 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNakul Agarwal
Multi-Objective Recommendation via Multivariate Policy Learning
May 03, 2024
Real-world recommender systems often need to balance multiple objectives when deciding which recommendations to present to users. These include behavioural signals (e.g. clicks, shares, dwell time), as well as broader objectives (e.g. diversity, fairness). Scalarisation methods are commonly used to handle this balancing task, where a weighted average of per-objective reward signals determines the final score used for ranking. Naturally, how these weights are computed exactly, is key to success for any online platform. We frame this as a decision-making task, where the scalarisation weights are actions taken to maximise an overall North Star reward (e.g. long-term user retention or growth). We extend existing policy learning methods to the continuous multivariate action domain, proposing to maximise a pessimistic lower bound on the North Star reward that the learnt policy will yield. Typical lower bounds based on normal approximations suffer from insufficient coverage, and we propose an efficient and effective policy-dependent correction for this. We provide guidance to design stochastic data collection policies, as well as highly sensitive reward signals. Empirical observations from simulations, offline and online experiments highlight the efficacy of our deployed approach.
Disentangled Neural Relational Inference for Interpretable Motion Prediction
Jan 07, 2024Effective interaction modeling and behavior prediction of dynamic agents play a significant role in interactive motion planning for autonomous robots. Although existing methods have improved prediction accuracy, few research efforts have been devoted to enhancing prediction model interpretability and out-of-distribution (OOD) generalizability. This work addresses these two challenging aspects by designing a variational auto-encoder framework that integrates graph-based representations and time-sequence models to efficiently capture spatio-temporal relations between interactive agents and predict their dynamics. Our model infers dynamic interaction graphs in a latent space augmented with interpretable edge features that characterize the interactions. Moreover, we aim to enhance model interpretability and performance in OOD scenarios by disentangling the latent space of edge features, thereby strengthening model versatility and robustness. We validate our approach through extensive experiments on both simulated and real-world datasets. The results show superior performance compared to existing methods in modeling spatio-temporal relations, motion prediction, and identifying time-invariant latent features.
Vamos: Versatile Action Models for Video Understanding
Nov 22, 2023What makes good video representations for video understanding, such as anticipating future activities, or answering video-conditioned questions? While earlier approaches focus on end-to-end learning directly from video pixels, we propose to revisit text-based representations, such as discrete action labels, or free-form video captions, which are interpretable and can be directly consumed by large language models (LLMs). Intuitively, different video understanding tasks may require representations that are complementary and at different granularities. To this end, we propose versatile action models (Vamos), a learning framework powered by a large language model as the "reasoner", and can flexibly leverage visual embeddings, action labels, and free-form descriptions extracted from videos as its input. We evaluate Vamos on four complementary video understanding benchmarks, Ego4D, Next-QA, IntentQA, and EgoSchema, on its capability to model temporal dynamics, encode visual history, and perform reasoning. Surprisingly, we observe that text-based representations consistently achieve competitive performance on all benchmarks, and that visual embeddings provide marginal or no performance improvement, demonstrating the effectiveness of text-based video representation in the LLM era. We perform extensive ablation study and qualitative analysis to support our observations, and achieve state-of-the-art performance on three benchmarks.
Object-centric Video Representation for Long-term Action Anticipation
Oct 31, 2023This paper focuses on building object-centric representations for long-term action anticipation in videos. Our key motivation is that objects provide important cues to recognize and predict human-object interactions, especially when the predictions are longer term, as an observed "background" object could be used by the human actor in the future. We observe that existing object-based video recognition frameworks either assume the existence of in-domain supervised object detectors or follow a fully weakly-supervised pipeline to infer object locations from action labels. We propose to build object-centric video representations by leveraging visual-language pretrained models. This is achieved by "object prompts", an approach to extract task-specific object-centric representations from general-purpose pretrained models without finetuning. To recognize and predict human-object interactions, we use a Transformer-based neural architecture which allows the "retrieval" of relevant objects for action anticipation at various time scales. We conduct extensive evaluations on the Ego4D, 50Salads, and EGTEA Gaze+ benchmarks. Both quantitative and qualitative results confirm the effectiveness of our proposed method.
Rank2Tell: A Multimodal Driving Dataset for Joint Importance Ranking and Reasoning
Sep 12, 2023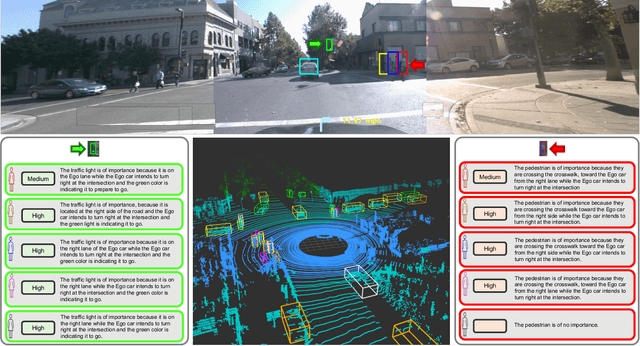
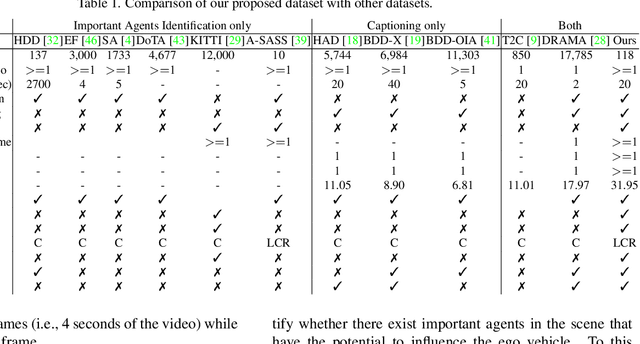
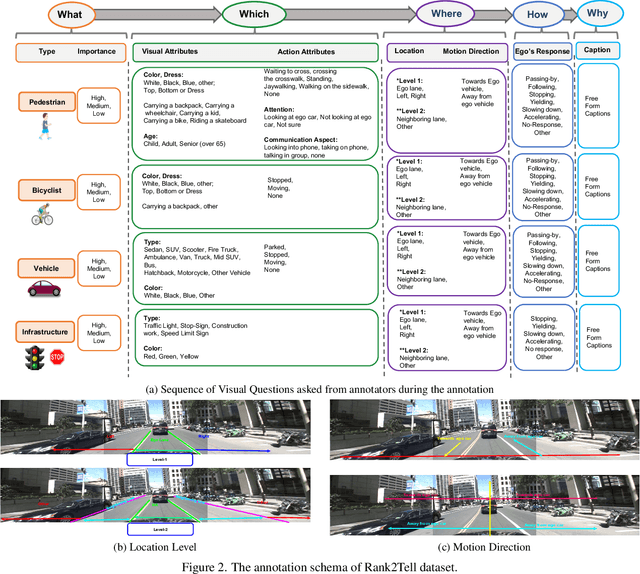
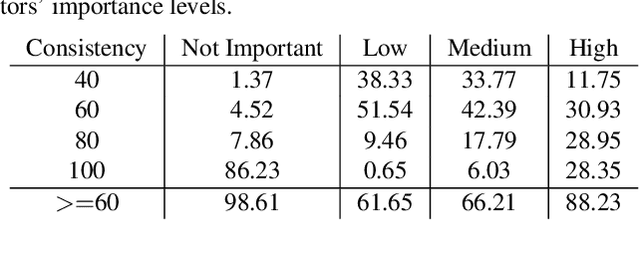
The widespread adoption of commercial autonomous vehicles (AVs) and advanced driver assistance systems (ADAS) may largely depend on their acceptance by society, for which their perceived trustworthiness and interpretability to riders are crucial. In general, this task is challenging because modern autonomous systems software relies heavily on black-box artificial intelligence models. Towards this goal, this paper introduces a novel dataset, Rank2Tell, a multi-modal ego-centric dataset for Ranking the importance level and Telling the reason for the importance. Using various close and open-ended visual question answering, the dataset provides dense annotations of various semantic, spatial, temporal, and relational attributes of various important objects in complex traffic scenarios. The dense annotations and unique attributes of the dataset make it a valuable resource for researchers working on visual scene understanding and related fields. Further, we introduce a joint model for joint importance level ranking and natural language captions generation to benchmark our dataset and demonstrate performance with quantitative evaluations.
AntGPT: Can Large Language Models Help Long-term Action Anticipation from Videos?
Jul 31, 2023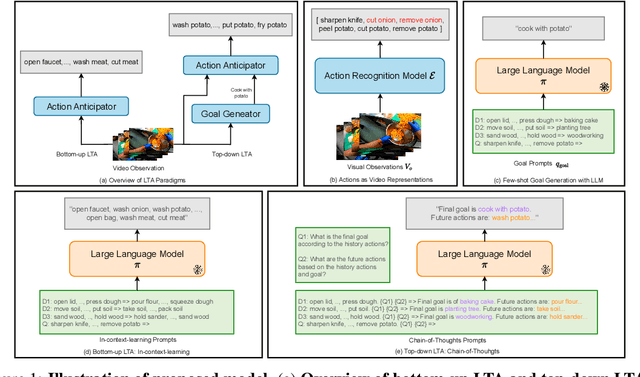
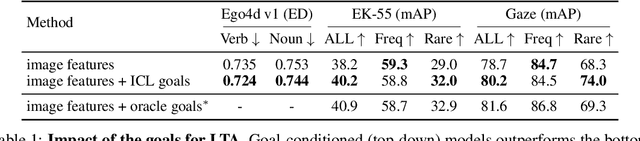

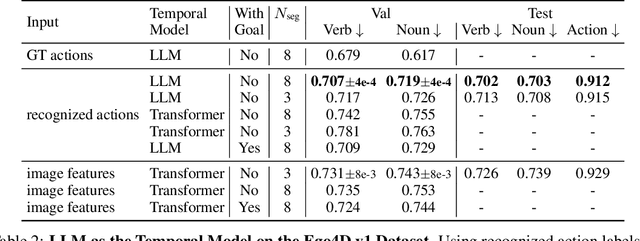
Can we better anticipate an actor's future actions (e.g. mix eggs) by knowing what commonly happens after his/her current action (e.g. crack eggs)? What if we also know the longer-term goal of the actor (e.g. making egg fried rice)? The long-term action anticipation (LTA) task aims to predict an actor's future behavior from video observations in the form of verb and noun sequences, and it is crucial for human-machine interaction. We propose to formulate the LTA task from two perspectives: a bottom-up approach that predicts the next actions autoregressively by modeling temporal dynamics; and a top-down approach that infers the goal of the actor and plans the needed procedure to accomplish the goal. We hypothesize that large language models (LLMs), which have been pretrained on procedure text data (e.g. recipes, how-tos), have the potential to help LTA from both perspectives. It can help provide the prior knowledge on the possible next actions, and infer the goal given the observed part of a procedure, respectively. To leverage the LLMs, we propose a two-stage framework, AntGPT. It first recognizes the actions already performed in the observed videos and then asks an LLM to predict the future actions via conditioned generation, or to infer the goal and plan the whole procedure by chain-of-thought prompting. Empirical results on the Ego4D LTA v1 and v2 benchmarks, EPIC-Kitchens-55, as well as EGTEA GAZE+ demonstrate the effectiveness of our proposed approach. AntGPT achieves state-of-the-art performance on all above benchmarks, and can successfully infer the goal and thus perform goal-conditioned "counterfactual" prediction via qualitative analysis. Code and model will be released at https://brown-palm.github.io/AntGPT
Weakly-Supervised Online Action Segmentation in Multi-View Instructional Videos
Mar 24, 2022



This paper addresses a new problem of weakly-supervised online action segmentation in instructional videos. We present a framework to segment streaming videos online at test time using Dynamic Programming and show its advantages over greedy sliding window approach. We improve our framework by introducing the Online-Offline Discrepancy Loss (OODL) to encourage the segmentation results to have a higher temporal consistency. Furthermore, only during training, we exploit frame-wise correspondence between multiple views as supervision for training weakly-labeled instructional videos. In particular, we investigate three different multi-view inference techniques to generate more accurate frame-wise pseudo ground-truth with no additional annotation cost. We present results and ablation studies on two benchmark multi-view datasets, Breakfast and IKEA ASM. Experimental results show efficacy of the proposed methods both qualitatively and quantitatively in two domains of cooking and assembly.
Unsupervised Domain Adaptation for Spatio-Temporal Action Localization
Oct 19, 2020



Spatio-temporal action localization is an important problem in computer vision that involves detecting where and when activities occur, and therefore requires modeling of both spatial and temporal features. This problem is typically formulated in the context of supervised learning, where the learned classifiers operate on the premise that both training and test data are sampled from the same underlying distribution. However, this assumption does not hold when there is a significant domain shift, leading to poor generalization performance on the test data. To address this, we focus on the hard and novel task of generalizing training models to test samples without access to any labels from the latter for spatio-temporal action localization by proposing an end-to-end unsupervised domain adaptation algorithm. We extend the state-of-the-art object detection framework to localize and classify actions. In order to minimize the domain shift, three domain adaptation modules at image level (temporal and spatial) and instance level (temporal) are designed and integrated. We design a new experimental setup and evaluate the proposed method and different adaptation modules on the UCF-Sports, UCF-101 and JHMDB benchmark datasets. We show that significant performance gain can be achieved when spatial and temporal features are adapted separately, or jointly for the most effective results.
Connecting Visual Experiences using Max-flow Network with Application to Visual Localization
Aug 01, 2018



We are motivated by the fact that multiple representations of the environment are required to stand for the changes in appearance with time and for changes that appear in a cyclic manner. These changes are, for example, from day to night time, and from day to day across seasons. In such situations, the robot visits the same routes multiple times and collects different appearances of it. Multiple visual experiences usually find robotic vision applications like visual localization, mapping, place recognition, and autonomous navigation. The novelty in this paper is an algorithm that connects multiple visual experiences via aligning multiple image sequences. This problem is solved by finding the maximum flow in a directed graph flow-network, whose vertices represent the matches between frames in the test and reference sequences. Edges of the graph represent the cost of these matches. The problem of finding the best match is reduced to finding the minimum-cut surface, which is solved as a maximum flow network problem. Application to visual localization is considered in this paper to show the effectiveness of the proposed multiple image sequence alignment method, without loosing its generality. Experimental evaluations show that the precision of sequence matching is improved by considering multiple visual sequences for the same route, and that the method performs favorably against state-of-the-art single representation methods like SeqSLAM and ABLE-M.