 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNihat Ay
On the Fisher-Rao Gradient of the Evidence Lower Bound
Jul 20, 2023
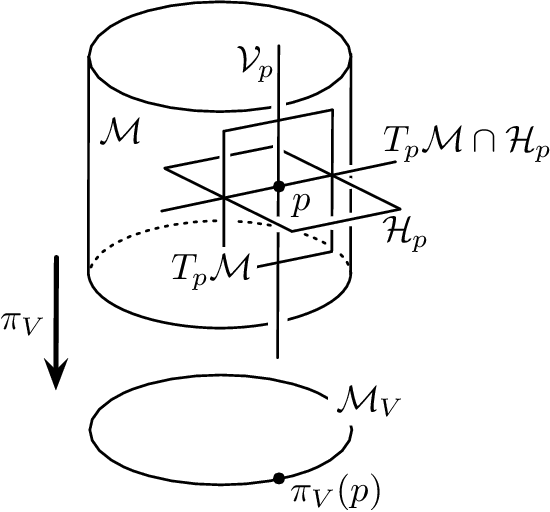
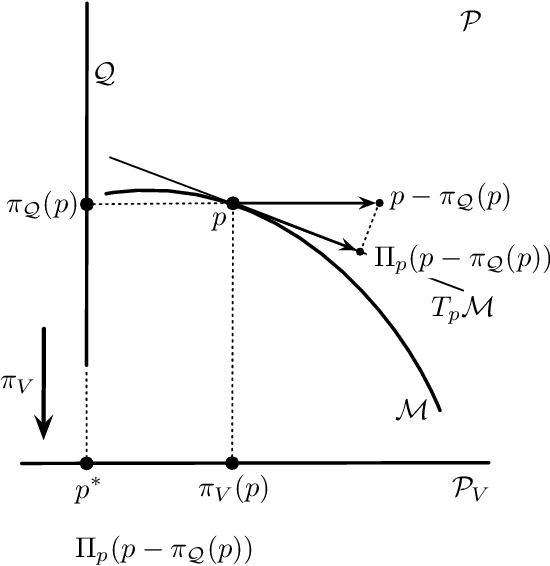
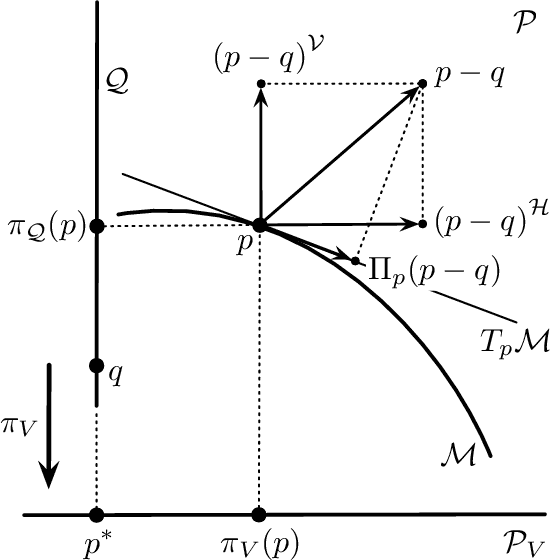
This article studies the Fisher-Rao gradient, also referred to as the natural gradient, of the evidence lower bound, the ELBO, which plays a crucial role within the theory of the Variational Autonecoder, the Helmholtz Machine and the Free Energy Principle. The natural gradient of the ELBO is related to the natural gradient of the Kullback-Leibler divergence from a target distribution, the prime objective function of learning. Based on invariance properties of gradients within information geometry, conditions on the underlying model are provided that ensure the equivalence of minimising the prime objective function and the maximisation of the ELBO.
Inversion of Bayesian Networks
Dec 20, 2022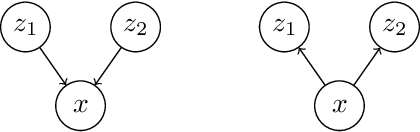
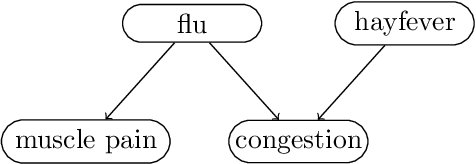
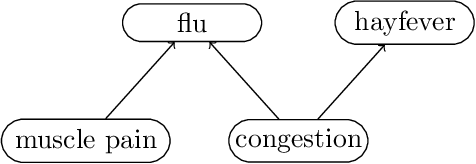
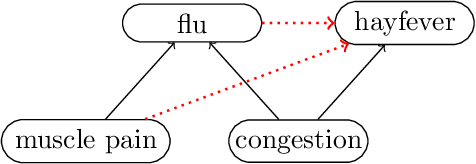
Variational autoencoders and Helmholtz machines use a recognition network (encoder) to approximate the posterior distribution of a generative model (decoder). In this paper we study the necessary and sufficient properties of a recognition network so that it can model the true posterior distribution exactly. These results are derived in the general context of probabilistic graphical modelling / Bayesian networks, for which the network represents a set of conditional independence statements. We derive both global conditions, in terms of d-separation, and local conditions for the recognition network to have the desired qualities. It turns out that for the local conditions the property perfectness (for every node, all parents are joined) plays an important role.
Invariance Properties of the Natural Gradient in Overparametrised Systems
Jun 30, 2022The natural gradient field is a vector field that lives on a model equipped with a distinguished Riemannian metric, e.g. the Fisher-Rao metric, and represents the direction of steepest ascent of an objective function on the model with respect to this metric. In practice, one tries to obtain the corresponding direction on the parameter space by multiplying the ordinary gradient by the inverse of the Gram matrix associated with the metric. We refer to this vector on the parameter space as the natural parameter gradient. In this paper we study when the pushforward of the natural parameter gradient is equal to the natural gradient. Furthermore we investigate the invariance properties of the natural parameter gradient. Both questions are addressed in an overparametrised setting.
Natural Wake-Sleep Algorithm
Aug 15, 2020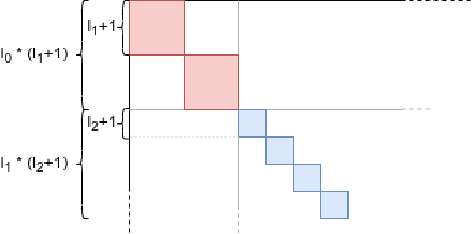


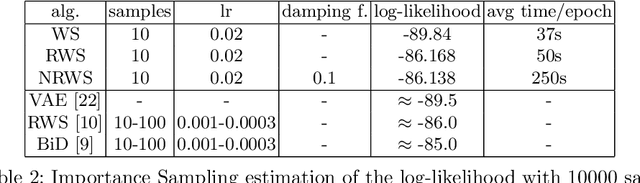
The benefits of using the natural gradient are well known in a wide range of optimization problems. However, for the training of common neural networks the resulting increase in computational complexity sets a limitation to its practical application. Helmholtz Machines are a particular type of generative model composed of two Sigmoid Belief Networks (SBNs), acting as an encoder and a decoder, commonly trained using the Wake-Sleep (WS) algorithm and its reweighted version RWS. For SBNs, it has been shown how the locality of the connections in the graphical structure induces sparsity in the Fisher information matrix. The resulting block diagonal structure can be efficiently exploited to reduce the computational complexity of the Fisher matrix inversion and thus compute the natural gradient exactly, without the need of approximations. We present a geometric adaptation of well-known methods from the literature, introducing the Natural Wake-Sleep (NWS) and the Natural Reweighted Wake-Sleep (NRWS) algorithms. We present an experimental analysis of the novel geometrical algorithms based on the convergence speed and the value of the log-likelihood, both with respect to the number of iterations and the time complexity and demonstrating improvements on these aspects over their respective non-geometric baselines.
On the Locality of the Natural Gradient for Deep Learning
May 21, 2020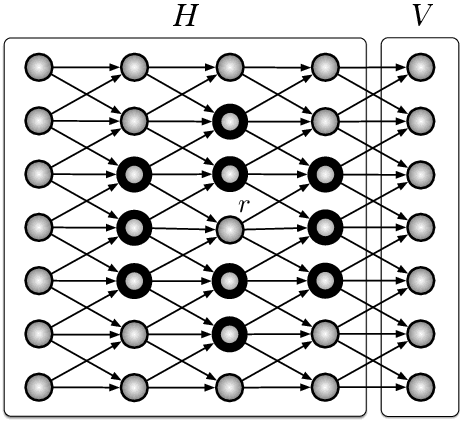
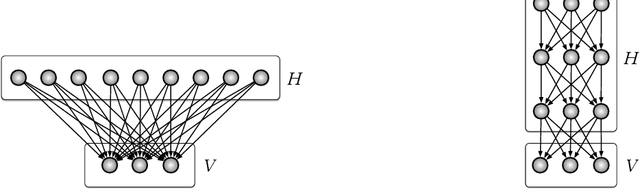
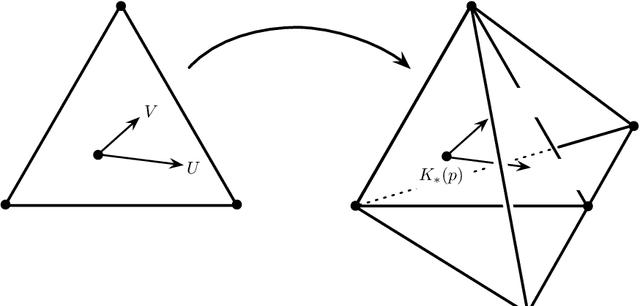
We study the natural gradient method for learning in deep Bayesian networks, including neural networks. There are two natural geometries associated with such learning systems consisting of visible and hidden units. One geometry is related to the full system, the other one to the visible sub-system. These two geometries imply different natural gradients. In a first step, we demonstrate a great simplification of the natural gradient with respect to the first geometry, due to locality properties of the Fisher information matrix. This simplification does not directly translate to a corresponding simplification with respect to the second geometry. We develop the theory for studying the relation between the two versions of the natural gradient and outline a method for the simplification of the natural gradient with respect to the second geometry based on the first one. This method suggests to incorporate a recognition model as an auxiliary model for the efficient application of the natural gradient method in deep networks.
Comparing Information-Theoretic Measures of Complexity in Boltzmann Machines
Jul 30, 2017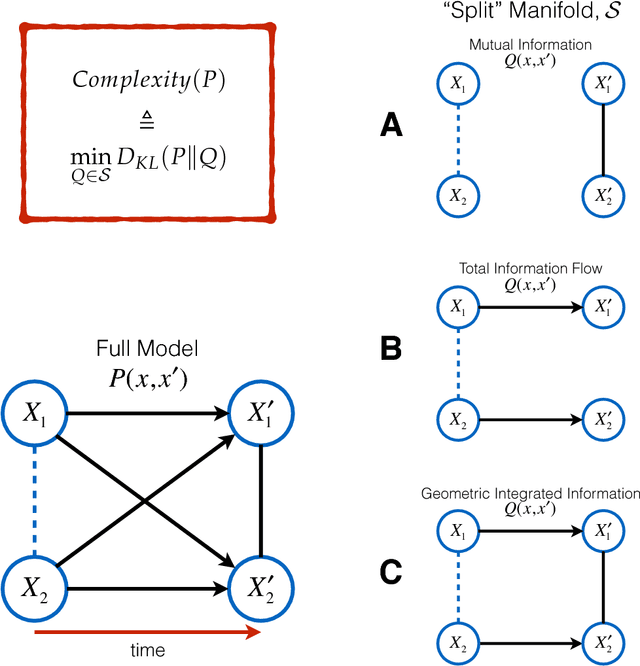
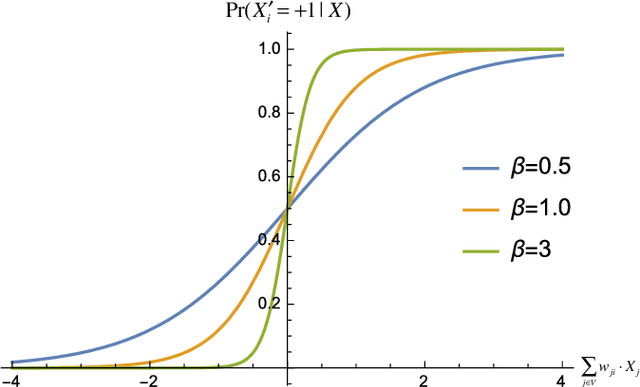
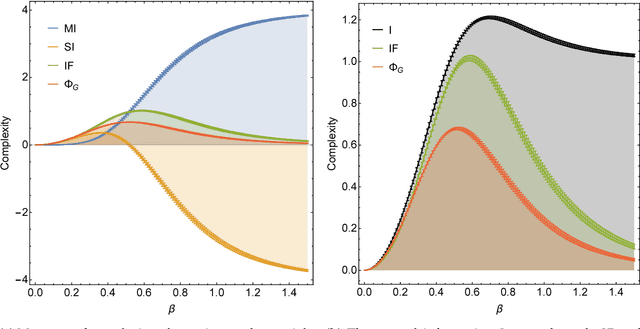
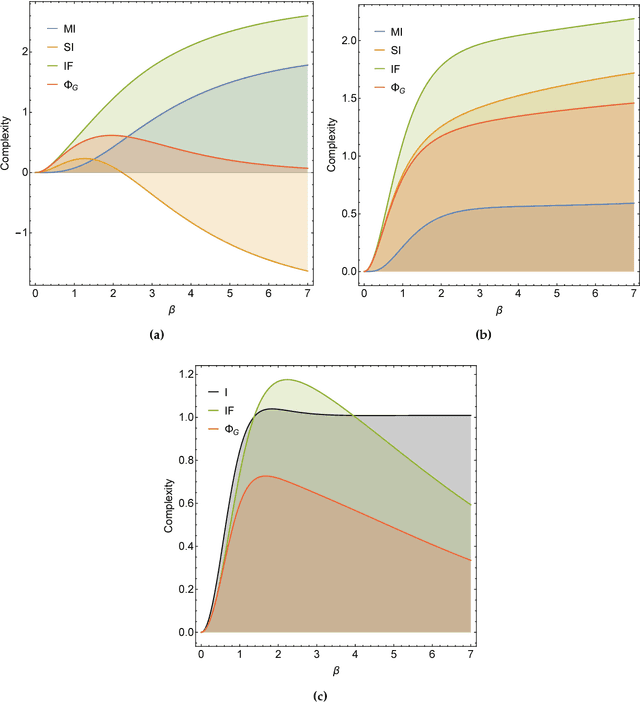
In the past three decades, many theoretical measures of complexity have been proposed to help understand complex systems. In this work, for the first time, we place these measures on a level playing field, to explore the qualitative similarities and differences between them, and their shortcomings. Specifically, using the Boltzmann machine architecture (a fully connected recurrent neural network) with uniformly distributed weights as our model of study, we numerically measure how complexity changes as a function of network dynamics and network parameters. We apply an extension of one such information-theoretic measure of complexity to understand incremental Hebbian learning in Hopfield networks, a fully recurrent architecture model of autoassociative memory. In the course of Hebbian learning, the total information flow reflects a natural upward trend in complexity as the network attempts to learn more and more patterns.
* 16 pages, 7 figures; Appears in Entropy, Special Issue "Information Geometry II"
Information Theoretically Aided Reinforcement Learning for Embodied Agents
May 31, 2016
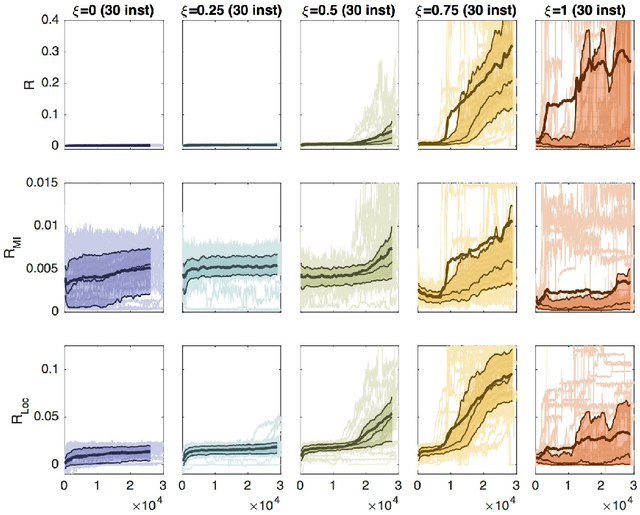
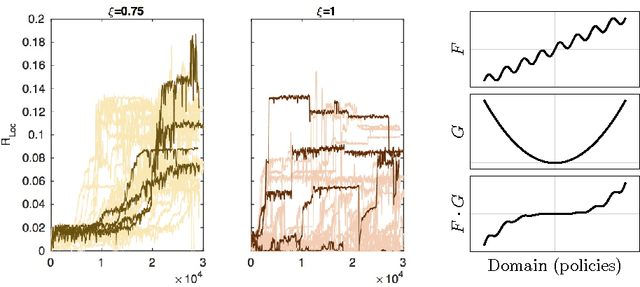
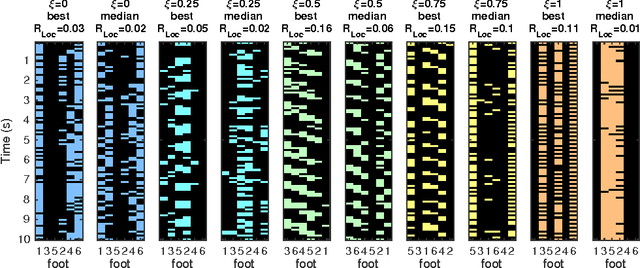
Reinforcement learning for embodied agents is a challenging problem. The accumulated reward to be optimized is often a very rugged function, and gradient methods are impaired by many local optimizers. We demonstrate, in an experimental setting, that incorporating an intrinsic reward can smoothen the optimization landscape while preserving the global optimizers of interest. We show that policy gradient optimization for locomotion in a complex morphology is significantly improved when supplementing the extrinsic reward by an intrinsic reward defined in terms of the mutual information of time consecutive sensor readings.
Geometry and Determinism of Optimal Stationary Control in Partially Observable Markov Decision Processes
Feb 13, 2016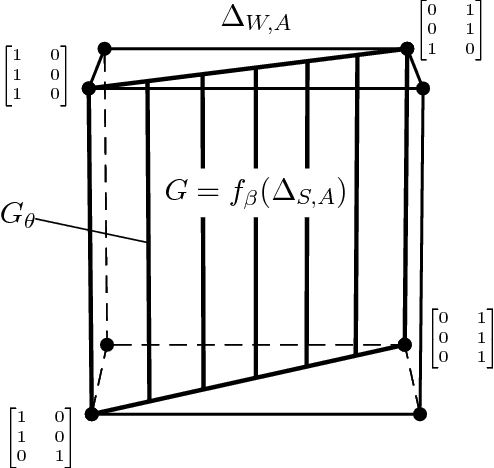
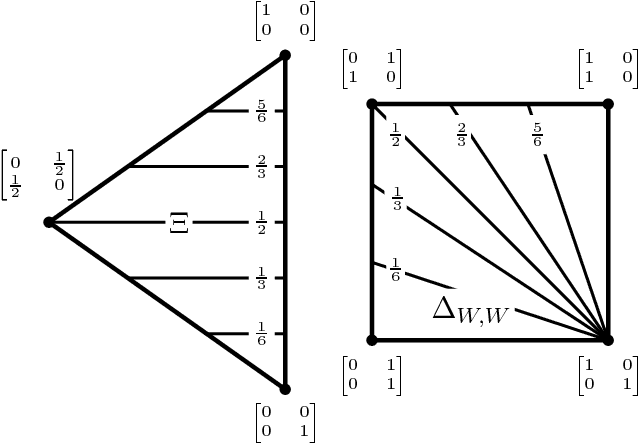
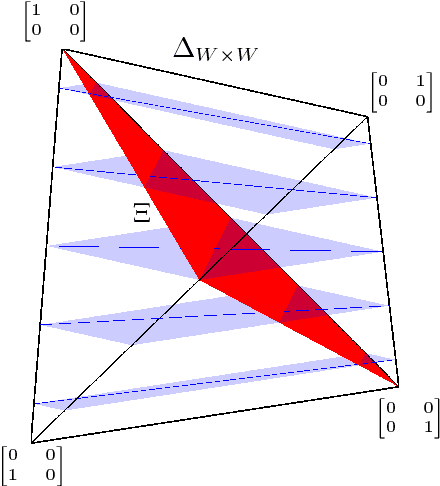
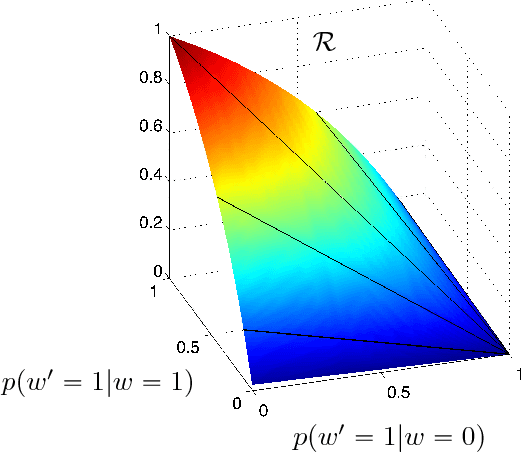
It is well known that for any finite state Markov decision process (MDP) there is a memoryless deterministic policy that maximizes the expected reward. For partially observable Markov decision processes (POMDPs), optimal memoryless policies are generally stochastic. We study the expected reward optimization problem over the set of memoryless stochastic policies. We formulate this as a constrained linear optimization problem and develop a corresponding geometric framework. We show that any POMDP has an optimal memoryless policy of limited stochasticity, which allows us to reduce the dimensionality of the search space. Experiments demonstrate that this approach enables better and faster convergence of the policy gradient on the evaluated systems.
Evaluating Morphological Computation in Muscle and DC-motor Driven Models of Human Hopping
Dec 11, 2015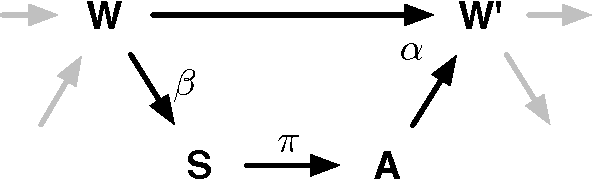
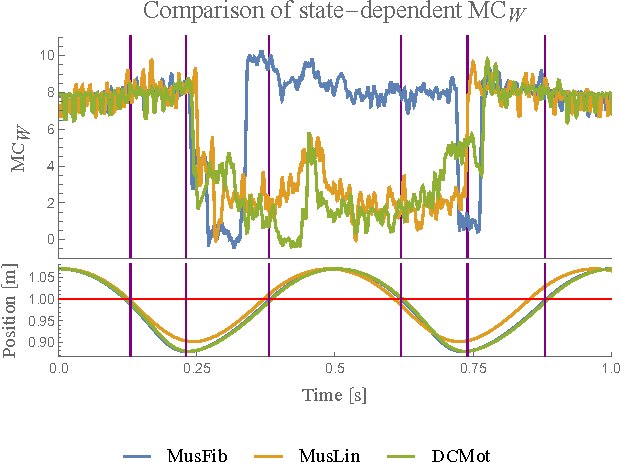
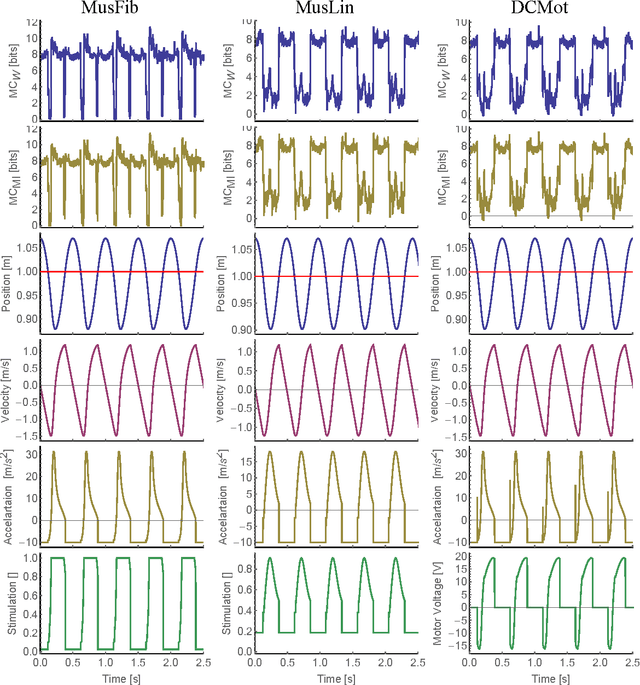
In the context of embodied artificial intelligence, morphological computation refers to processes which are conducted by the body (and environment) that otherwise would have to be performed by the brain. Exploiting environmental and morphological properties is an important feature of embodied systems. The main reason is that it allows to significantly reduce the controller complexity. An important aspect of morphological computation is that it cannot be assigned to an embodied system per se, but that it is, as we show, behavior- and state-dependent. In this work, we evaluate two different measures of morphological computation that can be applied in robotic systems and in computer simulations of biological movement. As an example, these measures were evaluated on muscle and DC-motor driven hopping models. We show that a state-dependent analysis of the hopping behaviors provides additional insights that cannot be gained from the averaged measures alone. This work includes algorithms and computer code for the measures.
Geometry and Expressive Power of Conditional Restricted Boltzmann Machines
Mar 12, 2015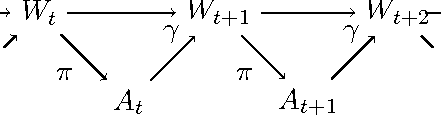
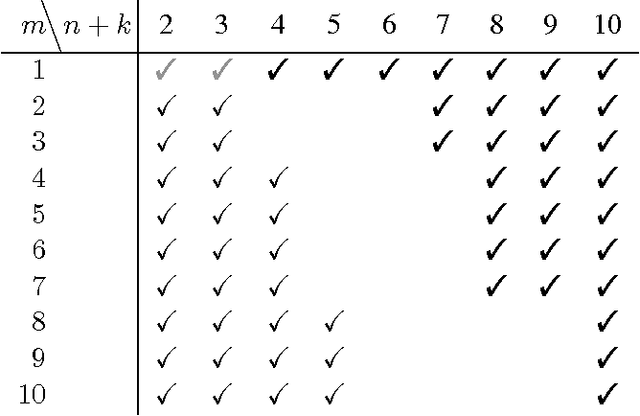
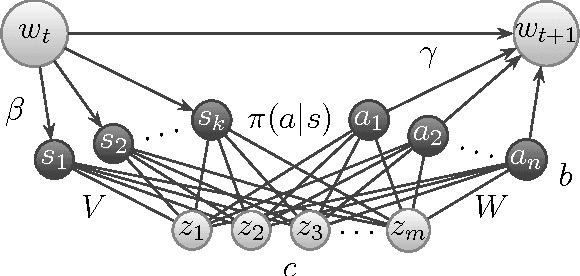
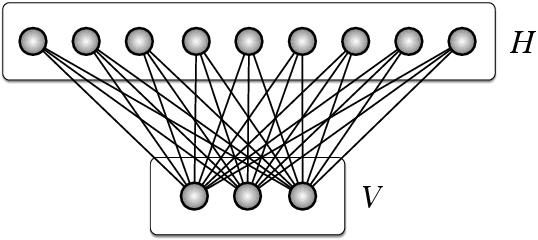
Conditional restricted Boltzmann machines are undirected stochastic neural networks with a layer of input and output units connected bipartitely to a layer of hidden units. These networks define models of conditional probability distributions on the states of the output units given the states of the input units, parametrized by interaction weights and biases. We address the representational power of these models, proving results their ability to represent conditional Markov random fields and conditional distributions with restricted supports, the minimal size of universal approximators, the maximal model approximation errors, and on the dimension of the set of representable conditional distributions. We contribute new tools for investigating conditional probability models, which allow us to improve the results that can be derived from existing work on restricted Boltzmann machine probability models.