 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNgan Le
S3Former: Self-supervised High-resolution Transformer for Solar PV Profiling
May 07, 2024
As the impact of climate change escalates, the global necessity to transition to sustainable energy sources becomes increasingly evident. Renewable energies have emerged as a viable solution for users, with Photovoltaic energy being a favored choice for small installations due to its reliability and efficiency. Accurate mapping of PV installations is crucial for understanding the extension of its adoption and informing energy policy. To meet this need, we introduce S3Former, designed to segment solar panels from aerial imagery and provide size and location information critical for analyzing the impact of such installations on the grid. Solar panel identification is challenging due to factors such as varying weather conditions, roof characteristics, Ground Sampling Distance variations and lack of appropriate initialization weights for optimized training. To tackle these complexities, S3Former features a Masked Attention Mask Transformer incorporating a self-supervised learning pretrained backbone. Specifically, our model leverages low-level and high-level features extracted from the backbone and incorporates an instance query mechanism incorporated on the Transformer architecture to enhance the localization of solar PV installations. We introduce a self-supervised learning phase (pretext task) to improve the initialization weights on the backbone of S3Former. We evaluated S3Former using diverse datasets, demonstrate improvement state-of-the-art models.
CarcassFormer: An End-to-end Transformer-based Framework for Simultaneous Localization, Segmentation and Classification of Poultry Carcass Defect
Apr 17, 2024In the food industry, assessing the quality of poultry carcasses during processing is a crucial step. This study proposes an effective approach for automating the assessment of carcass quality without requiring skilled labor or inspector involvement. The proposed system is based on machine learning (ML) and computer vision (CV) techniques, enabling automated defect detection and carcass quality assessment. To this end, an end-to-end framework called CarcassFormer is introduced. It is built upon a Transformer-based architecture designed to effectively extract visual representations while simultaneously detecting, segmenting, and classifying poultry carcass defects. Our proposed framework is capable of analyzing imperfections resulting from production and transport welfare issues, as well as processing plant stunner, scalder, picker, and other equipment malfunctions. To benchmark the framework, a dataset of 7,321 images was initially acquired, which contained both single and multiple carcasses per image. In this study, the performance of the CarcassFormer system is compared with other state-of-the-art (SOTA) approaches for both classification, detection, and segmentation tasks. Through extensive quantitative experiments, our framework consistently outperforms existing methods, demonstrating remarkable improvements across various evaluation metrics such as AP, AP@50, and AP@75. Furthermore, the qualitative results highlight the strengths of CarcassFormer in capturing fine details, including feathers, and accurately localizing and segmenting carcasses with high precision. To facilitate further research and collaboration, the pre-trained model and source code of CarcassFormer is available for research purposes at: \url{https://github.com/UARK-AICV/CarcassFormer}.
Unifying Global and Local Scene Entities Modelling for Precise Action Spotting
Apr 15, 2024Sports videos pose complex challenges, including cluttered backgrounds, camera angle changes, small action-representing objects, and imbalanced action class distribution. Existing methods for detecting actions in sports videos heavily rely on global features, utilizing a backbone network as a black box that encompasses the entire spatial frame. However, these approaches tend to overlook the nuances of the scene and struggle with detecting actions that occupy a small portion of the frame. In particular, they face difficulties when dealing with action classes involving small objects, such as balls or yellow/red cards in soccer, which only occupy a fraction of the screen space. To address these challenges, we introduce a novel approach that analyzes and models scene entities using an adaptive attention mechanism. Particularly, our model disentangles the scene content into the global environment feature and local relevant scene entities feature. To efficiently extract environmental features while considering temporal information with less computational cost, we propose the use of a 2D backbone network with a time-shift mechanism. To accurately capture relevant scene entities, we employ a Vision-Language model in conjunction with the adaptive attention mechanism. Our model has demonstrated outstanding performance, securing the 1st place in the SoccerNet-v2 Action Spotting, FineDiving, and FineGym challenge with a substantial performance improvement of 1.6, 2.0, and 1.3 points in avg-mAP compared to the runner-up methods. Furthermore, our approach offers interpretability capabilities in contrast to other deep learning models, which are often designed as black boxes. Our code and models are released at: https://github.com/Fsoft-AIC/unifying-global-local-feature.
ShapeFormer: Shape Prior Visible-to-Amodal Transformer-based Amodal Instance Segmentation
Mar 22, 2024
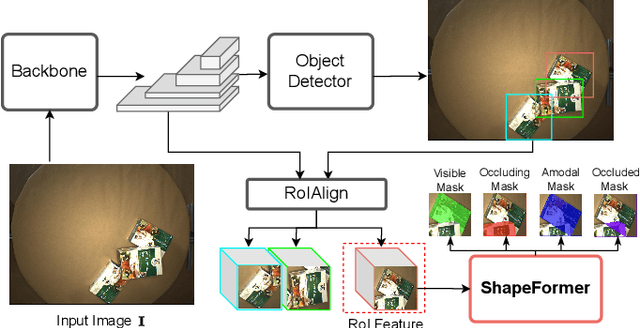
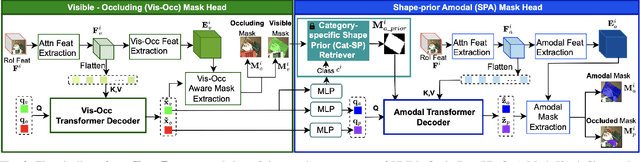
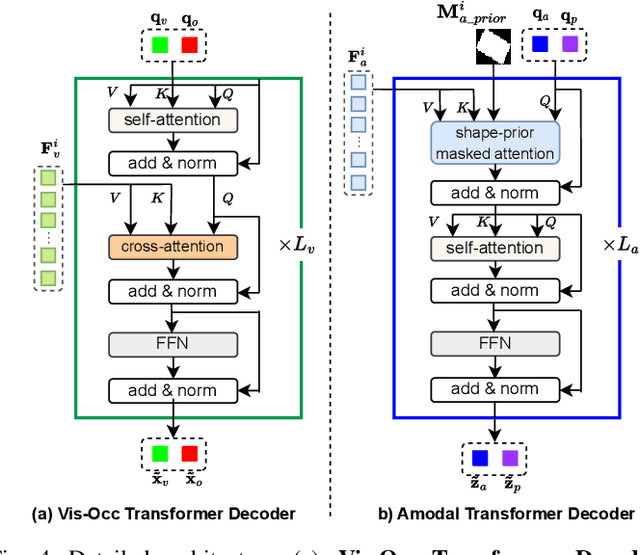
Amodal Instance Segmentation (AIS) presents a challenging task as it involves predicting both visible and occluded parts of objects within images. Existing AIS methods rely on a bidirectional approach, encompassing both the transition from amodal features to visible features (amodal-to-visible) and from visible features to amodal features (visible-to-amodal). Our observation shows that the utilization of amodal features through the amodal-to-visible can confuse the visible features due to the extra information of occluded/hidden segments not presented in visible display. Consequently, this compromised quality of visible features during the subsequent visible-to-amodal transition. To tackle this issue, we introduce ShapeFormer, a decoupled Transformer-based model with a visible-to-amodal transition. It facilitates the explicit relationship between output segmentations and avoids the need for amodal-to-visible transitions. ShapeFormer comprises three key modules: (i) Visible-Occluding Mask Head for predicting visible segmentation with occlusion awareness, (ii) Shape-Prior Amodal Mask Head for predicting amodal and occluded masks, and (iii) Category-Specific Shape Prior Retriever aims to provide shape prior knowledge. Comprehensive experiments and extensive ablation studies across various AIS benchmarks demonstrate the effectiveness of our ShapeFormer. The code is available at: https://github.com/UARK-AICV/ShapeFormer
WAVER: Writing-style Agnostic Video Retrieval via Distilling Vision-Language Models Through Open-Vocabulary Knowledge
Dec 27, 2023Text-video retrieval, a prominent sub-field within the domain of multimodal information retrieval, has witnessed remarkable growth in recent years. However, existing methods assume video scenes are consistent with unbiased descriptions. These limitations fail to align with real-world scenarios since descriptions can be influenced by annotator biases, diverse writing styles, and varying textual perspectives. To overcome the aforementioned problems, we introduce WAVER, a cross-domain knowledge distillation framework via vision-language models through open-vocabulary knowledge designed to tackle the challenge of handling different writing styles in video descriptions. WAVER capitalizes on the open-vocabulary properties that lie in pre-trained vision-language models and employs an implicit knowledge distillation approach to transfer text-based knowledge from a teacher model to a vision-based student. Empirical studies conducted across four standard benchmark datasets, encompassing various settings, provide compelling evidence that WAVER can achieve state-of-the-art performance in text-video retrieval task while handling writing-style variations.
TSRNet: Simple Framework for Real-time ECG Anomaly Detection with Multimodal Time and Spectrogram Restoration Network
Dec 15, 2023The electrocardiogram (ECG) is a valuable signal used to assess various aspects of heart health, such as heart rate and rhythm. It plays a crucial role in identifying cardiac conditions and detecting anomalies in ECG data. However, distinguishing between normal and abnormal ECG signals can be a challenging task. In this paper, we propose an approach that leverages anomaly detection to identify unhealthy conditions using solely normal ECG data for training. Furthermore, to enhance the information available and build a robust system, we suggest considering both the time series and time-frequency domain aspects of the ECG signal. As a result, we introduce a specialized network called the Multimodal Time and Spectrogram Restoration Network (TSRNet) designed specifically for detecting anomalies in ECG signals. TSRNet falls into the category of restoration-based anomaly detection and draws inspiration from both the time series and spectrogram domains. By extracting representations from both domains, TSRNet effectively captures the comprehensive characteristics of the ECG signal. This approach enables the network to learn robust representations with superior discrimination abilities, allowing it to distinguish between normal and abnormal ECG patterns more effectively. Furthermore, we introduce a novel inference method, termed Peak-based Error, that specifically focuses on ECG peaks, a critical component in detecting abnormalities. The experimental result on the large-scale dataset PTB-XL has demonstrated the effectiveness of our approach in ECG anomaly detection, while also prioritizing efficiency by minimizing the number of trainable parameters. Our code is available at https://github.com/UARK-AICV/TSRNet.
ZEETAD: Adapting Pretrained Vision-Language Model for Zero-Shot End-to-End Temporal Action Detection
Nov 04, 2023Temporal action detection (TAD) involves the localization and classification of action instances within untrimmed videos. While standard TAD follows fully supervised learning with closed-set setting on large training data, recent zero-shot TAD methods showcase the promising open-set setting by leveraging large-scale contrastive visual-language (ViL) pretrained models. However, existing zero-shot TAD methods have limitations on how to properly construct the strong relationship between two interdependent tasks of localization and classification and adapt ViL model to video understanding. In this work, we present ZEETAD, featuring two modules: dual-localization and zero-shot proposal classification. The former is a Transformer-based module that detects action events while selectively collecting crucial semantic embeddings for later recognition. The latter one, CLIP-based module, generates semantic embeddings from text and frame inputs for each temporal unit. Additionally, we enhance discriminative capability on unseen classes by minimally updating the frozen CLIP encoder with lightweight adapters. Extensive experiments on THUMOS14 and ActivityNet-1.3 datasets demonstrate our approach's superior performance in zero-shot TAD and effective knowledge transfer from ViL models to unseen action categories.
SolarFormer: Multi-scale Transformer for Solar PV Profiling
Oct 30, 2023As climate change intensifies, the global imperative to shift towards sustainable energy sources becomes more pronounced. Photovoltaic (PV) energy is a favored choice due to its reliability and ease of installation. Accurate mapping of PV installations is crucial for understanding their adoption and informing energy policy. To meet this need, we introduce the SolarFormer, designed to segment solar panels from aerial imagery, offering insights into their location and size. However, solar panel identification in Computer Vision is intricate due to various factors like weather conditions, roof conditions, and Ground Sampling Distance (GSD) variations. To tackle these complexities, we present the SolarFormer, featuring a multi-scale Transformer encoder and a masked-attention Transformer decoder. Our model leverages low-level features and incorporates an instance query mechanism to enhance the localization of solar PV installations. We rigorously evaluated our SolarFormer using diverse datasets, including GGE (France), IGN (France), and USGS (California, USA), across different GSDs. Our extensive experiments consistently demonstrate that our model either matches or surpasses state-of-the-art models, promising enhanced solar panel segmentation for global sustainable energy initiatives.
Open-Fusion: Real-time Open-Vocabulary 3D Mapping and Queryable Scene Representation
Oct 05, 2023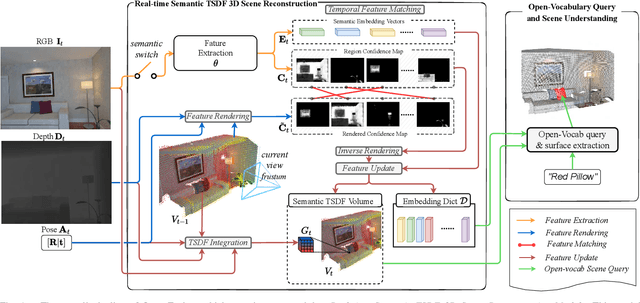



Precise 3D environmental mapping is pivotal in robotics. Existing methods often rely on predefined concepts during training or are time-intensive when generating semantic maps. This paper presents Open-Fusion, a groundbreaking approach for real-time open-vocabulary 3D mapping and queryable scene representation using RGB-D data. Open-Fusion harnesses the power of a pre-trained vision-language foundation model (VLFM) for open-set semantic comprehension and employs the Truncated Signed Distance Function (TSDF) for swift 3D scene reconstruction. By leveraging the VLFM, we extract region-based embeddings and their associated confidence maps. These are then integrated with 3D knowledge from TSDF using an enhanced Hungarian-based feature-matching mechanism. Notably, Open-Fusion delivers outstanding annotation-free 3D segmentation for open-vocabulary without necessitating additional 3D training. Benchmark tests on the ScanNet dataset against leading zero-shot methods highlight Open-Fusion's superiority. Furthermore, it seamlessly combines the strengths of region-based VLFM and TSDF, facilitating real-time 3D scene comprehension that includes object concepts and open-world semantics. We encourage the readers to view the demos on our project page: https://uark-aicv.github.io/OpenFusion
Decoding Radiologists Intense Focus for Accurate CXR Diagnoses: A Controllable and Interpretable AI System
Sep 26, 2023In the field of chest X-ray (CXR) diagnosis, existing works often focus solely on determining where a radiologist looks, typically through tasks such as detection, segmentation, or classification. However, these approaches are often designed as black-box models, lacking interpretability. In this paper, we introduce a novel and unified controllable interpretable pipeline for decoding the intense focus of radiologists in CXR diagnosis. Our approach addresses three key questions: where a radiologist looks, how long they focus on specific areas, and what findings they diagnose. By capturing the intensity of the radiologist's gaze, we provide a unified solution that offers insights into the cognitive process underlying radiological interpretation. Unlike current methods that rely on black-box machine learning models, which can be prone to extracting erroneous information from the entire input image during the diagnosis process, we tackle this issue by effectively masking out irrelevant information. Our approach leverages a vision-language model, allowing for precise control over the interpretation process while ensuring the exclusion of irrelevant features. To train our model, we utilize an eye gaze dataset to extract anatomical gaze information and generate ground truth heatmaps. Through extensive experimentation, we demonstrate the efficacy of our method. We showcase that the attention heatmaps, designed to mimic radiologists' focus, encode sufficient and relevant information, enabling accurate classification tasks using only a portion of CXR.