 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNico Messikommer
Contrastive Initial State Buffer for Reinforcement Learning
Sep 20, 2023
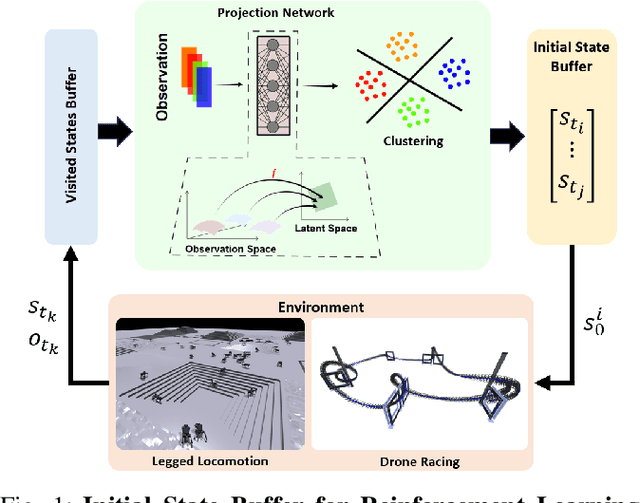
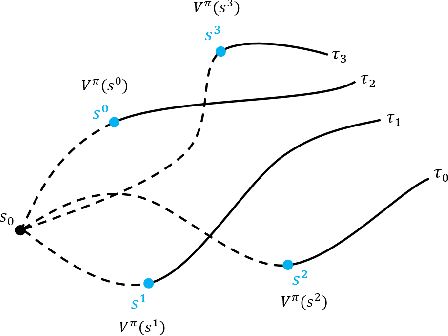
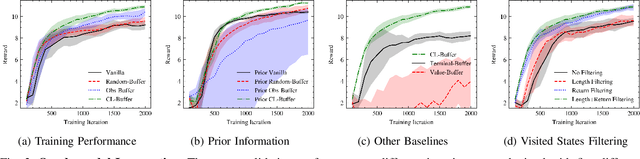

In Reinforcement Learning, the trade-off between exploration and exploitation poses a complex challenge for achieving efficient learning from limited samples. While recent works have been effective in leveraging past experiences for policy updates, they often overlook the potential of reusing past experiences for data collection. Independent of the underlying RL algorithm, we introduce the concept of a Contrastive Initial State Buffer, which strategically selects states from past experiences and uses them to initialize the agent in the environment in order to guide it toward more informative states. We validate our approach on two complex robotic tasks without relying on any prior information about the environment: (i) locomotion of a quadruped robot traversing challenging terrains and (ii) a quadcopter drone racing through a track. The experimental results show that our initial state buffer achieves higher task performance than the nominal baseline while also speeding up training convergence.
Seeing Behind Dynamic Occlusions with Event Cameras
Aug 01, 2023
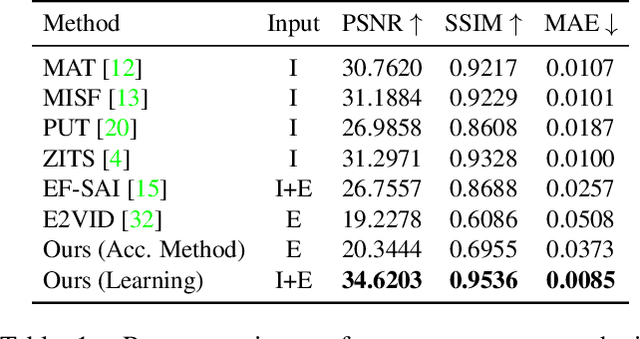
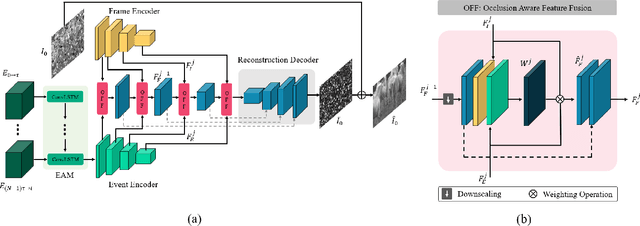
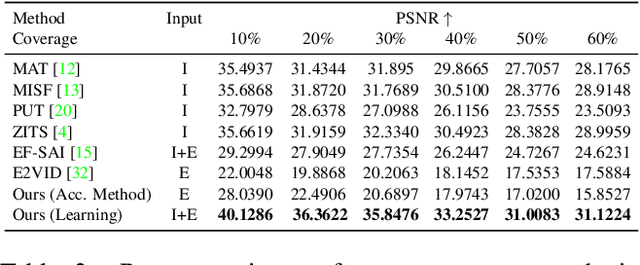
Unwanted camera occlusions, such as debris, dust, rain-drops, and snow, can severely degrade the performance of computer-vision systems. Dynamic occlusions are particularly challenging because of the continuously changing pattern. Existing occlusion-removal methods currently use synthetic aperture imaging or image inpainting. However, they face issues with dynamic occlusions as these require multiple viewpoints or user-generated masks to hallucinate the background intensity. We propose a novel approach to reconstruct the background from a single viewpoint in the presence of dynamic occlusions. Our solution relies for the first time on the combination of a traditional camera with an event camera. When an occlusion moves across a background image, it causes intensity changes that trigger events. These events provide additional information on the relative intensity changes between foreground and background at a high temporal resolution, enabling a truer reconstruction of the background content. We present the first large-scale dataset consisting of synchronized images and event sequences to evaluate our approach. We show that our method outperforms image inpainting methods by 3dB in terms of PSNR on our dataset.
Revisiting Token Pruning for Object Detection and Instance Segmentation
Jun 12, 2023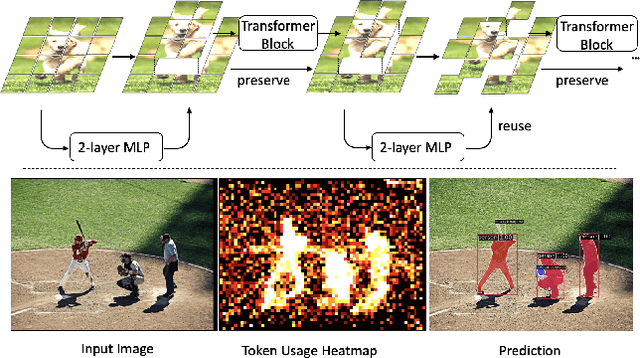
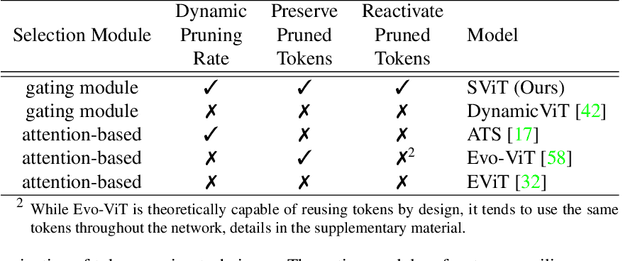
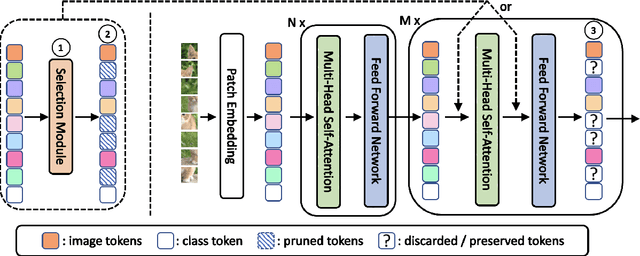
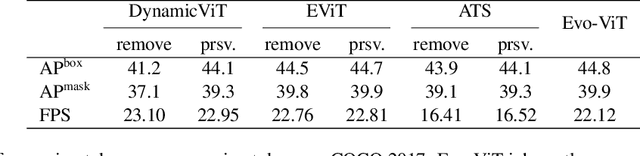
Vision Transformers (ViTs) have shown impressive performance in computer vision, but their high computational cost, quadratic in the number of tokens, limits their adoption in computation-constrained applications. However, this large number of tokens may not be necessary, as not all tokens are equally important. In this paper, we investigate token pruning to accelerate inference for object detection and instance segmentation, extending prior works from image classification. Through extensive experiments, we offer four insights for dense tasks: (i) tokens should not be completely pruned and discarded, but rather preserved in the feature maps for later use. (ii) reactivating previously pruned tokens can further enhance model performance. (iii) a dynamic pruning rate based on images is better than a fixed pruning rate. (iv) a lightweight, 2-layer MLP can effectively prune tokens, achieving accuracy comparable with complex gating networks with a simpler design. We evaluate the impact of these design choices on COCO dataset and present a method integrating these insights that outperforms prior art token pruning models, significantly reducing performance drop from ~1.5 mAP to ~0.3 mAP for both boxes and masks. Compared to the dense counterpart that uses all tokens, our method achieves up to 34% faster inference speed for the whole network and 46% for the backbone.
Data-driven Feature Tracking for Event Cameras
Nov 23, 2022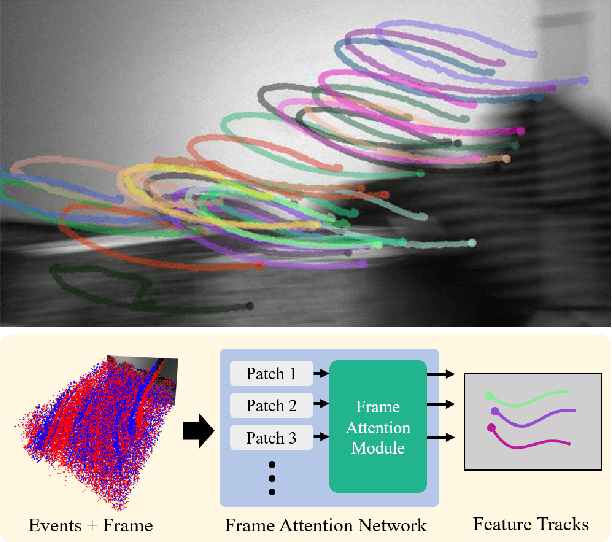

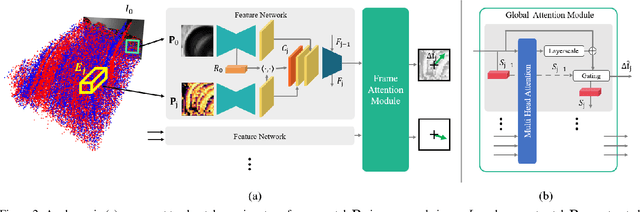
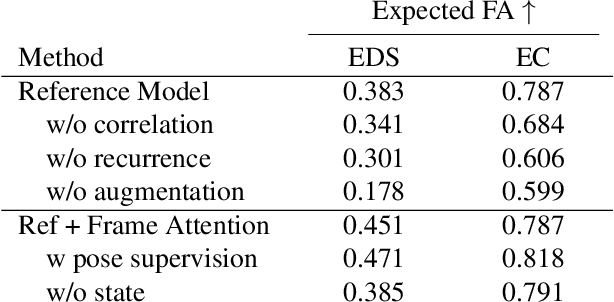
Because of their high temporal resolution, increased resilience to motion blur, and very sparse output, event cameras have been shown to be ideal for low-latency and low-bandwidth feature tracking, even in challenging scenarios. Existing feature tracking methods for event cameras are either handcrafted or derived from first principles but require extensive parameter tuning, are sensitive to noise, and do not generalize to different scenarios due to unmodeled effects. To tackle these deficiencies, we introduce the first data-driven feature tracker for event cameras, which leverages low-latency events to track features detected in a grayscale frame. We achieve robust performance via a novel frame attention module, which shares information across feature tracks. By directly transferring zero-shot from synthetic to real data, our data-driven tracker outperforms existing approaches in relative feature age by up to 120 % while also achieving the lowest latency. This performance gap is further increased to 130 % by adapting our tracker to real data with a novel self-supervision strategy.
ESS: Learning Event-based Semantic Segmentation from Still Images
Mar 18, 2022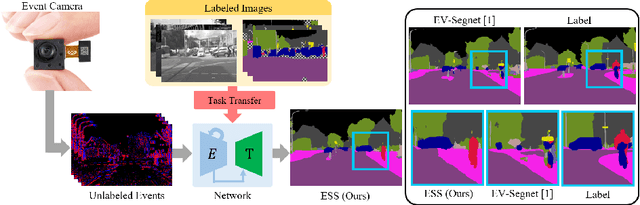

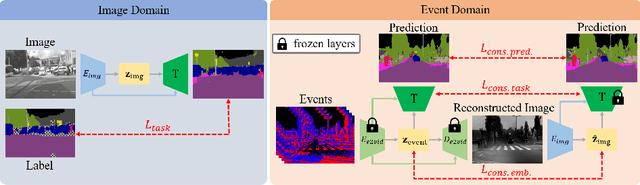
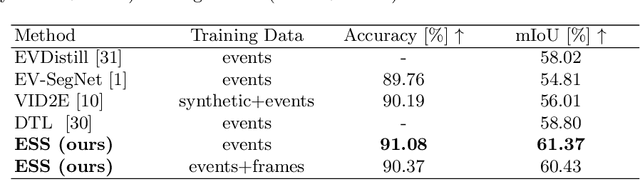
Retrieving accurate semantic information in challenging high dynamic range (HDR) and high-speed conditions remains an open challenge for image-based algorithms due to severe image degradations. Event cameras promise to address these challenges since they feature a much higher dynamic range and are resilient to motion blur. Nonetheless, semantic segmentation with event cameras is still in its infancy which is chiefly due to the novelty of the sensor, and the lack of high-quality, labeled datasets. In this work, we introduce ESS, which tackles this problem by directly transferring the semantic segmentation task from existing labeled image datasets to unlabeled events via unsupervised domain adaptation (UDA). Compared to existing UDA methods, our approach aligns recurrent, motion-invariant event embeddings with image embeddings. For this reason, our method neither requires video data nor per-pixel alignment between images and events and, crucially, does not need to hallucinate motion from still images. Additionally, to spur further research in event-based semantic segmentation, we introduce DSEC-Semantic, the first large-scale event-based dataset with fine-grained labels. We show that using image labels alone, ESS outperforms existing UDA approaches, and when combined with event labels, it even outperforms state-of-the-art supervised approaches on both DDD17 and DSEC-Semantic. Finally, ESS is general-purpose, which unlocks the vast amount of existing labeled image datasets and paves the way for new and exciting research directions in new fields previously inaccessible for event cameras.
Multi-Bracket High Dynamic Range Imaging with Event Cameras
Mar 13, 2022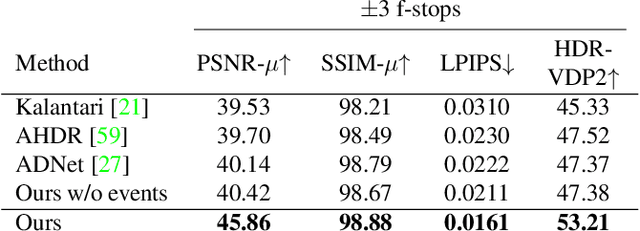
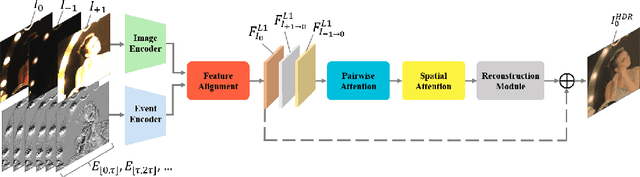
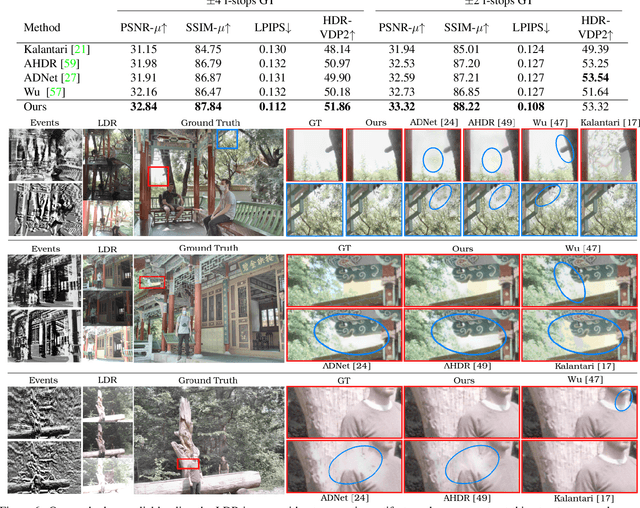
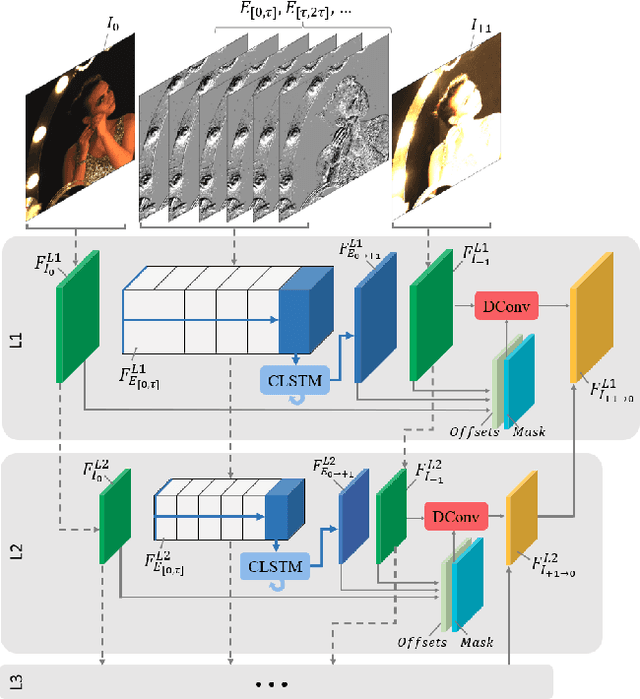
Modern high dynamic range (HDR) imaging pipelines align and fuse multiple low dynamic range (LDR) images captured at different exposure times. While these methods work well in static scenes, dynamic scenes remain a challenge since the LDR images still suffer from saturation and noise. In such scenarios, event cameras would be a valid complement, thanks to their higher temporal resolution and dynamic range. In this paper, we propose the first multi-bracket HDR pipeline combining a standard camera with an event camera. Our results show better overall robustness when using events, with improvements in PSNR by up to 5dB on synthetic data and up to 0.7dB on real-world data. We also introduce a new dataset containing bracketed LDR images with aligned events and HDR ground truth.
Bridging the Gap between Events and Frames through Unsupervised Domain Adaptation
Sep 06, 2021
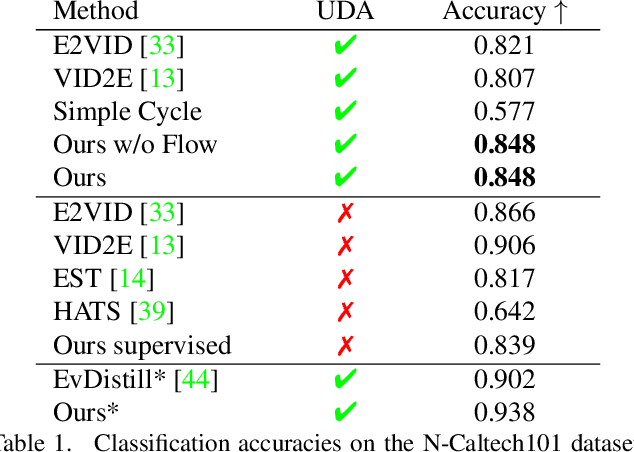
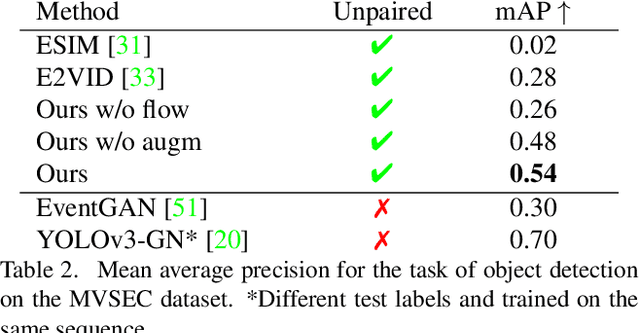
Event cameras are novel sensors with outstanding properties such as high temporal resolution and high dynamic range. Despite these characteristics, event-based vision has been held back by the shortage of labeled datasets due to the novelty of event cameras. To overcome this drawback, we propose a task transfer method that allows models to be trained directly with labeled images and unlabeled event data. Compared to previous approaches, (i) our method transfers from single images to events instead of high frame rate videos, and (ii) does not rely on paired sensor data. To achieve this, we leverage the generative event model to split event features into content and motion features. This feature split enables to efficiently match the latent space for events and images, which is crucial for a successful task transfer. Thus, our approach unlocks the vast amount of existing image datasets for the training of event-based neural networks. Our task transfer method consistently outperforms methods applicable in the Unsupervised Domain Adaptation setting for object detection by 0.26 mAP (increase by 93%) and classification by 2.7% accuracy.
Event-based Asynchronous Sparse Convolutional Networks
Mar 20, 2020

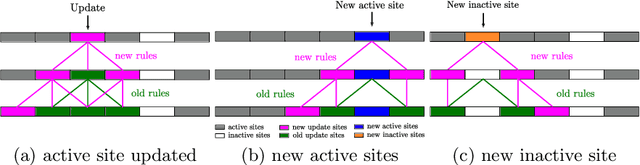

Event cameras are bio-inspired sensors that respond to per-pixel brightness changes in the form of asynchronous and sparse "events". Recently, pattern recognition algorithms, such as learning-based methods, have made significant progress with event cameras by converting events into synchronous dense, image-like representations and applying traditional machine learning methods developed for standard cameras. However, these approaches discard the spatial and temporal sparsity inherent in event data at the cost of higher computational complexity and latency. In this work, we present a general framework for converting models trained on synchronous image-like event representations into asynchronous models with identical output, thus directly leveraging the intrinsic asynchronous and sparse nature of the event data. We show both theoretically and experimentally that this drastically reduces the computational complexity and latency of high-capacity, synchronous neural networks without sacrificing accuracy. In addition, our framework has several desirable characteristics: (i) it exploits spatio-temporal sparsity of events explicitly, (ii) it is agnostic to the event representation, network architecture, and task, and (iii) it does not require any train-time change, since it is compatible with the standard neural networks' training process. We thoroughly validate the proposed framework on two computer vision tasks: object detection and object recognition. In these tasks, we reduce the computational complexity up to 20 times with respect to high-latency neural networks. At the same time, we outperform state-of-the-art asynchronous approaches up to 24% in prediction accuracy.
Cone Detection using a Combination of LiDAR and Vision-based Machine Learning
Nov 06, 2017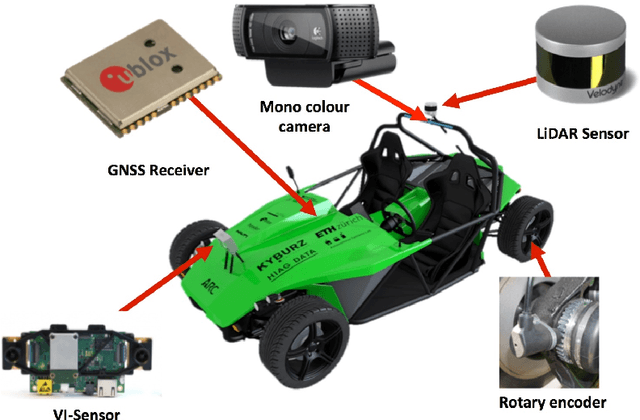
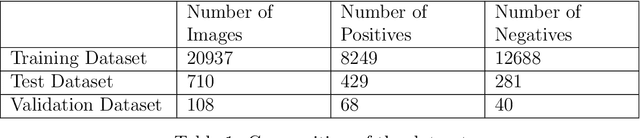

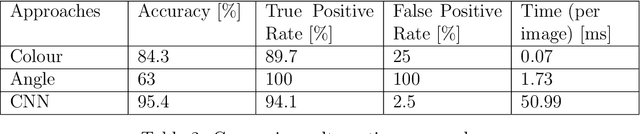
The classification and the position estimation of objects become more and more relevant as the field of robotics is expanding in diverse areas of society. In this Bachelor Thesis, we developed a cone detection algorithm for an autonomous car using a LiDAR sensor and a colour camera. By evaluating simple constraints, the LiDAR detection algorithm preselects cone candidates in the 3 dimensional space. The candidates are projected into the image plane of the colour camera and an image candidate is cropped out. A convolutional neural networks classifies the image candidates as cone or not a cone. With the fusion of the precise position estimation of the LiDAR sensor and the high classification accuracy of a neural network, a reliable cone detection algorithm was implemented. Furthermore, a path planning algorithm generates a path around the detected cones. The final system detects cones even at higher velocity and has the potential to drive fully autonomous around the cones.
Autonomous Electric Race Car Design
Nov 01, 2017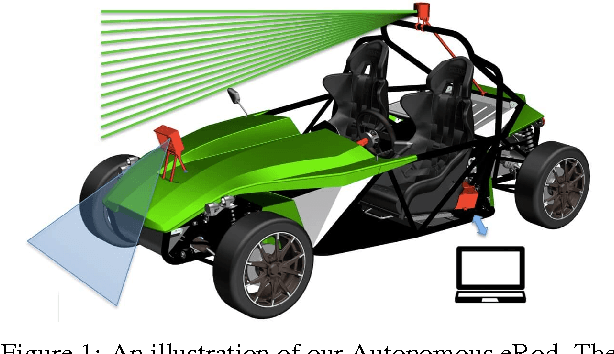
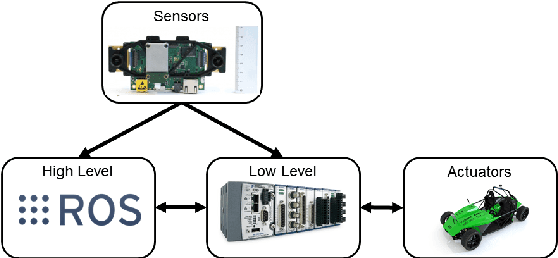
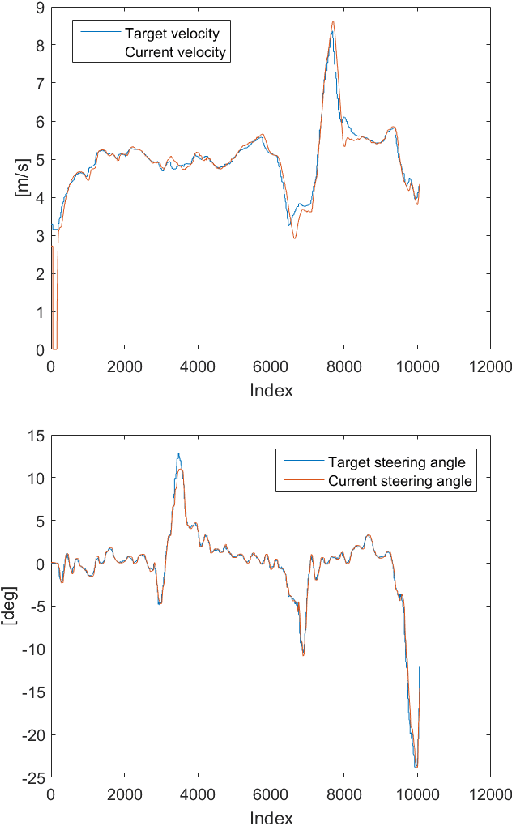
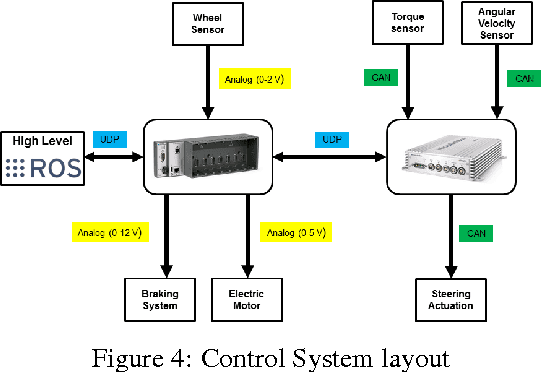
Autonomous driving and electric vehicles are nowadays very active research and development areas. In this paper we present the conversion of a standard Kyburz eRod into an autonomous vehicle that can be operated in challenging environments such as Swiss mountain passes. The overall hardware and software architectures are described in detail with a special emphasis on the sensor requirements for autonomous vehicles operating in partially structured environments. Furthermore, the design process itself and the finalized system architecture are presented. The work shows state of the art results in localization and controls for self-driving high-performance electric vehicles. Test results of the overall system are presented, which show the importance of generalizable state estimation algorithms to handle a plethora of conditions.