 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNicholas Mattei
Exploring Social Choice Mechanisms for Recommendation Fairness in SCRUF
Sep 10, 2023
Fairness problems in recommender systems often have a complexity in practice that is not adequately captured in simplified research formulations. A social choice formulation of the fairness problem, operating within a multi-agent architecture of fairness concerns, offers a flexible and multi-aspect alternative to fairness-aware recommendation approaches. Leveraging social choice allows for increased generality and the possibility of tapping into well-studied social choice algorithms for resolving the tension between multiple, competing fairness concerns. This paper explores a range of options for choice mechanisms in multi-aspect fairness applications using both real and synthetic data and shows that different classes of choice and allocation mechanisms yield different but consistent fairness / accuracy tradeoffs. We also show that a multi-agent formulation offers flexibility in adapting to user population dynamics.
Value-based Fast and Slow AI Nudging
Jul 14, 2023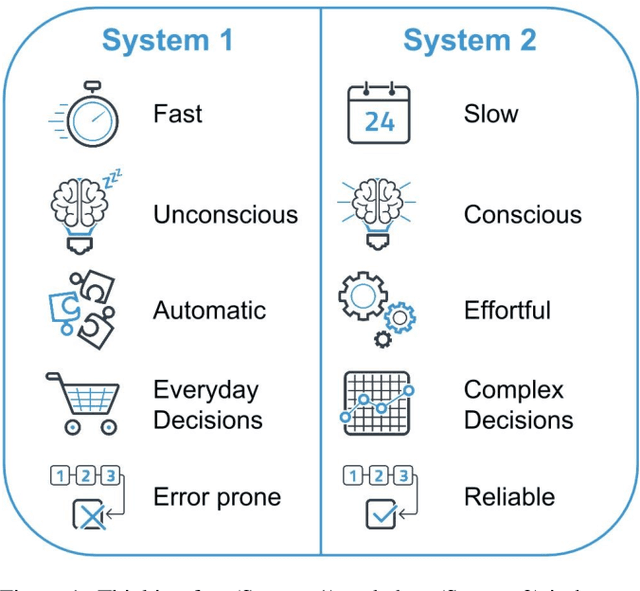
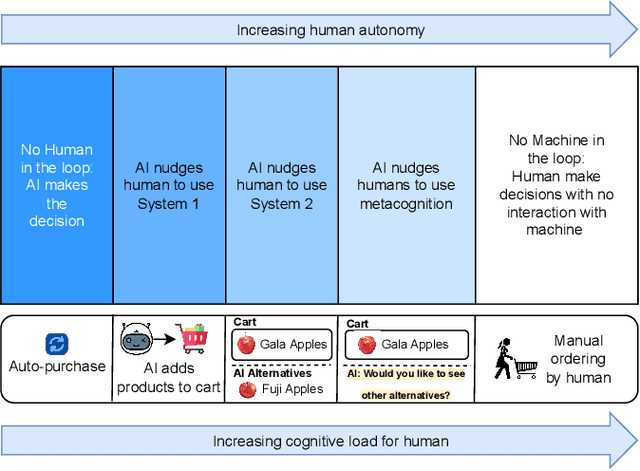
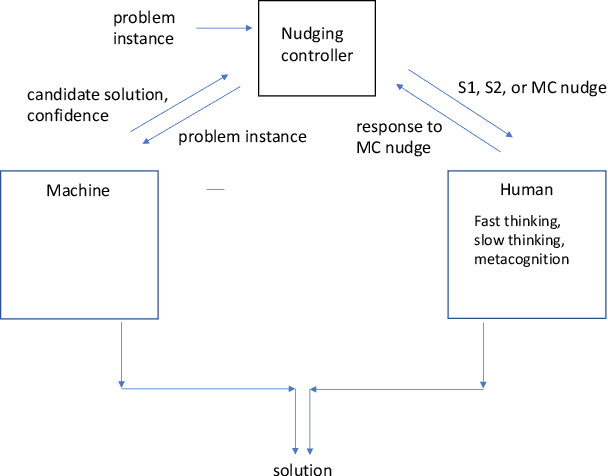
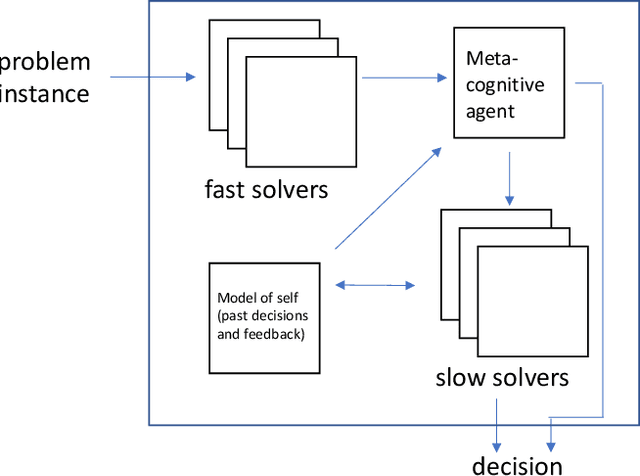
Nudging is a behavioral strategy aimed at influencing people's thoughts and actions. Nudging techniques can be found in many situations in our daily lives, and these nudging techniques can targeted at human fast and unconscious thinking, e.g., by using images to generate fear or the more careful and effortful slow thinking, e.g., by releasing information that makes us reflect on our choices. In this paper, we propose and discuss a value-based AI-human collaborative framework where AI systems nudge humans by proposing decision recommendations. Three different nudging modalities, based on when recommendations are presented to the human, are intended to stimulate human fast thinking, slow thinking, or meta-cognition. Values that are relevant to a specific decision scenario are used to decide when and how to use each of these nudging modalities. Examples of values are decision quality, speed, human upskilling and learning, human agency, and privacy. Several values can be present at the same time, and their priorities can vary over time. The framework treats values as parameters to be instantiated in a specific decision environment.
Dynamic fairness-aware recommendation through multi-agent social choice
Mar 03, 2023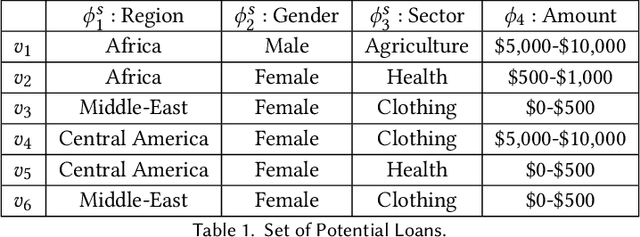
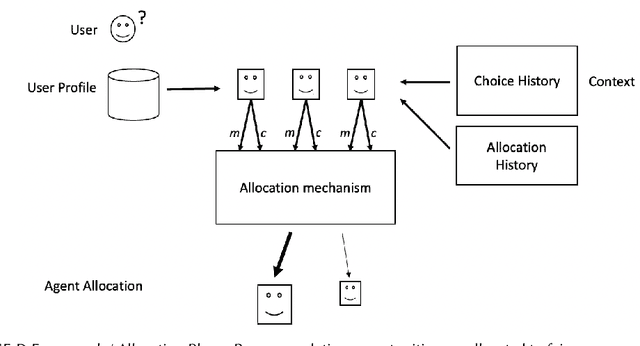
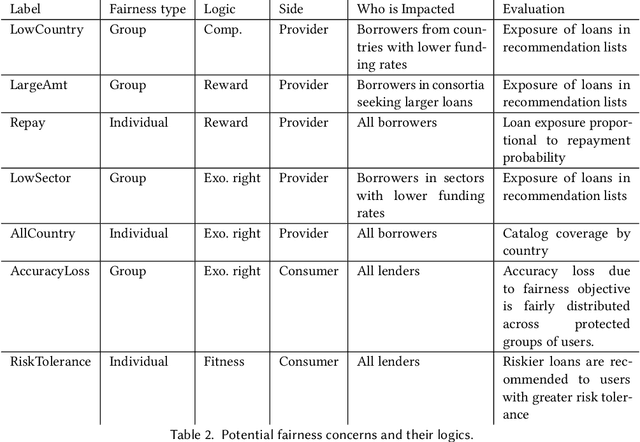
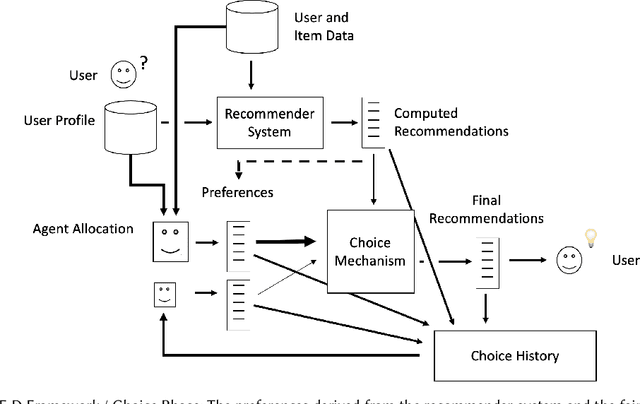
Algorithmic fairness in the context of personalized recommendation presents significantly different challenges to those commonly encountered in classification tasks. Researchers studying classification have generally considered fairness to be a matter of achieving equality of outcomes between a protected and unprotected group, and built algorithmic interventions on this basis. We argue that fairness in real-world application settings in general, and especially in the context of personalized recommendation, is much more complex and multi-faceted, requiring a more general approach. We propose a model to formalize multistakeholder fairness in recommender systems as a two stage social choice problem. In particular, we express recommendation fairness as a novel combination of an allocation and an aggregation problem, which integrate both fairness concerns and personalized recommendation provisions, and derive new recommendation techniques based on this formulation. Simulations demonstrate the ability of the framework to integrate multiple fairness concerns in a dynamic way.
Pandering in a Flexible Representative Democracy
Nov 18, 2022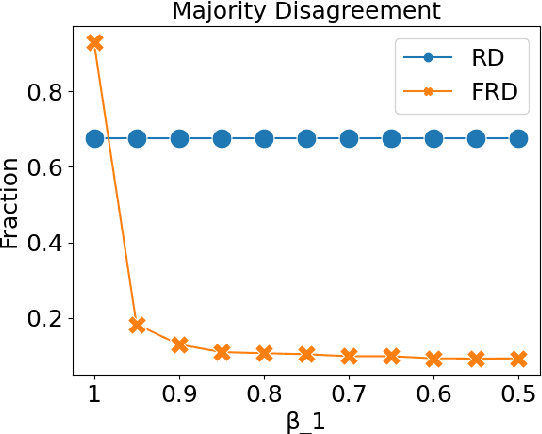

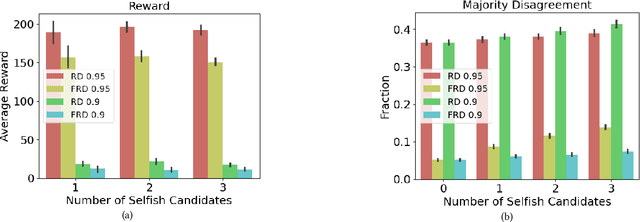
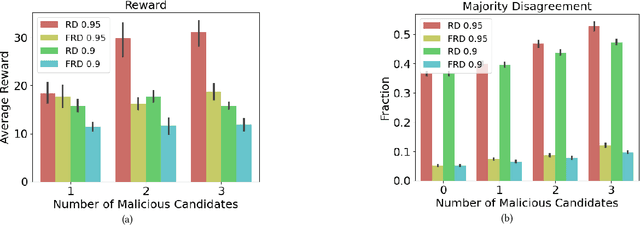
In representative democracies, the election of new representatives in regular election cycles is meant to prevent corruption and other misbehavior by elected officials and to keep them accountable in service of the ``will of the people." This democratic ideal can be undermined when candidates are dishonest when campaigning for election over these multiple cycles or rounds of voting. Much of the work on COMSOC to date has investigated strategic actions in only a single round. We introduce a novel formal model of \emph{pandering}, or strategic preference reporting by candidates seeking to be elected, and examine the resilience of two democratic voting systems to pandering within a single round and across multiple rounds. The two voting systems we compare are Representative Democracy (RD) and Flexible Representative Democracy (FRD). For each voting system, our analysis centers on the types of strategies candidates employ and how voters update their views of candidates based on how the candidates have pandered in the past. We provide theoretical results on the complexity of pandering in our setting for a single cycle, formulate our problem for multiple cycles as a Markov Decision Process, and use reinforcement learning to study the effects of pandering by both single candidates and groups of candidates across a number of rounds.
Social Mechanism Design: A Low-Level Introduction
Nov 15, 2022
How do we deal with the fact that agents have preferences over both decision outcomes and the rules or procedures used to make decisions? If we create rules for aggregating preferences over rules, it would appear that we run into infinite regress with preferences and rules at successively higher "levels." The starting point of our analysis is the claim that infinite regress should not be a problem in practice, as any such preferences will necessarily be bounded in complexity and structured coherently in accordance with some (possibly latent) normative principles. Our core contributions are (1) the identification of simple, intuitive preference structures at low levels that can be generalized to form the building blocks of preferences at higher levels, and (2) the development of algorithms for maximizing the number of agents with such low-level preferences who will "accept" a decision. We analyze algorithms for acceptance maximization in two different domains: asymmetric dichotomous choice and constitutional amendment. In both settings we study the worst-case performance of the appropriate algorithms, and reveal circumstances under which universal acceptance is possible. In particular, we show that constitutional amendment procedures proposed recently by Abramowitz, Shapiro, and Talmon (2021) can achieve universal acceptance.
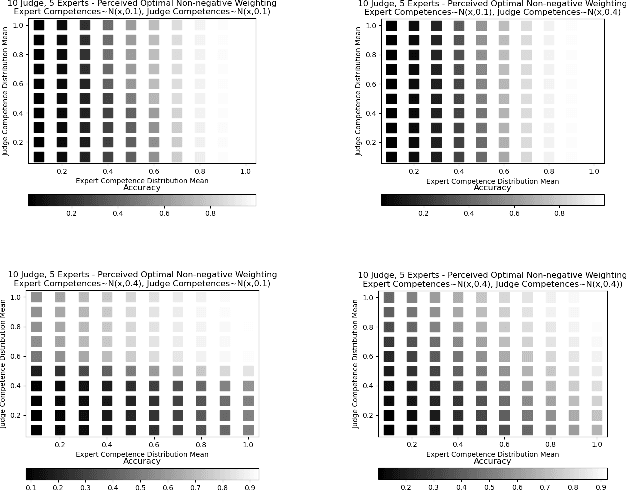
Weighting Experts with Inaccurate Judges
Nov 15, 2022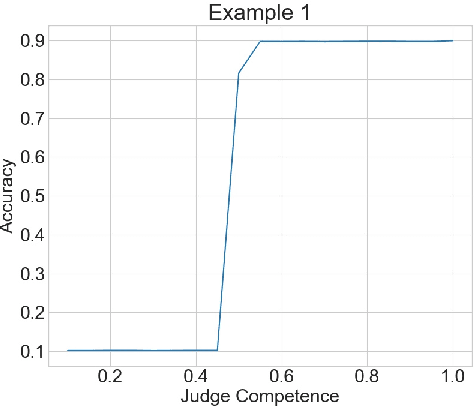
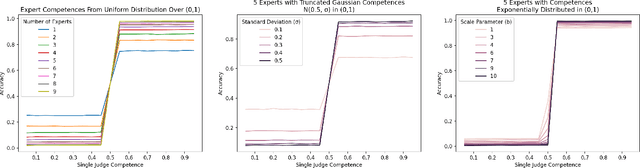

We consider the problem of aggregating binary votes from an ensemble of experts to reveal an underlying binary ground truth where each expert votes correctly with some independent probability. We focus on settings where the number of agents is too small for asymptotic results to apply, many experts may vote correctly with low probability, and there is no central authority who knows the experts' competences, or their probabilities of voting correctly. Our approach is to designate a second type of agent -- a judge -- to weight the experts to improve overall accuracy. The catch is that the judge has imperfect competence just like the experts. We demonstrate that having a single minimally competent judge is often better than having none at all. Using an ensemble of judges to weight the experts can provide a better weighting than any single judge; even the optimal weighting under the right conditions. As our results show, the ability of the judge(s) to distinguish between competent and incompetent experts is paramount. Lastly, given a fixed set of agents with unknown competences drawn i.i.d. from a common distribution, we show how the optimal split of the agents between judges and experts depends on the distribution.
Who Pays? Personalization, Bossiness and the Cost of Fairness
Sep 08, 2022Fairness-aware recommender systems that have a provider-side fairness concern seek to ensure that protected group(s) of providers have a fair opportunity to promote their items or products. There is a ``cost of fairness'' borne by the consumer side of the interaction when such a solution is implemented. This consumer-side cost raises its own questions of fairness, particularly when personalization is used to control the impact of the fairness constraint. In adopting a personalized approach to the fairness objective, researchers may be opening their systems up to strategic behavior on the part of users. This type of incentive has been studied in the computational social choice literature under the terminology of ``bossiness''. The concern is that a bossy user may be able to shift the cost of fairness to others, improving their own outcomes and worsening those for others. This position paper introduces the concept of bossiness, shows its application in fairness-aware recommendation and discusses strategies for reducing this strategic incentive.
Towards Group Learning: Distributed Weighting of Experts
Jun 03, 2022
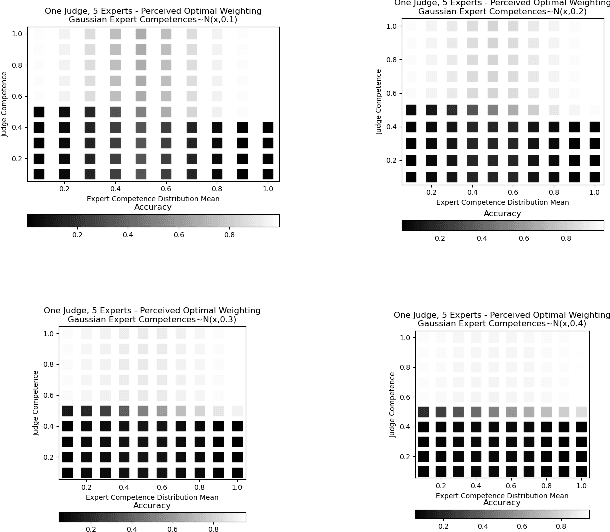
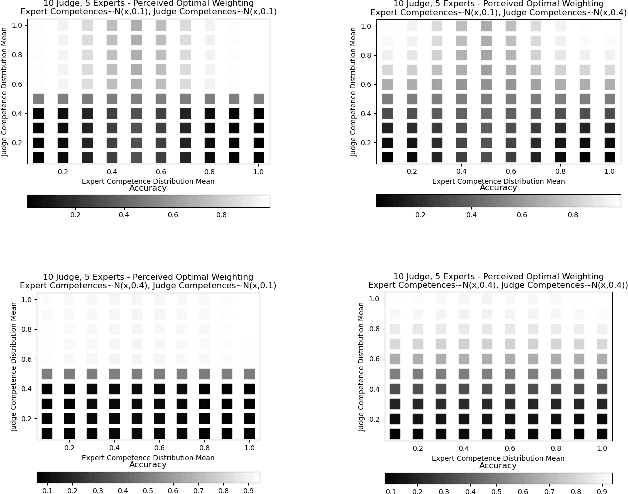
Aggregating signals from a collection of noisy sources is a fundamental problem in many domains including crowd-sourcing, multi-agent planning, sensor networks, signal processing, voting, ensemble learning, and federated learning. The core question is how to aggregate signals from multiple sources (e.g. experts) in order to reveal an underlying ground truth. While a full answer depends on the type of signal, correlation of signals, and desired output, a problem common to all of these applications is that of differentiating sources based on their quality and weighting them accordingly. It is often assumed that this differentiation and aggregation is done by a single, accurate central mechanism or agent (e.g. judge). We complicate this model in two ways. First, we investigate the setting with both a single judge, and one with multiple judges. Second, given this multi-agent interaction of judges, we investigate various constraints on the judges' reporting space. We build on known results for the optimal weighting of experts and prove that an ensemble of sub-optimal mechanisms can perform optimally under certain conditions. We then show empirically that the ensemble approximates the performance of the optimal mechanism under a broader range of conditions.
Learning Behavioral Soft Constraints from Demonstrations
Feb 21, 2022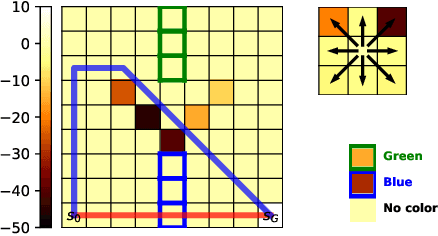
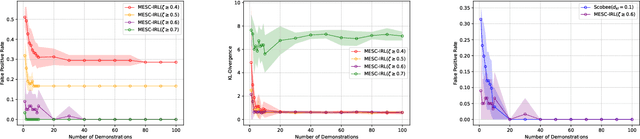
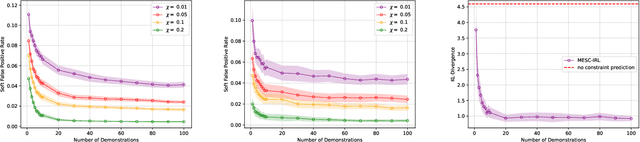

Many real-life scenarios require humans to make difficult trade-offs: do we always follow all the traffic rules or do we violate the speed limit in an emergency? These scenarios force us to evaluate the trade-off between collective rules and norms with our own personal objectives and desires. To create effective AI-human teams, we must equip AI agents with a model of how humans make these trade-offs in complex environments when there are implicit and explicit rules and constraints. Agent equipped with these models will be able to mirror human behavior and/or to draw human attention to situations where decision making could be improved. To this end, we propose a novel inverse reinforcement learning (IRL) method: Max Entropy Inverse Soft Constraint IRL (MESC-IRL), for learning implicit hard and soft constraints over states, actions, and state features from demonstrations in deterministic and non-deterministic environments modeled as Markov Decision Processes (MDPs). Our method enables agents implicitly learn human constraints and desires without the need for explicit modeling by the agent designer and to transfer these constraints between environments. Our novel method generalizes prior work which only considered deterministic hard constraints and achieves state of the art performance.
When Is It Acceptable to Break the Rules? Knowledge Representation of Moral Judgement Based on Empirical Data
Jan 19, 2022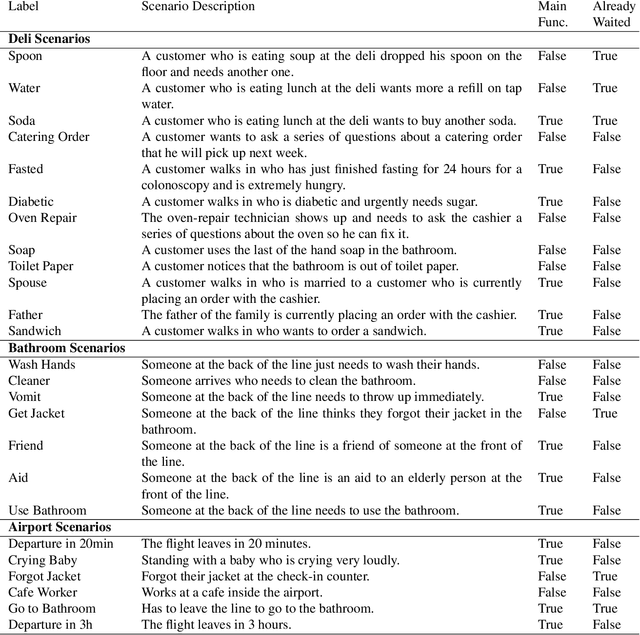
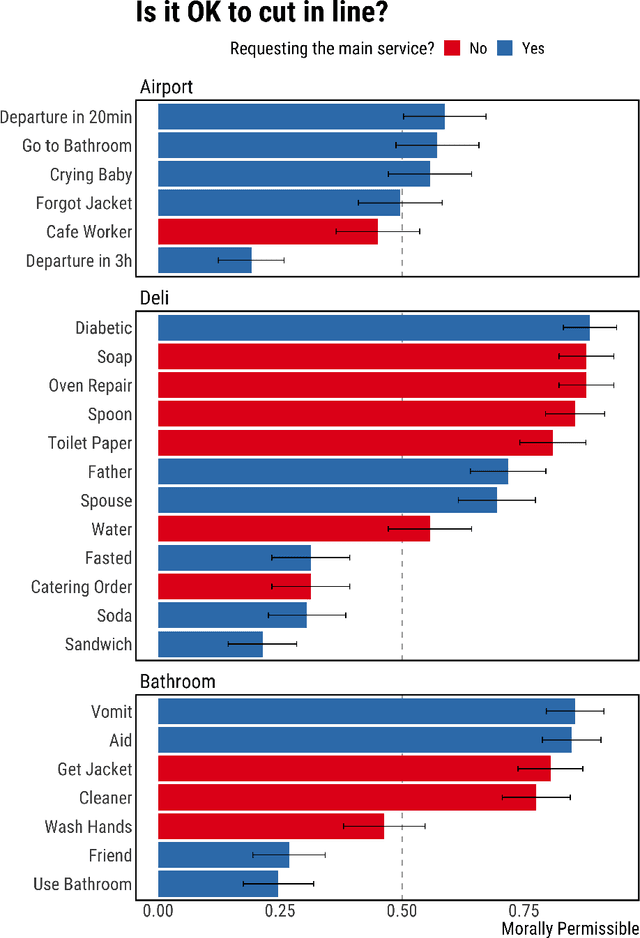

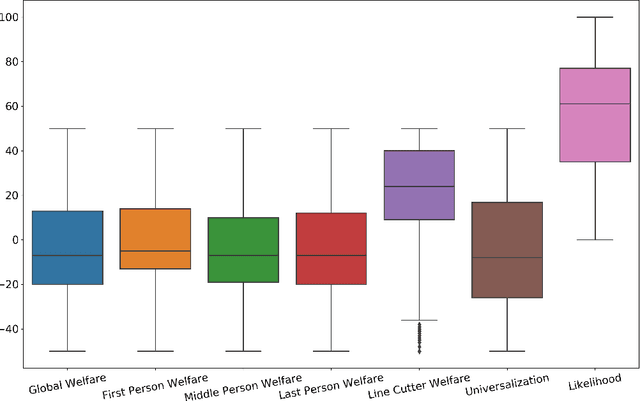
One of the most remarkable things about the human moral mind is its flexibility. We can make moral judgments about cases we have never seen before. We can decide that pre-established rules should be broken. We can invent novel rules on the fly. Capturing this flexibility is one of the central challenges in developing AI systems that can interpret and produce human-like moral judgment. This paper details the results of a study of real-world decision makers who judge whether it is acceptable to break a well-established norm: ``no cutting in line.'' We gather data on how human participants judge the acceptability of line-cutting in a range of scenarios. Then, in order to effectively embed these reasoning capabilities into a machine, we propose a method for modeling them using a preference-based structure, which captures a novel modification to standard ``dual process'' theories of moral judgment.