 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeil Thompson
Algorithmic progress in language models
Mar 09, 2024
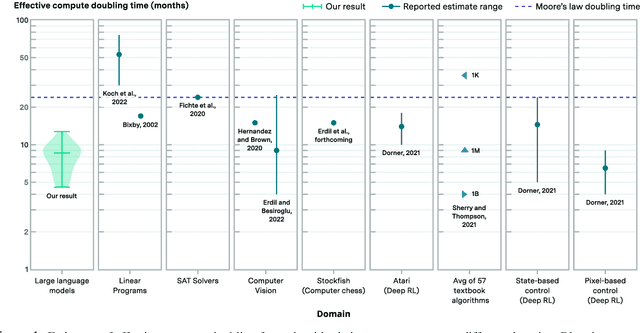



We investigate the rate at which algorithms for pre-training language models have improved since the advent of deep learning. Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012-2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore's Law. We estimate augmented scaling laws, which enable us to quantify algorithmic progress and determine the relative contributions of scaling models versus innovations in training algorithms. Despite the rapid pace of algorithmic progress and the development of new architectures such as the transformer, our analysis reveals that the increase in compute made an even larger contribution to overall performance improvements over this time period. Though limited by noisy benchmark data, our analysis quantifies the rapid progress in language modeling, shedding light on the relative contributions from compute and algorithms.
The Compute Divide in Machine Learning: A Threat to Academic Contribution and Scrutiny?
Jan 08, 2024There are pronounced differences in the extent to which industrial and academic AI labs use computing resources. We provide a data-driven survey of the role of the compute divide in shaping machine learning research. We show that a compute divide has coincided with a reduced representation of academic-only research teams in compute intensive research topics, especially foundation models. We argue that, academia will likely play a smaller role in advancing the associated techniques, providing critical evaluation and scrutiny, and in the diffusion of such models. Concurrent with this change in research focus, there is a noticeable shift in academic research towards embracing open source, pre-trained models developed within the industry. To address the challenges arising from this trend, especially reduced scrutiny of influential models, we recommend approaches aimed at thoughtfully expanding academic insights. Nationally-sponsored computing infrastructure coupled with open science initiatives could judiciously boost academic compute access, prioritizing research on interpretability, safety and security. Structured access programs and third-party auditing may also allow measured external evaluation of industry systems.
Large Language Model Routing with Benchmark Datasets
Sep 27, 2023There is a rapidly growing number of open-source Large Language Models (LLMs) and benchmark datasets to compare them. While some models dominate these benchmarks, no single model typically achieves the best accuracy in all tasks and use cases. In this work, we address the challenge of selecting the best LLM out of a collection of models for new tasks. We propose a new formulation for the problem, in which benchmark datasets are repurposed to learn a "router" model for this LLM selection, and we show that this problem can be reduced to a collection of binary classification tasks. We demonstrate the utility and limitations of learning model routers from various benchmark datasets, where we consistently improve performance upon using any single model for all tasks.
The Grand Illusion: The Myth of Software Portability and Implications for ML Progress
Sep 12, 2023Pushing the boundaries of machine learning often requires exploring different hardware and software combinations. However, the freedom to experiment across different tooling stacks can be at odds with the drive for efficiency, which has produced increasingly specialized AI hardware and incentivized consolidation around a narrow set of ML frameworks. Exploratory research can be restricted if software and hardware are co-evolving, making it even harder to stray away from mainstream ideas that work well with popular tooling stacks. While this friction increasingly impacts the rate of innovation in machine learning, to our knowledge the lack of portability in tooling has not been quantified. In this work, we ask: How portable are popular ML software frameworks? We conduct a large-scale study of the portability of mainstream ML frameworks across different hardware types. Our findings paint an uncomfortable picture -- frameworks can lose more than 40% of their key functions when ported to other hardware. Worse, even when functions are portable, the slowdown in their performance can be extreme and render performance untenable. Collectively, our results reveal how costly straying from a narrow set of hardware-software combinations can be - and suggest that specialization of hardware impedes innovation in machine learning research.