 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNils M. Kriege
Non-Redundant Graph Neural Networks with Improved Expressiveness
Oct 06, 2023
Message passing graph neural networks iteratively compute node embeddings by aggregating messages from all neighbors. This procedure can be viewed as a neural variant of the Weisfeiler-Leman method, which limits their expressive power. Moreover, oversmoothing and oversquashing restrict the number of layers these networks can effectively utilize. The repeated exchange and encoding of identical information in message passing amplifies oversquashing. We propose a novel aggregation scheme based on neighborhood trees, which allows for controlling the redundancy by pruning branches of the unfolding trees underlying standard message passing. We prove that reducing redundancy improves expressivity and experimentally show that it alleviates oversquashing. We investigate the interaction between redundancy in message passing and redundancy in computation and propose a compact representation of neighborhood trees, from which we compute node and graph embeddings via a neural tree canonization technique. Our method is provably more expressive than the Weisfeiler-Leman method, less susceptible to oversquashing than message passing neural networks, and provides high classification accuracy on widely-used benchmark datasets.
Gradual Weisfeiler-Leman: Slow and Steady Wins the Race
Sep 19, 2022



The classical Weisfeiler-Leman algorithm aka color refinement is fundamental for graph learning and central for successful graph kernels and graph neural networks. Originally developed for graph isomorphism testing, the algorithm iteratively refines vertex colors. On many datasets, the stable coloring is reached after a few iterations and the optimal number of iterations for machine learning tasks is typically even lower. This suggests that the colors diverge too fast, defining a similarity that is too coarse. We generalize the concept of color refinement and propose a framework for gradual neighborhood refinement, which allows a slower convergence to the stable coloring and thus provides a more fine-grained refinement hierarchy and vertex similarity. We assign new colors by clustering vertex neighborhoods, replacing the original injective color assignment function. Our approach is used to derive new variants of existing graph kernels and to approximate the graph edit distance via optimal assignments regarding vertex similarity. We show that in both tasks, our method outperforms the original color refinement with only moderate increase in running time advancing the state of the art.
A Temporal Graphlet Kernel for Classifying Dissemination in Evolving Networks
Sep 12, 2022



We introduce the \emph{temporal graphlet kernel} for classifying dissemination processes in labeled temporal graphs. Such dissemination processes can be spreading (fake) news, infectious diseases, or computer viruses in dynamic networks. The networks are modeled as labeled temporal graphs, in which the edges exist at specific points in time, and node labels change over time. The classification problem asks to discriminate dissemination processes of different origins or parameters, e.g., infectious diseases with different infection probabilities. Our new kernel represents labeled temporal graphs in the feature space of temporal graphlets, i.e., small subgraphs distinguished by their structure, time-dependent node labels, and chronological order of edges. We introduce variants of our kernel based on classes of graphlets that are efficiently countable. For the case of temporal wedges, we propose a highly efficient approximative kernel with low error in expectation. We show that our kernels are faster to compute and provide better accuracy than state-of-the-art methods.
Weisfeiler and Leman Go Walking: Random Walk Kernels Revisited
May 22, 2022



Random walk kernels have been introduced in seminal work on graph learning and were later largely superseded by kernels based on the Weisfeiler-Leman test for graph isomorphism. We give a unified view on both classes of graph kernels. We study walk-based node refinement methods and formally relate them to several widely-used techniques, including Morgan's algorithm for molecule canonization and the Weisfeiler-Leman test. We define corresponding walk-based kernels on nodes that allow fine-grained parameterized neighborhood comparison, reach Weisfeiler-Leman expressiveness, and are computed using the kernel trick. From this we show that classical random walk kernels with only minor modifications regarding definition and computation are as expressive as the widely-used Weisfeiler-Leman subtree kernel but support non-strict neighborhood comparison. We verify experimentally that walk-based kernels reach or even surpass the accuracy of Weisfeiler-Leman kernels in real-world classification tasks.
Temporal Walk Centrality: Ranking Nodes in Evolving Networks
Feb 08, 2022



We propose the Temporal Walk Centrality, which quantifies the importance of a node by measuring its ability to obtain and distribute information in a temporal network. In contrast to the widely-used betweenness centrality, we assume that information does not necessarily spread on shortest paths but on temporal random walks that satisfy the time constraints of the network. We show that temporal walk centrality can identify nodes playing central roles in dissemination processes that might not be detected by related betweenness concepts and other common static and temporal centrality measures. We propose exact and approximation algorithms with different running times depending on the properties of the temporal network and parameters of our new centrality measure. A technical contribution is a general approach to lift existing algebraic methods for counting walks in static networks to temporal networks. Our experiments on real-world temporal networks show the efficiency and accuracy of our algorithms. Finally, we demonstrate that the rankings by temporal walk centrality often differ significantly from those of other state-of-the-art temporal centralities.
Weisfeiler and Leman go Machine Learning: The Story so far
Dec 18, 2021



In recent years, algorithms and neural architectures based on the Weisfeiler-Leman algorithm, a well-known heuristic for the graph isomorphism problem, emerged as a powerful tool for machine learning with graphs and relational data. Here, we give a comprehensive overview of the algorithm's use in a machine learning setting, focusing on the supervised regime. We discuss the theoretical background, show how to use it for supervised graph- and node representation learning, discuss recent extensions, and outline the algorithm's connection to (permutation-)equivariant neural architectures. Moreover, we give an overview of current applications and future directions to stimulate further research.
The Power of the Weisfeiler-Leman Algorithm for Machine Learning with Graphs
May 12, 2021


In recent years, algorithms and neural architectures based on the Weisfeiler-Leman algorithm, a well-known heuristic for the graph isomorphism problem, emerged as a powerful tool for (supervised) machine learning with graphs and relational data. Here, we give a comprehensive overview of the algorithm's use in a machine learning setting. We discuss the theoretical background, show how to use it for supervised graph- and node classification, discuss recent extensions, and its connection to neural architectures. Moreover, we give an overview of current applications and future directions to stimulate research.
TUDataset: A collection of benchmark datasets for learning with graphs
Jul 16, 2020



Recently, there has been an increasing interest in (supervised) learning with graph data, especially using graph neural networks. However, the development of meaningful benchmark datasets and standardized evaluation procedures is lagging, consequently hindering advancements in this area. To address this, we introduce the TUDataset for graph classification and regression. The collection consists of over 120 datasets of varying sizes from a wide range of applications. We provide Python-based data loaders, kernel and graph neural network baseline implementations, and evaluation tools. Here, we give an overview of the datasets, standardized evaluation procedures, and provide baseline experiments. All datasets are available at www.graphlearning.io. The experiments are fully reproducible from the code available at www.github.com/chrsmrrs/tudataset.
Deep Graph Matching Consensus
Jan 27, 2020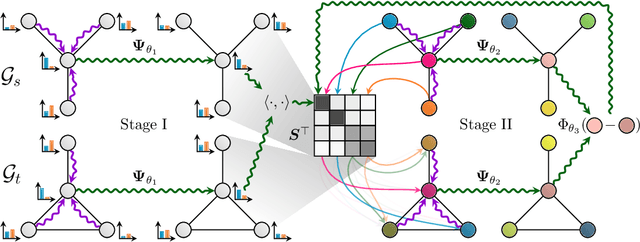
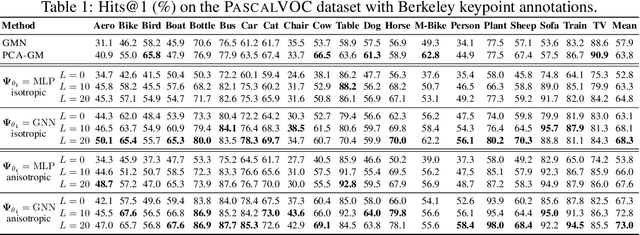
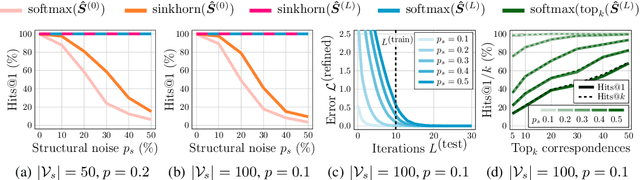
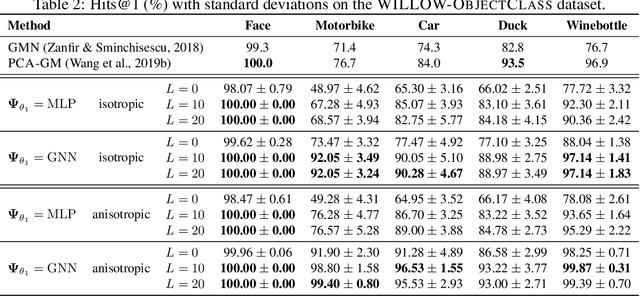
This work presents a two-stage neural architecture for learning and refining structural correspondences between graphs. First, we use localized node embeddings computed by a graph neural network to obtain an initial ranking of soft correspondences between nodes. Secondly, we employ synchronous message passing networks to iteratively re-rank the soft correspondences to reach a matching consensus in local neighborhoods between graphs. We show, theoretically and empirically, that our message passing scheme computes a well-founded measure of consensus for corresponding neighborhoods, which is then used to guide the iterative re-ranking process. Our purely local and sparsity-aware architecture scales well to large, real-world inputs while still being able to recover global correspondences consistently. We demonstrate the practical effectiveness of our method on real-world tasks from the fields of computer vision and entity alignment between knowledge graphs, on which we improve upon the current state-of-the-art. Our source code is available under https://github.com/rusty1s/ deep-graph-matching-consensus.
Temporal Graph Kernels for Classifying Dissemination Processes
Oct 14, 2019



Many real-world graphs or networks are temporal, e.g., in a social network persons only interact at specific points in time. This information directs dissemination processes on the network, such as the spread of rumors, fake news, or diseases. However, the current state-of-the-art methods for supervised graph classification are designed mainly for static graphs and may not be able to capture temporal information. Hence, they are not powerful enough to distinguish between graphs modeling different dissemination processes. To address this, we introduce a framework to lift standard graph kernels to the temporal domain. Specifically, we explore three different approaches and investigate the trade-offs between loss of temporal information and efficiency. Moreover, to handle large-scale graphs, we propose stochastic variants of our kernels with provable approximation guarantees. We evaluate our methods on a wide range of real-world social networks. Our methods beat static kernels by a large margin in terms of accuracy while still being scalable to large graphs and data sets. Hence, we confirm that taking temporal information into account is crucial for the successful classification of dissemination processes.