 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNasir Ahmad
Efficient Deep Learning with Decorrelated Backpropagation
May 03, 2024
The backpropagation algorithm remains the dominant and most successful method for training deep neural networks (DNNs). At the same time, training DNNs at scale comes at a significant computational cost and therefore a high carbon footprint. Converging evidence suggests that input decorrelation may speed up deep learning. However, to date, this has not yet translated into substantial improvements in training efficiency in large-scale DNNs. This is mainly caused by the challenge of enforcing fast and stable network-wide decorrelation. Here, we show for the first time that much more efficient training of very deep neural networks using decorrelated backpropagation is feasible. To achieve this goal we made use of a novel algorithm which induces network-wide input decorrelation using minimal computational overhead. By combining this algorithm with careful optimizations, we obtain a more than two-fold speed-up and higher test accuracy compared to backpropagation when training a 18-layer deep residual network. This demonstrates that decorrelation provides exciting prospects for efficient deep learning at scale.
A Named Entity Recognition and Topic Modeling-based Solution for Locating and Better Assessment of Natural Disasters in Social Media
May 01, 2024Over the last decade, similar to other application domains, social media content has been proven very effective in disaster informatics. However, due to the unstructured nature of the data, several challenges are associated with disaster analysis in social media content. To fully explore the potential of social media content in disaster informatics, access to relevant content and the correct geo-location information is very critical. In this paper, we propose a three-step solution to tackling these challenges. Firstly, the proposed solution aims to classify social media posts into relevant and irrelevant posts followed by the automatic extraction of location information from the posts' text through Named Entity Recognition (NER) analysis. Finally, to quickly analyze the topics covered in large volumes of social media posts, we perform topic modeling resulting in a list of top keywords, that highlight the issues discussed in the tweet. For the Relevant Classification of Twitter Posts (RCTP), we proposed a merit-based fusion framework combining the capabilities of four different models namely BERT, RoBERTa, Distil BERT, and ALBERT obtaining the highest F1-score of 0.933 on a benchmark dataset. For the Location Extraction from Twitter Text (LETT), we evaluated four models namely BERT, RoBERTa, Distil BERTA, and Electra in an NER framework obtaining the highest F1-score of 0.960. For topic modeling, we used the BERTopic library to discover the hidden topic patterns in the relevant tweets. The experimental results of all the components of the proposed end-to-end solution are very encouraging and hint at the potential of social media content and NLP in disaster management.
Social Media and Artificial Intelligence for Sustainable Cities and Societies: A Water Quality Analysis Use-case
Apr 23, 2024This paper focuses on a very important societal challenge of water quality analysis. Being one of the key factors in the economic and social development of society, the provision of water and ensuring its quality has always remained one of the top priorities of public authorities. To ensure the quality of water, different methods for monitoring and assessing the water networks, such as offline and online surveys, are used. However, these surveys have several limitations, such as the limited number of participants and low frequency due to the labor involved in conducting such surveys. In this paper, we propose a Natural Language Processing (NLP) framework to automatically collect and analyze water-related posts from social media for data-driven decisions. The proposed framework is composed of two components, namely (i) text classification, and (ii) topic modeling. For text classification, we propose a merit-fusion-based framework incorporating several Large Language Models (LLMs) where different weight selection and optimization methods are employed to assign weights to the LLMs. In topic modeling, we employed the BERTopic library to discover the hidden topic patterns in the water-related tweets. We also analyzed relevant tweets originating from different regions and countries to explore global, regional, and country-specific issues and water-related concerns. We also collected and manually annotated a large-scale dataset, which is expected to facilitate future research on the topic.
Stylometry Analysis of Multi-authored Documents for Authorship and Author Style Change Detection
Jan 12, 2024In recent years, the increasing use of Artificial Intelligence based text generation tools has posed new challenges in document provenance, authentication, and authorship detection. However, advancements in stylometry have provided opportunities for automatic authorship and author change detection in multi-authored documents using style analysis techniques. Style analysis can serve as a primary step toward document provenance and authentication through authorship detection. This paper investigates three key tasks of style analysis: (i) classification of single and multi-authored documents, (ii) single change detection, which involves identifying the point where the author switches, and (iii) multiple author-switching detection in multi-authored documents. We formulate all three tasks as classification problems and propose a merit-based fusion framework that integrates several state-of-the-art natural language processing (NLP) algorithms and weight optimization techniques. We also explore the potential of special characters, which are typically removed during pre-processing in NLP applications, on the performance of the proposed methods for these tasks by conducting extensive experiments on both cleaned and raw datasets. Experimental results demonstrate significant improvements over existing solutions for all three tasks on a benchmark dataset.
Effective Learning with Node Perturbation in Deep Neural Networks
Oct 02, 2023Backpropagation (BP) is the dominant and most successful method for training parameters of deep neural network models. However, BP relies on two computationally distinct phases, does not provide a satisfactory explanation of biological learning, and can be challenging to apply for training of networks with discontinuities or noisy node dynamics. By comparison, node perturbation (NP) proposes learning by the injection of noise into the network activations, and subsequent measurement of the induced loss change. NP relies on two forward (inference) passes, does not make use of network derivatives, and has been proposed as a model for learning in biological systems. However, standard NP is highly data inefficient and unstable due to its unguided, noise-based, activity search. In this work, we investigate different formulations of NP and relate it to the concept of directional derivatives as well as combining it with a decorrelating mechanism for layer-wise inputs. We find that a closer alignment with directional derivatives, and induction of decorrelation of inputs at every layer significantly enhances performance of NP learning making it competitive with BP.
Document Provenance and Authentication through Authorship Classification
Mar 02, 2023



Style analysis, which is relatively a less explored topic, enables several interesting applications. For instance, it allows authors to adjust their writing style to produce a more coherent document in collaboration. Similarly, style analysis can also be used for document provenance and authentication as a primary step. In this paper, we propose an ensemble-based text-processing framework for the classification of single and multi-authored documents, which is one of the key tasks in style analysis. The proposed framework incorporates several state-of-the-art text classification algorithms including classical Machine Learning (ML) algorithms, transformers, and deep learning algorithms both individually and in merit-based late fusion. For the merit-based late fusion, we employed several weight optimization and selection methods to assign merit-based weights to the individual text classification algorithms. We also analyze the impact of the characters on the task that are usually excluded in NLP applications during pre-processing by conducting experiments on both clean and un-clean data. The proposed framework is evaluated on a large-scale benchmark dataset, significantly improving performance over the existing solutions.
* 7 pages; 3 tables; 1 figure
Floods Relevancy and Identification of Location from Twitter Posts using NLP Techniques
Jan 01, 2023

This paper presents our solutions for the MediaEval 2022 task on DisasterMM. The task is composed of two subtasks, namely (i) Relevance Classification of Twitter Posts (RCTP), and (ii) Location Extraction from Twitter Texts (LETT). The RCTP subtask aims at differentiating flood-related and non-relevant social posts while LETT is a Named Entity Recognition (NER) task and aims at the extraction of location information from the text. For RCTP, we proposed four different solutions based on BERT, RoBERTa, Distil BERT, and ALBERT obtaining an F1-score of 0.7934, 0.7970, 0.7613, and 0.7924, respectively. For LETT, we used three models namely BERT, RoBERTa, and Distil BERTA obtaining an F1-score of 0.6256, 0.6744, and 0.6723, respectively.
Efficient Deep Reinforcement Learning with Predictive Processing Proximal Policy Optimization
Nov 11, 2022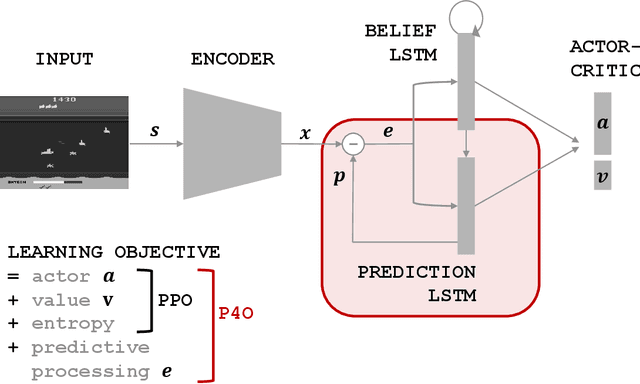

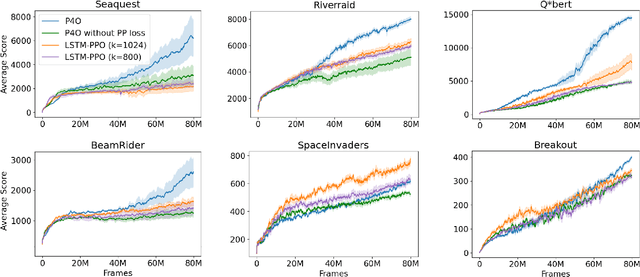
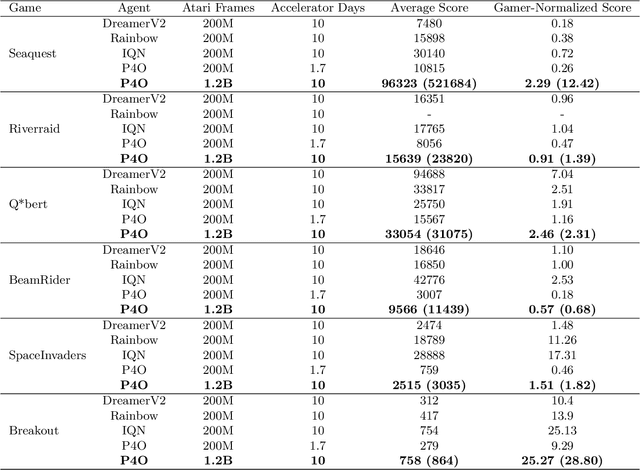
Advances in reinforcement learning (RL) often rely on massive compute resources and remain notoriously sample inefficient. In contrast, the human brain is able to efficiently learn effective control strategies using limited resources. This raises the question whether insights from neuroscience can be used to improve current RL methods. Predictive processing is a popular theoretical framework which maintains that the human brain is actively seeking to minimize surprise. We show that recurrent neural networks which predict their own sensory states can be leveraged to minimise surprise, yielding substantial gains in cumulative reward. Specifically, we present the Predictive Processing Proximal Policy Optimization (P4O) agent; an actor-critic reinforcement learning agent that applies predictive processing to a recurrent variant of the PPO algorithm by integrating a world model in its hidden state. P4O significantly outperforms a baseline recurrent variant of the PPO algorithm on multiple Atari games using a single GPU. It also outperforms other state-of-the-art agents given the same wall-clock time and exceeds human gamer performance on multiple games including Seaquest, which is a particularly challenging environment in the Atari domain. Altogether, our work underscores how insights from the field of neuroscience may support the development of more capable and efficient artificial agents.
A Late Fusion Framework with Multiple Optimization Methods for Media Interestingness
Jul 11, 2022

The recent advancement in Multimedia Analytical, Computer Vision (CV), and Artificial Intelligence (AI) algorithms resulted in several interesting tools allowing an automatic analysis and retrieval of multimedia content of users' interests. However, retrieving the content of interest generally involves analysis and extraction of semantic features, such as emotions and interestingness-level. The extraction of such meaningful information is a complex task and generally, the performance of individual algorithms is very low. One way to enhance the performance of the individual algorithms is to combine the predictive capabilities of multiple algorithms using fusion schemes. This allows the individual algorithms to complement each other, leading to improved performance. This paper proposes several fusion methods for the media interestingness score prediction task introduced in CLEF Fusion 2022. The proposed methods include both a naive fusion scheme, where all the inducers are treated equally and a merit-based fusion scheme where multiple weight optimization methods are employed to assign weights to the individual inducers. In total, we used six optimization methods including a Particle Swarm Optimization (PSO), a Genetic Algorithm (GA), Nelder Mead, Trust Region Constrained (TRC), and Limited-memory Broyden Fletcher Goldfarb Shanno Algorithm (LBFGSA), and Truncated Newton Algorithm (TNA). Overall better results are obtained with PSO and TNA achieving 0.109 mean average precision at 10. The task is complex and generally, scores are low. We believe the presented analysis will provide a baseline for future research in the domain.
An Explainable Regression Framework for Predicting Remaining Useful Life of Machines
Apr 30, 2022



Prediction of a machine's Remaining Useful Life (RUL) is one of the key tasks in predictive maintenance. The task is treated as a regression problem where Machine Learning (ML) algorithms are used to predict the RUL of machine components. These ML algorithms are generally used as a black box with a total focus on the performance without identifying the potential causes behind the algorithms' decisions and their working mechanism. We believe, the performance (in terms of Mean Squared Error (MSE), etc.,) alone is not enough to build the trust of the stakeholders in ML prediction rather more insights on the causes behind the predictions are needed. To this aim, in this paper, we explore the potential of Explainable AI (XAI) techniques by proposing an explainable regression framework for the prediction of machines' RUL. We also evaluate several ML algorithms including classical and Neural Networks (NNs) based solutions for the task. For the explanations, we rely on two model agnostic XAI methods namely Local Interpretable Model-Agnostic Explanations (LIME) and Shapley Additive Explanations (SHAP). We believe, this work will provide a baseline for future research in the domain.