 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNgoc-Bao Nguyen
Model Inversion Robustness: Can Transfer Learning Help?
May 09, 2024
Model Inversion (MI) attacks aim to reconstruct private training data by abusing access to machine learning models. Contemporary MI attacks have achieved impressive attack performance, posing serious threats to privacy. Meanwhile, all existing MI defense methods rely on regularization that is in direct conflict with the training objective, resulting in noticeable degradation in model utility. In this work, we take a different perspective, and propose a novel and simple Transfer Learning-based Defense against Model Inversion (TL-DMI) to render MI-robust models. Particularly, by leveraging TL, we limit the number of layers encoding sensitive information from private training dataset, thereby degrading the performance of MI attack. We conduct an analysis using Fisher Information to justify our method. Our defense is remarkably simple to implement. Without bells and whistles, we show in extensive experiments that TL-DMI achieves state-of-the-art (SOTA) MI robustness. Our code, pre-trained models, demo and inverted data are available at: https://hosytuyen.github.io/projects/TL-DMI
Label-Only Model Inversion Attacks via Knowledge Transfer
Oct 30, 2023In a model inversion (MI) attack, an adversary abuses access to a machine learning (ML) model to infer and reconstruct private training data. Remarkable progress has been made in the white-box and black-box setups, where the adversary has access to the complete model or the model's soft output respectively. However, there is very limited study in the most challenging but practically important setup: Label-only MI attacks, where the adversary only has access to the model's predicted label (hard label) without confidence scores nor any other model information. In this work, we propose LOKT, a novel approach for label-only MI attacks. Our idea is based on transfer of knowledge from the opaque target model to surrogate models. Subsequently, using these surrogate models, our approach can harness advanced white-box attacks. We propose knowledge transfer based on generative modelling, and introduce a new model, Target model-assisted ACGAN (T-ACGAN), for effective knowledge transfer. Our method casts the challenging label-only MI into the more tractable white-box setup. We provide analysis to support that surrogate models based on our approach serve as effective proxies for the target model for MI. Our experiments show that our method significantly outperforms existing SOTA Label-only MI attack by more than 15% across all MI benchmarks. Furthermore, our method compares favorably in terms of query budget. Our study highlights rising privacy threats for ML models even when minimal information (i.e., hard labels) is exposed. Our study highlights rising privacy threats for ML models even when minimal information (i.e., hard labels) is exposed. Our code, demo, models and reconstructed data are available at our project page: https://ngoc-nguyen-0.github.io/lokt/
Re-thinking Model Inversion Attacks Against Deep Neural Networks
Apr 04, 2023



Model inversion (MI) attacks aim to infer and reconstruct private training data by abusing access to a model. MI attacks have raised concerns about the leaking of sensitive information (e.g. private face images used in training a face recognition system). Recently, several algorithms for MI have been proposed to improve the attack performance. In this work, we revisit MI, study two fundamental issues pertaining to all state-of-the-art (SOTA) MI algorithms, and propose solutions to these issues which lead to a significant boost in attack performance for all SOTA MI. In particular, our contributions are two-fold: 1) We analyze the optimization objective of SOTA MI algorithms, argue that the objective is sub-optimal for achieving MI, and propose an improved optimization objective that boosts attack performance significantly. 2) We analyze "MI overfitting", show that it would prevent reconstructed images from learning semantics of training data, and propose a novel "model augmentation" idea to overcome this issue. Our proposed solutions are simple and improve all SOTA MI attack accuracy significantly. E.g., in the standard CelebA benchmark, our solutions improve accuracy by 11.8% and achieve for the first time over 90% attack accuracy. Our findings demonstrate that there is a clear risk of leaking sensitive information from deep learning models. We urge serious consideration to be given to the privacy implications. Our code, demo, and models are available at https://ngoc-nguyen-0.github.io/re-thinking_model_inversion_attacks/
Towards Good Practices for Data Augmentation in GAN Training
Jun 09, 2020



Recent successes in Generative Adversarial Networks (GAN) have affirmed the importance of using more data in GAN training. Yet it is expensive to collect data in many domains such as medical applications. Data Augmentation (DA) has been applied in these applications. In this work, we first argue that the classical DA approach could mislead the generator to learn the distribution of the augmented data, which could be different from that of the original data. We then propose a principled framework, termed Data Augmentation Optimized for GAN (DAG), to enable the use of augmented data in GAN training to improve the learning of the original distribution. We provide theoretical analysis to show that using our proposed DAG aligns with the original GAN in minimizing the JS divergence w.r.t. the original distribution and it leverages the augmented data to improve the learnings of discriminator and generator. The experiments show that DAG improves various GAN models. Furthermore, when DAG is used in some GAN models, the system establishes state-of-the-art Fr\'echet Inception Distance (FID) scores.
Self-supervised GAN: Analysis and Improvement with Multi-class Minimax Game
Nov 16, 2019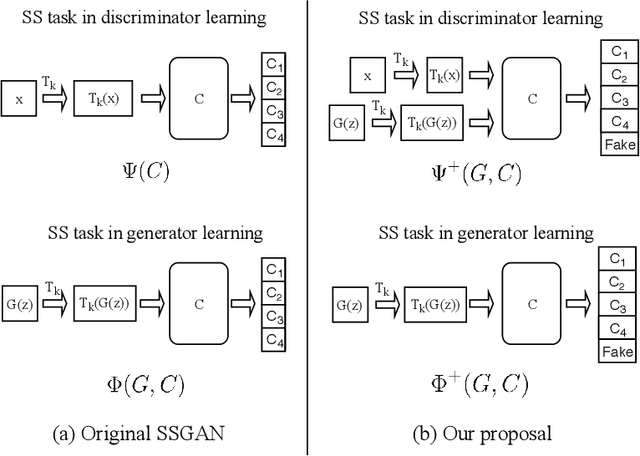
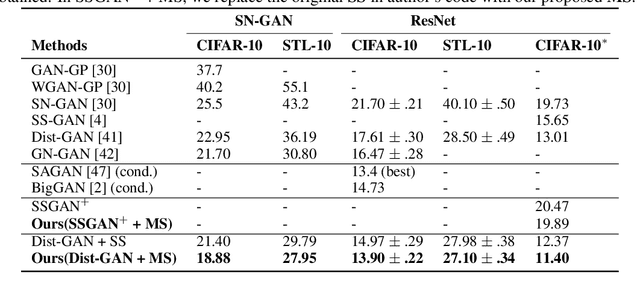


Self-supervised (SS) learning is a powerful approach for representation learning using unlabeled data. Recently, it has been applied to Generative Adversarial Networks (GAN) training. Specifically, SS tasks were proposed to address the catastrophic forgetting issue in the GAN discriminator. In this work, we perform an in-depth analysis to understand how SS tasks interact with learning of generator. From the analysis, we identify issues of SS tasks which allow a severely mode-collapsed generator to excel the SS tasks. To address the issues, we propose new SS tasks based on a multi-class minimax game. The competition between our proposed SS tasks in the game encourages the generator to learn the data distribution and generate diverse samples. We provide both theoretical and empirical analysis to support that our proposed SS tasks have better convergence property. We conduct experiments to incorporate our proposed SS tasks into two different GAN baseline models. Our approach establishes state-of-the-art FID scores on CIFAR-10, CIFAR-100, STL-10, CelebA, Imagenet $32\times32$ and Stacked-MNIST datasets, outperforming existing works by considerable margins in some cases. Our unconditional GAN model approaches performance of conditional GAN without using labeled data. Our code: \url{https://github.com/tntrung/msgan}
An Improved Self-supervised GAN via Adversarial Training
May 14, 2019



We propose to improve unconditional Generative Adversarial Networks (GAN) by training the self-supervised learning with the adversarial process. In particular, we apply self-supervised learning via the geometric transformation on input images and assign the pseudo-labels to these transformed images. (i) In addition to the GAN task, which distinguishes data (real) versus generated (fake) samples, we train the discriminator to predict the correct pseudo-labels of real transformed samples (classification task). Importantly, we find out that simultaneously training the discriminator to classify the fake class from the pseudo-classes of real samples for the classification task will improve the discriminator and subsequently lead better guides to train generator. (ii) The generator is trained by attempting to confuse the discriminator for not only the GAN task but also the classification task. For the classification task, the generator tries to confuse the discriminator recognizing the transformation of its output as one of the real transformed classes. Especially, we exploit that when the generator creates samples that result in a similar loss (via cross-entropy) as that of the real ones, the training is more stable and the generator distribution tends to match better the data distribution. When integrating our techniques into a state-of-the-art Auto-Encoder (AE) based-GAN model, they help to significantly boost the model's performance and also establish new state-of-the-art Fr\'echet Inception Distance (FID) scores in the literature of unconditional GAN for CIFAR-10 and STL-10 datasets.