 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatalia Vassilieva
Med42 -- Evaluating Fine-Tuning Strategies for Medical LLMs: Full-Parameter vs. Parameter-Efficient Approaches
Apr 23, 2024
This study presents a comprehensive analysis and comparison of two predominant fine-tuning methodologies - full-parameter fine-tuning and parameter-efficient tuning - within the context of medical Large Language Models (LLMs). We developed and refined a series of LLMs, based on the Llama-2 architecture, specifically designed to enhance medical knowledge retrieval, reasoning, and question-answering capabilities. Our experiments systematically evaluate the effectiveness of these tuning strategies across various well-known medical benchmarks. Notably, our medical LLM Med42 showed an accuracy level of 72% on the US Medical Licensing Examination (USMLE) datasets, setting a new standard in performance for openly available medical LLMs. Through this comparative analysis, we aim to identify the most effective and efficient method for fine-tuning LLMs in the medical domain, thereby contributing significantly to the advancement of AI-driven healthcare applications.
BTLM-3B-8K: 7B Parameter Performance in a 3B Parameter Model
Sep 20, 2023
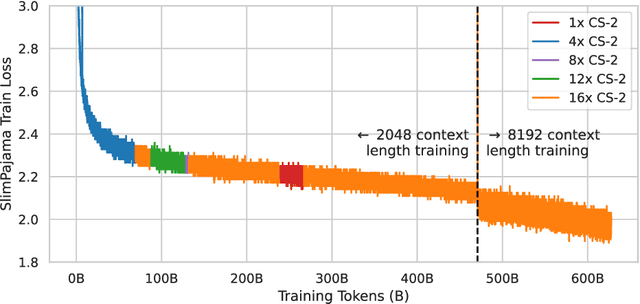
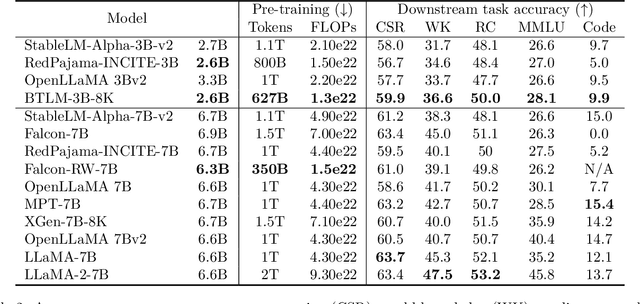

We introduce the Bittensor Language Model, called "BTLM-3B-8K", a new state-of-the-art 3 billion parameter open-source language model. BTLM-3B-8K was trained on 627B tokens from the SlimPajama dataset with a mixture of 2,048 and 8,192 context lengths. BTLM-3B-8K outperforms all existing 3B parameter models by 2-5.5% across downstream tasks. BTLM-3B-8K is even competitive with some 7B parameter models. Additionally, BTLM-3B-8K provides excellent long context performance, outperforming MPT-7B-8K and XGen-7B-8K on tasks up to 8,192 context length. We trained the model on a cleaned and deduplicated SlimPajama dataset; aggressively tuned the \textmu P hyperparameters and schedule; used ALiBi position embeddings; and adopted the SwiGLU nonlinearity. On Hugging Face, the most popular models have 7B parameters, indicating that users prefer the quality-size ratio of 7B models. Compacting the 7B parameter model to one with 3B parameters, with little performance impact, is an important milestone. BTLM-3B-8K needs only 3GB of memory with 4-bit precision and takes 2.5x less inference compute than 7B models, helping to open up access to a powerful language model on mobile and edge devices. BTLM-3B-8K is available under an Apache 2.0 license on Hugging Face: https://huggingface.co/cerebras/btlm-3b-8k-base.
SlimPajama-DC: Understanding Data Combinations for LLM Training
Sep 19, 2023This paper aims to understand the impacts of various data combinations (e.g., web text, wikipedia, github, books) on the training of large language models using SlimPajama. SlimPajama is a rigorously deduplicated, multi-source dataset, which has been refined and further deduplicated to 627B tokens from the extensive 1.2T tokens RedPajama dataset contributed by Together. We've termed our research as SlimPajama-DC, an empirical analysis designed to uncover fundamental characteristics and best practices associated with employing SlimPajama in the training of large language models. During our research with SlimPajama, two pivotal observations emerged: (1) Global deduplication vs. local deduplication. We analyze and discuss how global (across different sources of datasets) and local (within the single source of dataset) deduplications affect the performance of trained models. (2) Proportions of high-quality/highly-deduplicated multi-source datasets in the combination. To study this, we construct six configurations of SlimPajama dataset and train individual ones using 1.3B Cerebras-GPT model with Alibi and SwiGLU. Our best configuration outperforms the 1.3B model trained on RedPajama using the same number of training tokens by a significant margin. All our 1.3B models are trained on Cerebras 16$\times$ CS-2 cluster with a total of 80 PFLOP/s in bf16 mixed precision. We further extend our discoveries (such as increasing data diversity is crucial after global deduplication) on a 7B model with large batch-size training. Our models and the separate SlimPajama-DC datasets are available at: https://huggingface.co/MBZUAI-LLM and https://huggingface.co/datasets/cerebras/SlimPajama-627B.