 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNorman Ferns
Metrics for Finite Markov Decision Processes
Jul 11, 2012
We present metrics for measuring the similarity of states in a finite Markov decision process (MDP). The formulation of our metrics is based on the notion of bisimulation for MDPs, with an aim towards solving discounted infinite horizon reinforcement learning tasks. Such metrics can be used to aggregate states, as well as to better structure other value function approximators (e.g., memory-based or nearest-neighbor approximators). We provide bounds that relate our metric distances to the optimal values of states in the given MDP.
Metrics for Markov Decision Processes with Infinite State Spaces
Jul 04, 2012We present metrics for measuring state similarity in Markov decision processes (MDPs) with infinitely many states, including MDPs with continuous state spaces. Such metrics provide a stable quantitative analogue of the notion of bisimulation for MDPs, and are suitable for use in MDP approximation. We show that the optimal value function associated with a discounted infinite horizon planning task varies continuously with respect to our metric distances.
Methods for computing state similarity in Markov Decision Processes
Jun 27, 2012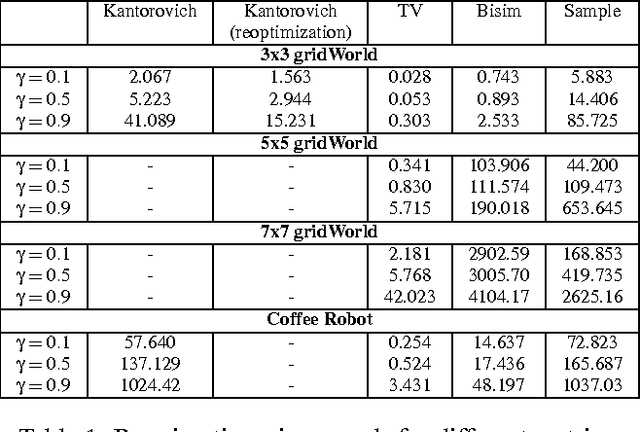
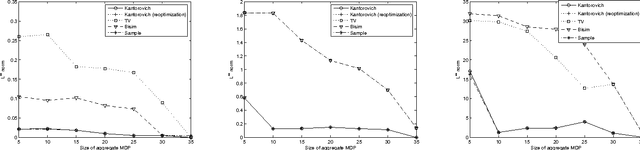

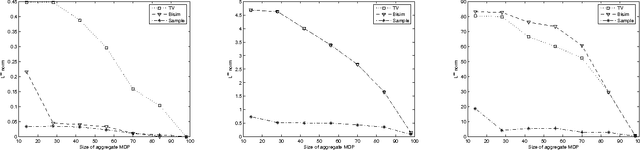
A popular approach to solving large probabilistic systems relies on aggregating states based on a measure of similarity. Many approaches in the literature are heuristic. A number of recent methods rely instead on metrics based on the notion of bisimulation, or behavioral equivalence between states (Givan et al, 2001, 2003; Ferns et al, 2004). An integral component of such metrics is the Kantorovich metric between probability distributions. However, while this metric enables many satisfying theoretical properties, it is costly to compute in practice. In this paper, we use techniques from network optimization and statistical sampling to overcome this problem. We obtain in this manner a variety of distance functions for MDP state aggregation, which differ in the tradeoff between time and space complexity, as well as the quality of the aggregation. We provide an empirical evaluation of these trade-offs.