 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNiraj K. Jha
DynaMo: Accelerating Language Model Inference with Dynamic Multi-Token Sampling
May 01, 2024
Traditional language models operate autoregressively, i.e., they predict one token at a time. Rapid explosion in model sizes has resulted in high inference times. In this work, we propose DynaMo, a suite of multi-token prediction language models that reduce net inference times. Our models $\textit{dynamically}$ predict multiple tokens based on their confidence in the predicted joint probability distribution. We propose a lightweight technique to train these models, leveraging the weights of traditional autoregressive counterparts. Moreover, we propose novel ways to enhance the estimated joint probability to improve text generation quality, namely co-occurrence weighted masking and adaptive thresholding. We also propose systematic qualitative and quantitative methods to rigorously test the quality of generated text for non-autoregressive generation. One of the models in our suite, DynaMo-7.3B-T3, achieves same-quality generated text as the baseline (Pythia-6.9B) while achieving 2.57$\times$ speed-up with only 5.87% and 2.67% parameter and training time overheads, respectively.
PAGE: Domain-Incremental Adaptation with Past-Agnostic Generative Replay for Smart Healthcare
Mar 13, 2024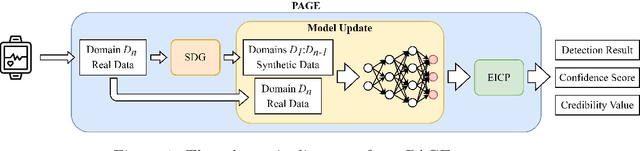
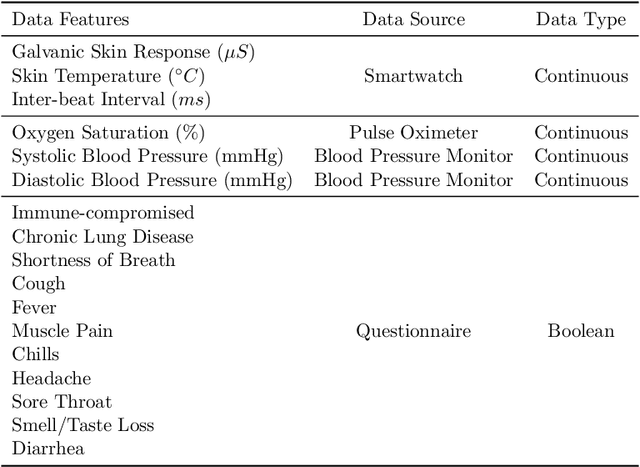
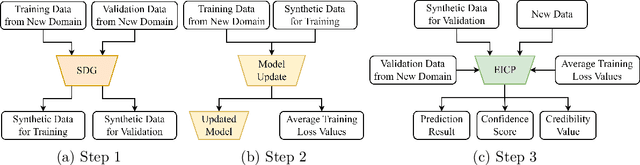
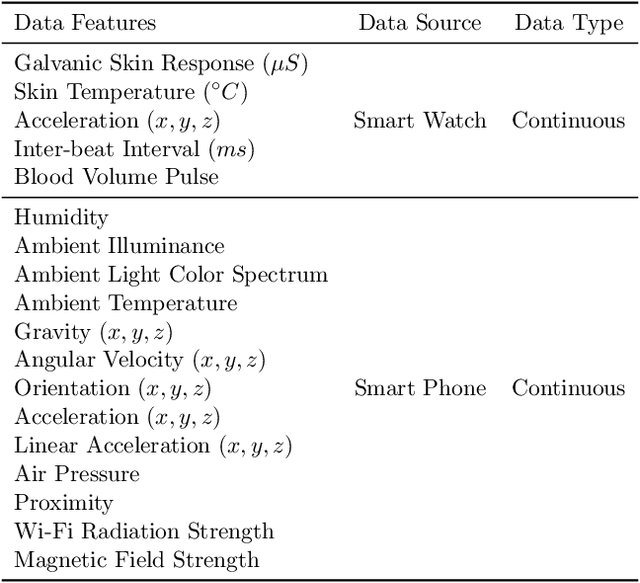
We propose PAGE, a domain-incremental adaptation strategy with past-agnostic generative replay for smart healthcare. PAGE enables generative replay without the aid of any preserved data or information from prior domains. When adapting to a new domain, it exploits real data from the new distribution and the current model to generate synthetic data that retain the learned knowledge of previous domains. By replaying the synthetic data with the new real data during training, PAGE achieves a good balance between domain adaptation and knowledge retention. In addition, we incorporate an extended inductive conformal prediction (EICP) method into PAGE to produce a confidence score and a credibility value for each detection result. This makes the predictions interpretable and provides statistical guarantees for disease detection in smart healthcare applications. We demonstrate PAGE's effectiveness in domain-incremental disease detection with three distinct disease datasets collected from commercially available WMSs. PAGE achieves highly competitive performance against state-of-the-art with superior scalability, data privacy, and feasibility. Furthermore, PAGE can enable up to 75% reduction in clinical workload with the help of EICP.
TAD-SIE: Sample Size Estimation for Clinical Randomized Controlled Trials using a Trend-Adaptive Design with a Synthetic-Intervention-Based Estimator
Jan 08, 2024Phase-3 clinical trials provide the highest level of evidence on drug safety and effectiveness needed for market approval by implementing large randomized controlled trials (RCTs). However, 30-40% of these trials fail mainly because such studies have inadequate sample sizes, stemming from the inability to obtain accurate initial estimates of average treatment effect parameters. To remove this obstacle from the drug development cycle, we present a new algorithm called Trend-Adaptive Design with a Synthetic-Intervention-Based Estimator (TAD-SIE) that appropriately powers a parallel-group trial, a standard RCT design, by leveraging a state-of-the-art hypothesis testing strategy and a novel trend-adaptive design (TAD). Specifically, TAD-SIE uses SECRETS (Subject-Efficient Clinical Randomized Controlled Trials using Synthetic Intervention) for hypothesis testing, which simulates a cross-over trial in order to boost power; doing so, makes it easier for a trial to reach target power within trial constraints (e.g., sample size limits). To estimate sample sizes, TAD-SIE implements a new TAD tailored to SECRETS given that SECRETS violates assumptions under standard TADs. In addition, our TAD overcomes the ineffectiveness of standard TADs by allowing sample sizes to be increased across iterations without any condition while controlling significance level with futility stopping. On a real-world Phase-3 clinical RCT (i.e., a two-arm parallel-group superiority trial with an equal number of subjects per arm), TAD-SIE reaches typical target operating points of 80% or 90% power and 5% significance level in contrast to baseline algorithms that only get at best 59% power and 4% significance level.
BREATHE: Second-Order Gradients and Heteroscedastic Emulation based Design Space Exploration
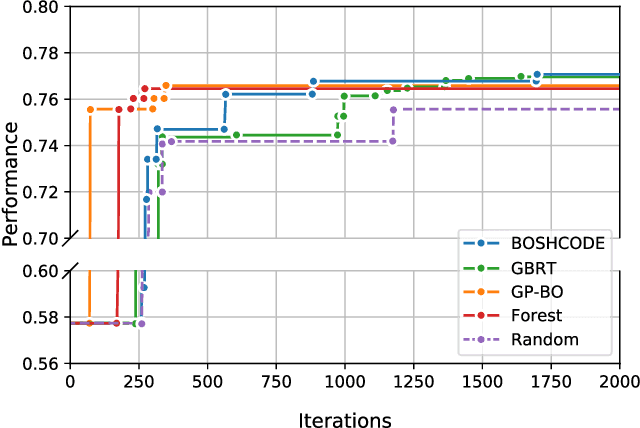
Aug 16, 2023Researchers constantly strive to explore larger and more complex search spaces in various scientific studies and physical experiments. However, such investigations often involve sophisticated simulators or time-consuming experiments that make exploring and observing new design samples challenging. Previous works that target such applications are typically sample-inefficient and restricted to vector search spaces. To address these limitations, this work proposes a constrained multi-objective optimization (MOO) framework, called BREATHE, that searches not only traditional vector-based design spaces but also graph-based design spaces to obtain best-performing graphs. It leverages second-order gradients and actively trains a heteroscedastic surrogate model for sample-efficient optimization. In a single-objective vector optimization application, it leads to 64.1% higher performance than the next-best baseline, random forest regression. In graph-based search, BREATHE outperforms the next-best baseline, i.e., a graphical version of Gaussian-process-based Bayesian optimization, with up to 64.9% higher performance. In a MOO task, it achieves up to 21.9$\times$ higher hypervolume than the state-of-the-art method, multi-objective Bayesian optimization (MOBOpt). BREATHE also outperforms the baseline methods on most standard MOO benchmark applications.
Zero-TPrune: Zero-Shot Token Pruning through Leveraging of the Attention Graph in Pre-Trained Transformers
May 27, 2023

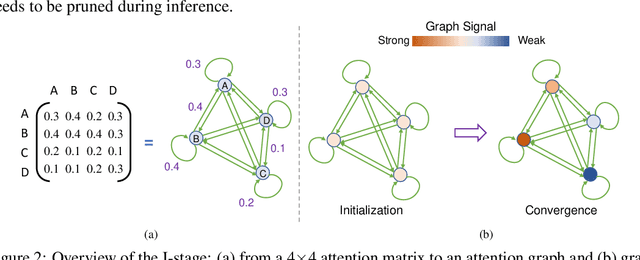

Deployment of Transformer models on the edge is increasingly challenging due to the exponentially growing model size and inference cost that scales quadratically with the number of tokens in the input sequence. Token pruning is an emerging solution to address this challenge due to its ease of deployment on various Transformer backbones. However, most token pruning methods require a computationally-expensive fine-tuning process after or during pruning, which is not desirable in many cases. Some recent works explore pruning of off-the-shelf pre-trained Transformers without fine-tuning. However, they only take the importance of tokens into consideration. In this work, we propose Zero-TPrune, the first zero-shot method that considers both the importance and similarity of tokens in performing token pruning. Zero-TPrune leverages the attention graph of pre-trained Transformer models to produce an importance rank for tokens and removes the less informative tokens. The attention matrix can be thought of as an adjacency matrix of a directed graph, to which a graph shift operator can be applied iteratively to obtain the importance score distribution. This distribution guides the partition of tokens into two groups and measures similarity between them. Due to the elimination of the fine-tuning overhead, Zero-TPrune can easily prune large models and perform hyperparameter tuning efficiently. We evaluate the performance of Zero-TPrune on vision tasks by applying it to various vision Transformer backbones. Compared with state-of-the-art pruning methods that require fine-tuning, Zero-TPrune not only eliminates the need for fine-tuning after pruning, but does so with only around 0.3% accuracy loss. Compared with state-of-the-art fine-tuning-free pruning methods, Zero-TPrune reduces accuracy loss by up to 45% on medium-sized models.
Im-Promptu: In-Context Composition from Image Prompts
May 26, 2023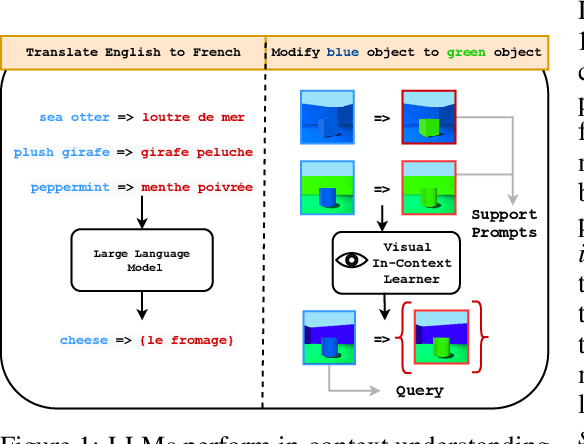

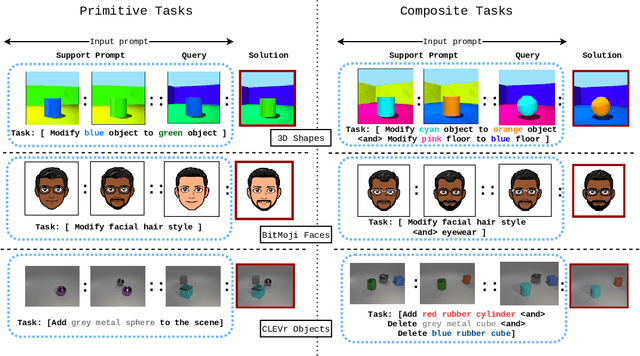
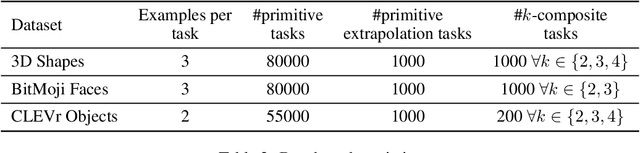
Large language models are few-shot learners that can solve diverse tasks from a handful of demonstrations. This implicit understanding of tasks suggests that the attention mechanisms over word tokens may play a role in analogical reasoning. In this work, we investigate whether analogical reasoning can enable in-context composition over composable elements of visual stimuli. First, we introduce a suite of three benchmarks to test the generalization properties of a visual in-context learner. We formalize the notion of an analogy-based in-context learner and use it to design a meta-learning framework called Im-Promptu. Whereas the requisite token granularity for language is well established, the appropriate compositional granularity for enabling in-context generalization in visual stimuli is usually unspecified. To this end, we use Im-Promptu to train multiple agents with different levels of compositionality, including vector representations, patch representations, and object slots. Our experiments reveal tradeoffs between extrapolation abilities and the degree of compositionality, with non-compositional representations extending learned composition rules to unseen domains but performing poorly on combinatorial tasks. Patch-based representations require patches to contain entire objects for robust extrapolation. At the same time, object-centric tokenizers coupled with a cross-attention module generate consistent and high-fidelity solutions, with these inductive biases being particularly crucial for compositional generalization. Lastly, we demonstrate a use case of Im-Promptu as an intuitive programming interface for image generation.
DOCTOR: A Multi-Disease Detection Continual Learning Framework Based on Wearable Medical Sensors
May 09, 2023
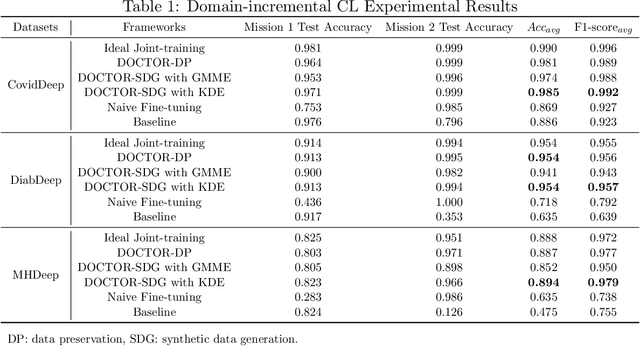
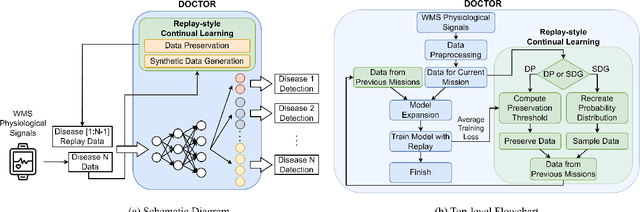
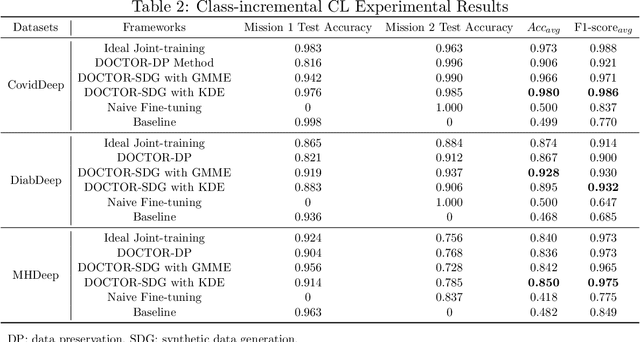
Modern advances in machine learning (ML) and wearable medical sensors (WMSs) in edge devices have enabled ML-driven disease detection for smart healthcare. Conventional ML-driven disease detection methods rely on customizing individual models for each disease and its corresponding WMS data. However, such methods lack adaptability to distribution shifts and new task classification classes. Also, they need to be rearchitected and retrained from scratch for each new disease. Moreover, installing multiple ML models in an edge device consumes excessive memory, drains the battery faster, and complicates the detection process. To address these challenges, we propose DOCTOR, a multi-disease detection continual learning (CL) framework based on WMSs. It employs a multi-headed deep neural network (DNN) and an exemplar-replay-style CL algorithm. The CL algorithm enables the framework to continually learn new missions where different data distributions, classification classes, and disease detection tasks are introduced sequentially. It counteracts catastrophic forgetting with a data preservation method and a synthetic data generation module. The data preservation method efficiently preserves the most informative subset of training data from previous missions based on the average training loss of each data instance. The synthetic data generation module models the probability distribution of the real training data and then generates as much synthetic data as needed for replays while maintaining data privacy. The multi-headed DNN enables DOCTOR to detect multiple diseases simultaneously based on user WMS data. We demonstrate DOCTOR's efficacy in maintaining high multi-disease classification accuracy with a single DNN model in various CL experiments. DOCTOR achieves very competitive performance across all CL scenarios relative to the ideal joint-training framework while maintaining a small model size.
SECRETS: Subject-Efficient Clinical Randomized Controlled Trials using Synthetic Intervention
May 08, 2023


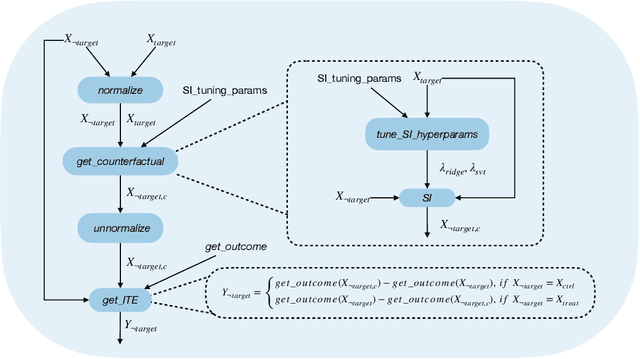
The randomized controlled trial (RCT) is the gold standard for estimating the average treatment effect (ATE) of a medical intervention but requires 100s-1000s of subjects, making it expensive and difficult to implement. While a cross-over trial can reduce sample size requirements by measuring the treatment effect per individual, it is only applicable to chronic conditions and interventions whose effects dissipate rapidly. Another approach is to replace or augment data collected from an RCT with external data from prospective studies or prior RCTs, but it is vulnerable to confounders in the external or augmented data. We propose to simulate the cross-over trial to overcome its practical limitations while exploiting its strengths. We propose a novel framework, SECRETS, which, for the first time, estimates the individual treatment effect (ITE) per patient in the RCT study without using any external data by leveraging a state-of-the-art counterfactual estimation algorithm, called synthetic intervention. It also uses a new hypothesis testing strategy to determine whether the treatment has a clinically significant ATE based on the estimated ITEs. We show that SECRETS can improve the power of an RCT while maintaining comparable significance levels; in particular, on three real-world clinical RCTs (Phase-3 trials), SECRETS increases power over the baseline method by $\boldsymbol{6}$-$\boldsymbol{54\%}$ (average: 21.5%, standard deviation: 15.8%).
TransCODE: Co-design of Transformers and Accelerators for Efficient Training and Inference
Mar 27, 2023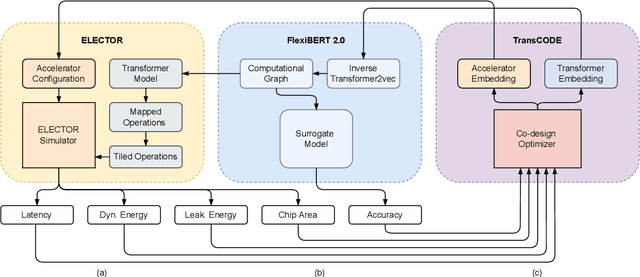
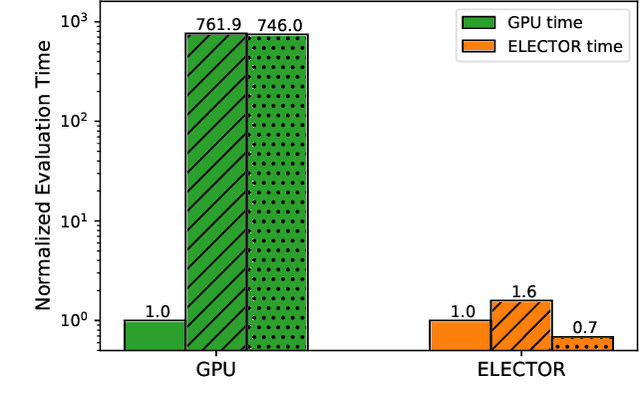
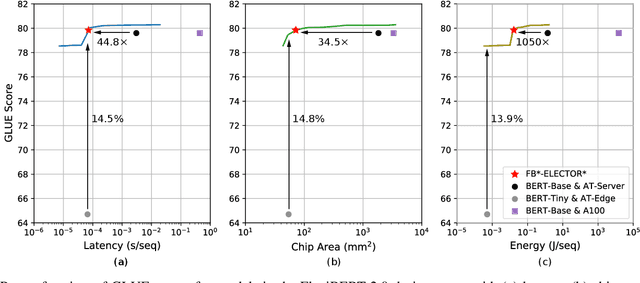
Automated co-design of machine learning models and evaluation hardware is critical for efficiently deploying such models at scale. Despite the state-of-the-art performance of transformer models, they are not yet ready for execution on resource-constrained hardware platforms. High memory requirements and low parallelizability of the transformer architecture exacerbate this problem. Recently-proposed accelerators attempt to optimize the throughput and energy consumption of transformer models. However, such works are either limited to a one-sided search of the model architecture or a restricted set of off-the-shelf devices. Furthermore, previous works only accelerate model inference and not training, which incurs substantially higher memory and compute resources, making the problem even more challenging. To address these limitations, this work proposes a dynamic training framework, called DynaProp, that speeds up the training process and reduces memory consumption. DynaProp is a low-overhead pruning method that prunes activations and gradients at runtime. To effectively execute this method on hardware for a diverse set of transformer architectures, we propose ELECTOR, a framework that simulates transformer inference and training on a design space of accelerators. We use this simulator in conjunction with the proposed co-design technique, called TransCODE, to obtain the best-performing models with high accuracy on the given task and minimize latency, energy consumption, and chip area. The obtained transformer-accelerator pair achieves 0.3% higher accuracy than the state-of-the-art pair while incurring 5.2$\times$ lower latency and 3.0$\times$ lower energy consumption.
EdgeTran: Co-designing Transformers for Efficient Inference on Mobile Edge Platforms
Mar 24, 2023
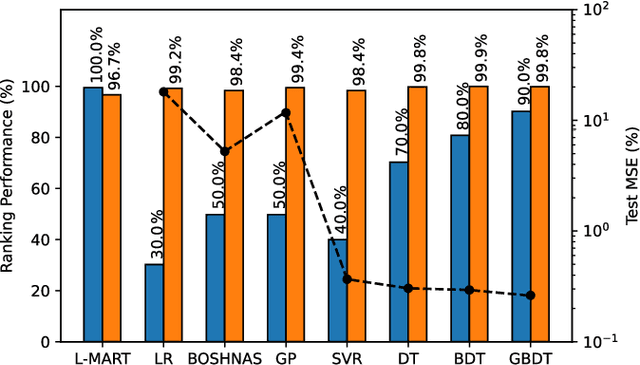
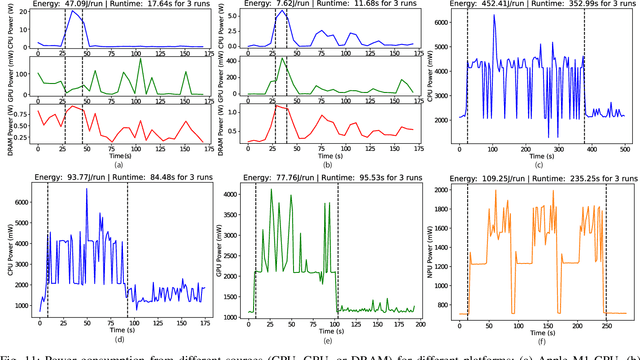
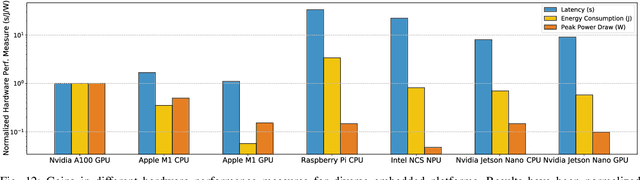
Automated design of efficient transformer models has recently attracted significant attention from industry and academia. However, most works only focus on certain metrics while searching for the best-performing transformer architecture. Furthermore, running traditional, complex, and large transformer models on low-compute edge platforms is a challenging problem. In this work, we propose a framework, called ProTran, to profile the hardware performance measures for a design space of transformer architectures and a diverse set of edge devices. We use this profiler in conjunction with the proposed co-design technique to obtain the best-performing models that have high accuracy on the given task and minimize latency, energy consumption, and peak power draw to enable edge deployment. We refer to our framework for co-optimizing accuracy and hardware performance measures as EdgeTran. It searches for the best transformer model and edge device pair. Finally, we propose GPTran, a multi-stage block-level grow-and-prune post-processing step that further improves accuracy in a hardware-aware manner. The obtained transformer model is 2.8$\times$ smaller and has a 0.8% higher GLUE score than the baseline (BERT-Base). Inference with it on the selected edge device enables 15.0% lower latency, 10.0$\times$ lower energy, and 10.8$\times$ lower peak power draw compared to an off-the-shelf GPU.