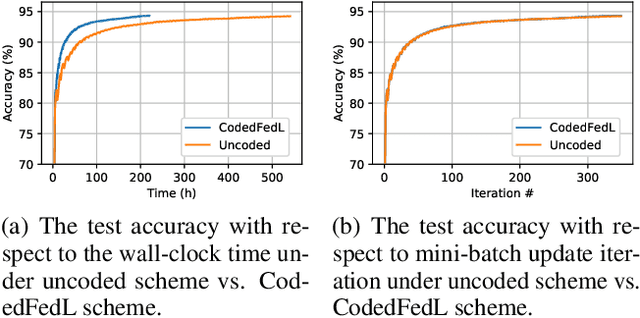

Federated Learning (FL) is an exciting new paradigm that enables training a global model from data generated locally at the client nodes, without moving client data to a centralized server. Performance of FL in a multi-access edge computing (MEC) network suffers from slow convergence due to heterogeneity and stochastic fluctuations in compute power and communication link qualities across clients. A recent work, Coded Federated Learning (CFL), proposes to mitigate stragglers and speed up training for linear regression tasks by assigning redundant computations at the MEC server. Coding redundancy in CFL is computed by exploiting statistical properties of compute and communication delays. We develop CodedFedL that addresses the difficult task of extending CFL to distributed non-linear regression and classification problems with multioutput labels. The key innovation of our work is to exploit distributed kernel embedding using random Fourier features that transforms the training task into distributed linear regression. We provide an analytical solution for load allocation, and demonstrate significant performance gains for CodedFedL through experiments over benchmark datasets using practical network parameters.
Coded Federated Learning
Feb 21, 2020
Federated learning is a method of training a global model from decentralized data distributed across client devices. Here, model parameters are computed locally by each client device and exchanged with a central server, which aggregates the local models for a global view, without requiring sharing of training data. The convergence performance of federated learning is severely impacted in heterogeneous computing platforms such as those at the wireless edge, where straggling computations and communication links can significantly limit timely model parameter updates. This paper develops a novel coded computing technique for federated learning to mitigate the impact of stragglers. In the proposed Coded Federated Learning (CFL) scheme, each client device privately generates parity training data and shares it with the central server only once at the start of the training phase. The central server can then preemptively perform redundant gradient computations on the composite parity data to compensate for the erased or delayed parameter updates. Our results show that CFL allows the global model to converge nearly four times faster when compared to an uncoded approach