 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNilesh Madhu
Margin-Mixup: A Method for Robust Speaker Verification in Multi-Speaker Audio
Apr 07, 2023
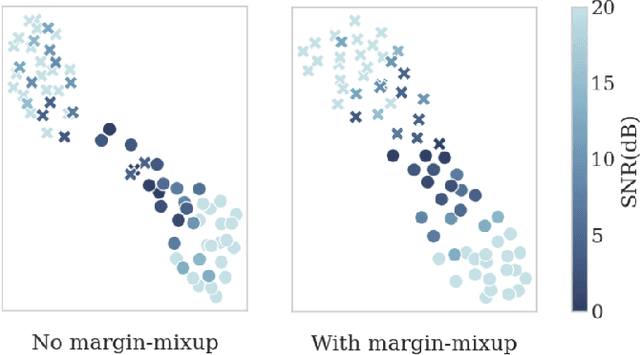
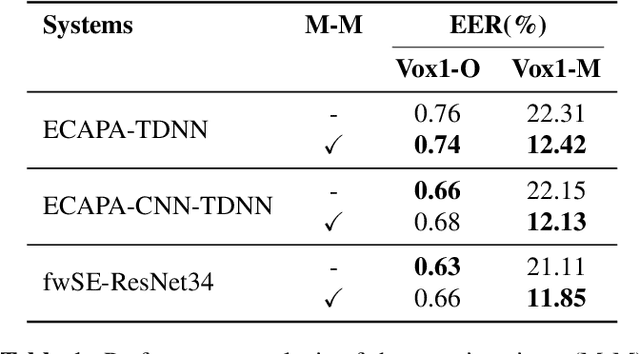
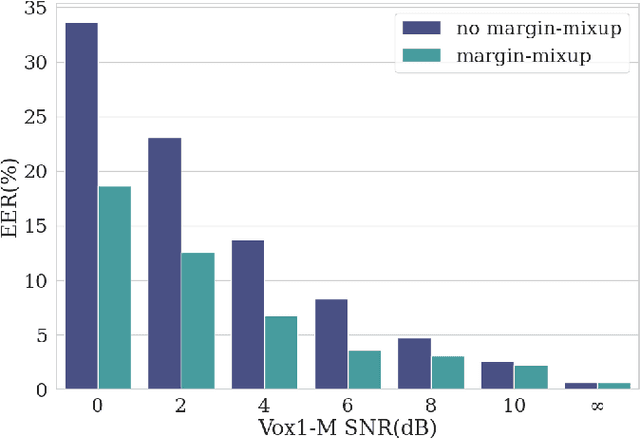
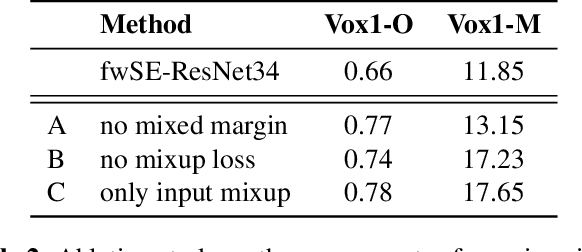
This paper is concerned with the task of speaker verification on audio with multiple overlapping speakers. Most speaker verification systems are designed with the assumption of a single speaker being present in a given audio segment. However, in a real-world setting this assumption does not always hold. In this paper, we demonstrate that current speaker verification systems are not robust against audio with noticeable speaker overlap. To alleviate this issue, we propose margin-mixup, a simple training strategy that can easily be adopted by existing speaker verification pipelines to make the resulting speaker embeddings robust against multi-speaker audio. In contrast to other methods, margin-mixup requires no alterations to regular speaker verification architectures, while attaining better results. On our multi-speaker test set based on VoxCeleb1, the proposed margin-mixup strategy improves the EER on average with 44.4% relative to our state-of-the-art speaker verification baseline systems.
Robust Acoustic Scene Classification in the Presence of Active Foreground Speech
Aug 02, 2021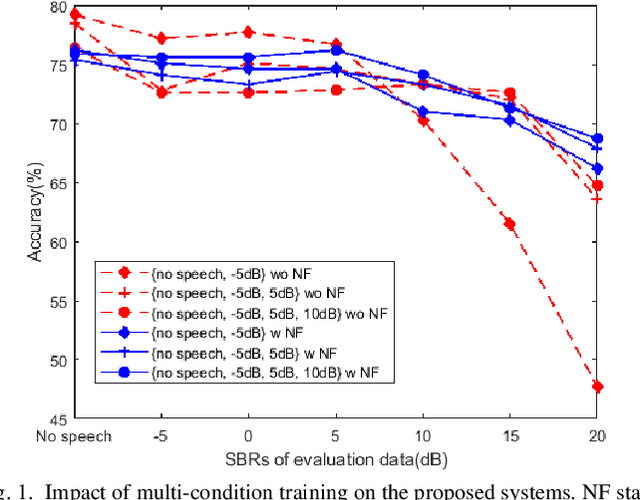


We present an iVector based Acoustic Scene Classification (ASC) system suited for real life settings where active foreground speech can be present. In the proposed system, each recording is represented by a fixed-length iVector that models the recording's important properties. A regularized Gaussian backend classifier with class-specific covariance models is used to extract the relevant acoustic scene information from these iVectors. To alleviate the large performance degradation when a foreground speaker dominates the captured signal, we investigate the use of the iVector framework on Mel-Frequency Cepstral Coefficients (MFCCs) that are derived from an estimate of the noise power spectral density. This noise-floor can be extracted in a statistical manner for single channel recordings. We show that the use of noise-floor features is complementary to multi-condition training in which foreground speech is added to training signal to reduce the mismatch between training and testing conditions. Experimental results on the DCASE 2016 Task 1 dataset show that the noise-floor based features and multi-condition training realize significant classification accuracy gains of up to more than 25 percentage points (absolute) in the most adverse conditions. These promising results can further facilitate the integration of ASC in resource-constrained devices such as hearables.