 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNalini Ratha
Confidential and Protected Disease Classifier using Fully Homomorphic Encryption
May 05, 2024
With the rapid surge in the prevalence of Large Language Models (LLMs), individuals are increasingly turning to conversational AI for initial insights across various domains, including health-related inquiries such as disease diagnosis. Many users seek potential causes on platforms like ChatGPT or Bard before consulting a medical professional for their ailment. These platforms offer valuable benefits by streamlining the diagnosis process, alleviating the significant workload of healthcare practitioners, and saving users both time and money by avoiding unnecessary doctor visits. However, Despite the convenience of such platforms, sharing personal medical data online poses risks, including the presence of malicious platforms or potential eavesdropping by attackers. To address privacy concerns, we propose a novel framework combining FHE and Deep Learning for a secure and private diagnosis system. Operating on a question-and-answer-based model akin to an interaction with a medical practitioner, this end-to-end secure system employs Fully Homomorphic Encryption (FHE) to handle encrypted input data. Given FHE's computational constraints, we adapt deep neural networks and activation functions to the encryted domain. Further, we also propose a faster algorithm to compute summation of ciphertext elements. Through rigorous experiments, we demonstrate the efficacy of our approach. The proposed framework achieves strict security and privacy with minimal loss in performance.
Enhancing Privacy and Security of Autonomous UAV Navigation
Apr 26, 2024Autonomous Unmanned Aerial Vehicles (UAVs) have become essential tools in defense, law enforcement, disaster response, and product delivery. These autonomous navigation systems require a wireless communication network, and of late are deep learning based. In critical scenarios such as border protection or disaster response, ensuring the secure navigation of autonomous UAVs is paramount. But, these autonomous UAVs are susceptible to adversarial attacks through the communication network or the deep learning models - eavesdropping / man-in-the-middle / membership inference / reconstruction. To address this susceptibility, we propose an innovative approach that combines Reinforcement Learning (RL) and Fully Homomorphic Encryption (FHE) for secure autonomous UAV navigation. This end-to-end secure framework is designed for real-time video feeds captured by UAV cameras and utilizes FHE to perform inference on encrypted input images. While FHE allows computations on encrypted data, certain computational operators are yet to be implemented. Convolutional neural networks, fully connected neural networks, activation functions and OpenAI Gym Library are meticulously adapted to the FHE domain to enable encrypted data processing. We demonstrate the efficacy of our proposed approach through extensive experimentation. Our proposed approach ensures security and privacy in autonomous UAV navigation with negligible loss in performance.
Enhancing Privacy in Face Analytics Using Fully Homomorphic Encryption
Apr 24, 2024Modern face recognition systems utilize deep neural networks to extract salient features from a face. These features denote embeddings in latent space and are often stored as templates in a face recognition system. These embeddings are susceptible to data leakage and, in some cases, can even be used to reconstruct the original face image. To prevent compromising identities, template protection schemes are commonly employed. However, these schemes may still not prevent the leakage of soft biometric information such as age, gender and race. To alleviate this issue, we propose a novel technique that combines Fully Homomorphic Encryption (FHE) with an existing template protection scheme known as PolyProtect. We show that the embeddings can be compressed and encrypted using FHE and transformed into a secure PolyProtect template using polynomial transformation, for additional protection. We demonstrate the efficacy of the proposed approach through extensive experiments on multiple datasets. Our proposed approach ensures irreversibility and unlinkability, effectively preventing the leakage of soft biometric attributes from face embeddings without compromising recognition accuracy.
RidgeBase: A Cross-Sensor Multi-Finger Contactless Fingerprint Dataset
Jul 09, 2023



Contactless fingerprint matching using smartphone cameras can alleviate major challenges of traditional fingerprint systems including hygienic acquisition, portability and presentation attacks. However, development of practical and robust contactless fingerprint matching techniques is constrained by the limited availability of large scale real-world datasets. To motivate further advances in contactless fingerprint matching across sensors, we introduce the RidgeBase benchmark dataset. RidgeBase consists of more than 15,000 contactless and contact-based fingerprint image pairs acquired from 88 individuals under different background and lighting conditions using two smartphone cameras and one flatbed contact sensor. Unlike existing datasets, RidgeBase is designed to promote research under different matching scenarios that include Single Finger Matching and Multi-Finger Matching for both contactless- to-contactless (CL2CL) and contact-to-contactless (C2CL) verification and identification. Furthermore, due to the high intra-sample variance in contactless fingerprints belonging to the same finger, we propose a set-based matching protocol inspired by the advances in facial recognition datasets. This protocol is specifically designed for pragmatic contactless fingerprint matching that can account for variances in focus, polarity and finger-angles. We report qualitative and quantitative baseline results for different protocols using a COTS fingerprint matcher (Verifinger) and a Deep CNN based approach on the RidgeBase dataset. The dataset can be downloaded here: https://www.buffalo.edu/cubs/research/datasets/ridgebase-benchmark-dataset.html
* Paper accepted at IJCB 2022
HEFT: Homomorphically Encrypted Fusion of Biometric Templates
Aug 15, 2022



This paper proposes a non-interactive end-to-end solution for secure fusion and matching of biometric templates using fully homomorphic encryption (FHE). Given a pair of encrypted feature vectors, we perform the following ciphertext operations, i) feature concatenation, ii) fusion and dimensionality reduction through a learned linear projection, iii) scale normalization to unit $\ell_2$-norm, and iv) match score computation. Our method, dubbed HEFT (Homomorphically Encrypted Fusion of biometric Templates), is custom-designed to overcome the unique constraint imposed by FHE, namely the lack of support for non-arithmetic operations. From an inference perspective, we systematically explore different data packing schemes for computationally efficient linear projection and introduce a polynomial approximation for scale normalization. From a training perspective, we introduce an FHE-aware algorithm for learning the linear projection matrix to mitigate errors induced by approximate normalization. Experimental evaluation for template fusion and matching of face and voice biometrics shows that HEFT (i) improves biometric verification performance by 11.07% and 9.58% AUROC compared to the respective unibiometric representations while compressing the feature vectors by a factor of 16 (512D to 32D), and (ii) fuses a pair of encrypted feature vectors and computes its match score against a gallery of size 1024 in 884 ms. Code and data are available at https://github.com/human-analysis/encrypted-biometric-fusion
Efficient Encrypted Inference on Ensembles of Decision Trees
Mar 05, 2021

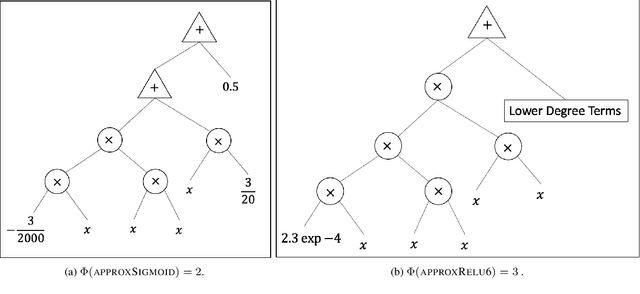
Data privacy concerns often prevent the use of cloud-based machine learning services for sensitive personal data. While homomorphic encryption (HE) offers a potential solution by enabling computations on encrypted data, the challenge is to obtain accurate machine learning models that work within the multiplicative depth constraints of a leveled HE scheme. Existing approaches for encrypted inference either make ad-hoc simplifications to a pre-trained model (e.g., replace hard comparisons in a decision tree with soft comparators) at the cost of accuracy or directly train a new depth-constrained model using the original training set. In this work, we propose a framework to transfer knowledge extracted by complex decision tree ensembles to shallow neural networks (referred to as DTNets) that are highly conducive to encrypted inference. Our approach minimizes the accuracy loss by searching for the best DTNet architecture that operates within the given depth constraints and training this DTNet using only synthetic data sampled from the training data distribution. Extensive experiments on real-world datasets demonstrate that these characteristics are critical in ensuring that DTNet accuracy approaches that of the original tree ensemble. Our system is highly scalable and can perform efficient inference on batched encrypted (134 bits of security) data with amortized time in milliseconds. This is approximately three orders of magnitude faster than the standard approach of applying soft comparison at the internal nodes of the ensemble trees.
Efficient CNN Building Blocks for Encrypted Data
Jan 30, 2021



Machine learning on encrypted data can address the concerns related to privacy and legality of sharing sensitive data with untrustworthy service providers. Fully Homomorphic Encryption (FHE) is a promising technique to enable machine learning and inferencing while providing strict guarantees against information leakage. Since deep convolutional neural networks (CNNs) have become the machine learning tool of choice in several applications, several attempts have been made to harness CNNs to extract insights from encrypted data. However, existing works focus only on ensuring data security and ignore security of model parameters. They also report high level implementations without providing rigorous analysis of the accuracy, security, and speed trade-offs involved in the FHE implementation of generic primitive operators of a CNN such as convolution, non-linear activation, and pooling. In this work, we consider a Machine Learning as a Service (MLaaS) scenario where both input data and model parameters are secured using FHE. Using the CKKS scheme available in the open-source HElib library, we show that operational parameters of the chosen FHE scheme such as the degree of the cyclotomic polynomial, depth limitations of the underlying leveled HE scheme, and the computational precision parameters have a major impact on the design of the machine learning model (especially, the choice of the activation function and pooling method). Our empirical study shows that choice of aforementioned design parameters result in significant trade-offs between accuracy, security level, and computational time. Encrypted inference experiments on the MNIST dataset indicate that other design choices such as ciphertext packing strategy and parallelization using multithreading are also critical in determining the throughput and latency of the inference process.
Trustworthy AI
Nov 02, 2020
Modern AI systems are reaping the advantage of novel learning methods. With their increasing usage, we are realizing the limitations and shortfalls of these systems. Brittleness to minor adversarial changes in the input data, ability to explain the decisions, address the bias in their training data, high opacity in terms of revealing the lineage of the system, how they were trained and tested, and under which parameters and conditions they can reliably guarantee a certain level of performance, are some of the most prominent limitations. Ensuring the privacy and security of the data, assigning appropriate credits to data sources, and delivering decent outputs are also required features of an AI system. We propose the tutorial on Trustworthy AI to address six critical issues in enhancing user and public trust in AI systems, namely: (i) bias and fairness, (ii) explainability, (iii) robust mitigation of adversarial attacks, (iv) improved privacy and security in model building, (v) being decent, and (vi) model attribution, including the right level of credit assignment to the data sources, model architectures, and transparency in lineage.
Deep Learning for Face Recognition: Pride or Prejudiced?
Apr 02, 2019



Do very high accuracies of deep networks suggest pride of effective AI or are deep networks prejudiced? Do they suffer from in-group biases (own-race-bias and own-age-bias), and mimic the human behavior? Is in-group specific information being encoded sub-consciously by the deep networks? This research attempts to answer these questions and presents an in-depth analysis of `bias' in deep learning based face recognition systems. This is the first work which decodes if and where bias is encoded for face recognition. Taking cues from cognitive studies, we inspect if deep networks are also affected by social in- and out-group effect. Networks are analyzed for own-race and own-age bias, both of which have been well established in human beings. The sub-conscious behavior of face recognition models is examined to understand if they encode race or age specific features for face recognition. Analysis is performed based on 36 experiments conducted on multiple datasets. Four deep learning networks either trained from scratch or pre-trained on over 10M images are used. Variations across class activation maps and feature visualizations provide novel insights into the functioning of deep learning systems, suggesting behavior similar to humans. It is our belief that a better understanding of state-of-the-art deep learning networks would enable researchers to address the given challenge of bias in AI, and develop fairer systems.
Diversity in Faces
Jan 30, 2019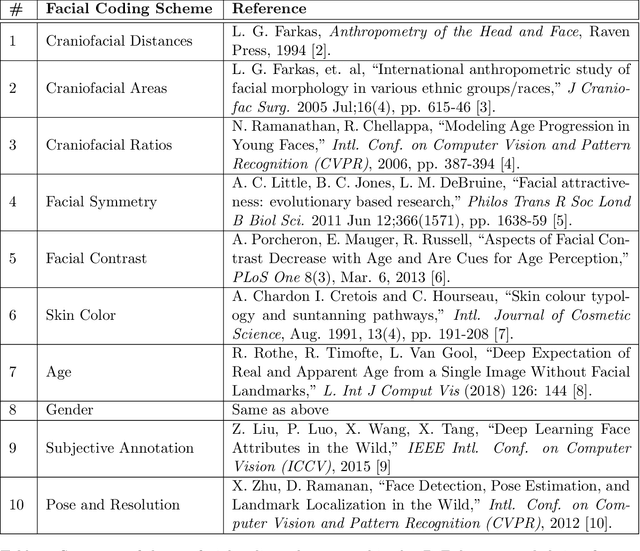
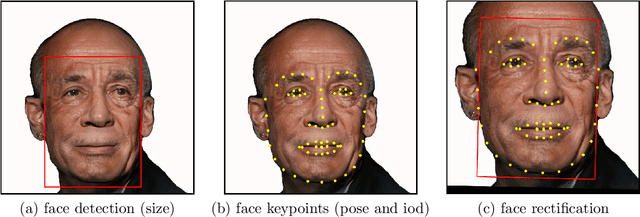
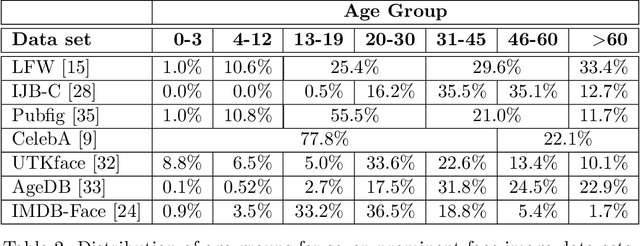
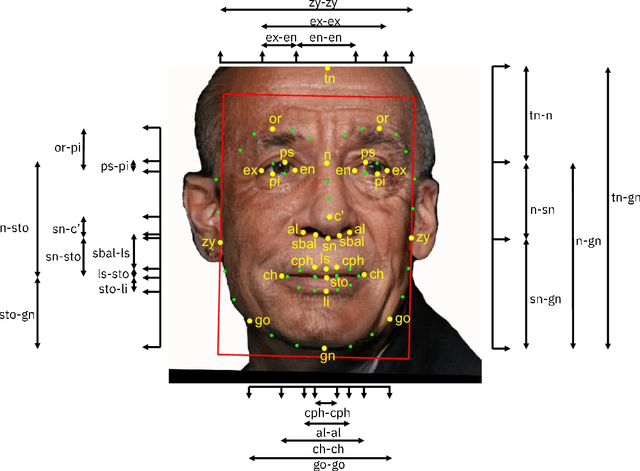
Face recognition is a long standing challenge in the field of Artificial Intelligence (AI). The goal is to create systems that accurately detect, recognize, verify, and understand human faces. There are significant technical hurdles in making these systems accurate, particularly in unconstrained settings due to confounding factors related to pose, resolution, illumination, occlusion, and viewpoint. However, with recent advances in neural networks, face recognition has achieved unprecedented accuracy, largely built on data-driven deep learning methods. While this is encouraging, a critical aspect that is limiting facial recognition accuracy and fairness is inherent facial diversity. Every face is different. Every face reflects something unique about us. Aspects of our heritage - including race, ethnicity, culture, geography - and our individual identify - age, gender, and other visible manifestations of self-expression, are reflected in our faces. We expect face recognition to work equally accurately for every face. Face recognition needs to be fair. As we rely on data-driven methods to create face recognition technology, we need to ensure necessary balance and coverage in training data. However, there are still scientific questions about how to represent and extract pertinent facial features and quantitatively measure facial diversity. Towards this goal, Diversity in Faces (DiF) provides a data set of one million annotated human face images for advancing the study of facial diversity. The annotations are generated using ten well-established facial coding schemes from the scientific literature. The facial coding schemes provide human-interpretable quantitative measures of facial features. We believe that by making the extracted coding schemes available on a large set of faces, we can accelerate research and development towards creating more fair and accurate facial recognition systems.