 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOdalric-Ambrym Maillard
CRIMED: Lower and Upper Bounds on Regret for Bandits with Unbounded Stochastic Corruption
Sep 28, 2023
We investigate the regret-minimisation problem in a multi-armed bandit setting with arbitrary corruptions. Similar to the classical setup, the agent receives rewards generated independently from the distribution of the arm chosen at each time. However, these rewards are not directly observed. Instead, with a fixed $\varepsilon\in (0,\frac{1}{2})$, the agent observes a sample from the chosen arm's distribution with probability $1-\varepsilon$, or from an arbitrary corruption distribution with probability $\varepsilon$. Importantly, we impose no assumptions on these corruption distributions, which can be unbounded. In this setting, accommodating potentially unbounded corruptions, we establish a problem-dependent lower bound on regret for a given family of arm distributions. We introduce CRIMED, an asymptotically-optimal algorithm that achieves the exact lower bound on regret for bandits with Gaussian distributions with known variance. Additionally, we provide a finite-sample analysis of CRIMED's regret performance. Notably, CRIMED can effectively handle corruptions with $\varepsilon$ values as high as $\frac{1}{2}$. Furthermore, we develop a tight concentration result for medians in the presence of arbitrary corruptions, even with $\varepsilon$ values up to $\frac{1}{2}$, which may be of independent interest. We also discuss an extension of the algorithm for handling misspecification in Gaussian model.
Monte-Carlo tree search with uncertainty propagation via optimal transport
Sep 19, 2023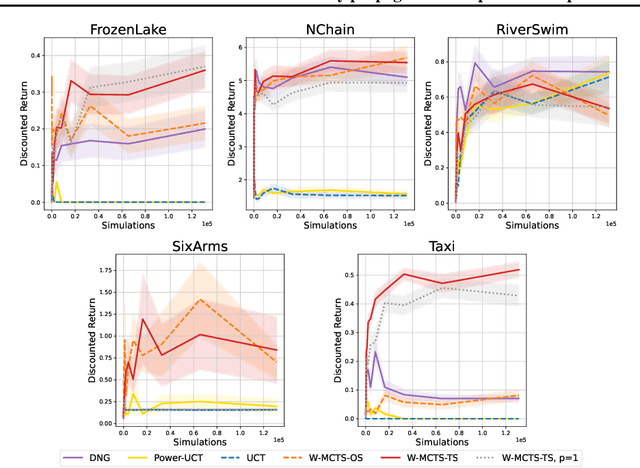
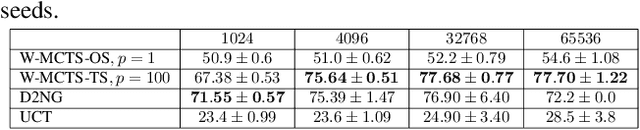
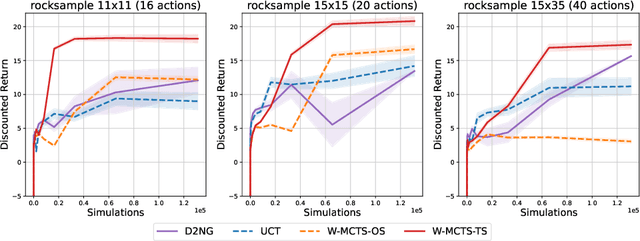
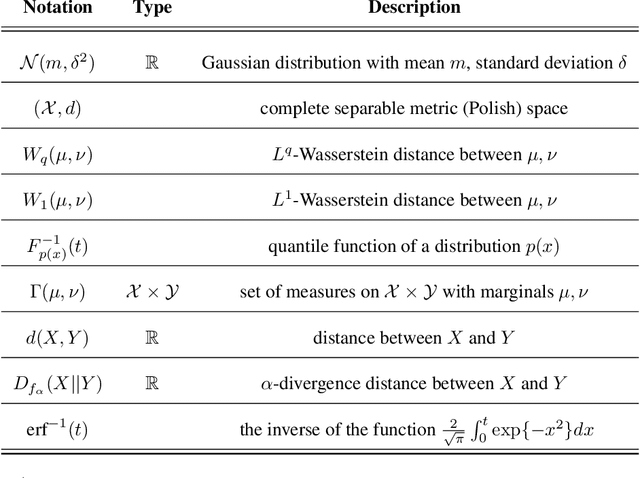
This paper introduces a novel backup strategy for Monte-Carlo Tree Search (MCTS) designed for highly stochastic and partially observable Markov decision processes. We adopt a probabilistic approach, modeling both value and action-value nodes as Gaussian distributions. We introduce a novel backup operator that computes value nodes as the Wasserstein barycenter of their action-value children nodes; thus, propagating the uncertainty of the estimate across the tree to the root node. We study our novel backup operator when using a novel combination of $L^1$-Wasserstein barycenter with $\alpha$-divergence, by drawing a notable connection to the generalized mean backup operator. We complement our probabilistic backup operator with two sampling strategies, based on optimistic selection and Thompson sampling, obtaining our Wasserstein MCTS algorithm. We provide theoretical guarantees of asymptotic convergence to the optimal policy, and an empirical evaluation on several stochastic and partially observable environments, where our approach outperforms well-known related baselines.
AdaStop: sequential testing for efficient and reliable comparisons of Deep RL Agents
Jun 19, 2023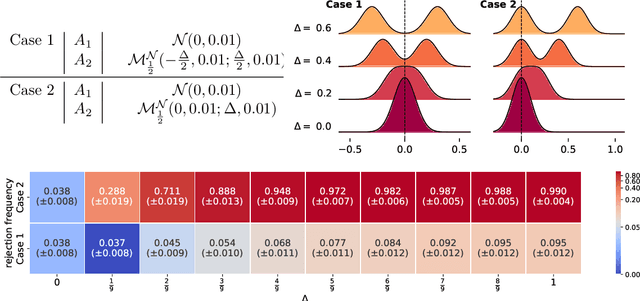



The reproducibility of many experimental results in Deep Reinforcement Learning (RL) is under question. To solve this reproducibility crisis, we propose a theoretically sound methodology to compare multiple Deep RL algorithms. The performance of one execution of a Deep RL algorithm is random so that independent executions are needed to assess it precisely. When comparing several RL algorithms, a major question is how many executions must be made and how can we assure that the results of such a comparison is theoretically sound. Researchers in Deep RL often use less than 5 independent executions to compare algorithms: we claim that this is not enough in general. Moreover, when comparing several algorithms at once, the error of each comparison accumulates and must be taken into account with a multiple tests procedure to preserve low error guarantees. To address this problem in a statistically sound way, we introduce AdaStop, a new statistical test based on multiple group sequential tests. When comparing algorithms, AdaStop adapts the number of executions to stop as early as possible while ensuring that we have enough information to distinguish algorithms that perform better than the others in a statistical significant way. We prove both theoretically and empirically that AdaStop has a low probability of making an error (Family-Wise Error). Finally, we illustrate the effectiveness of AdaStop in multiple use-cases, including toy examples and difficult cases such as Mujoco environments.
Bilinear Exponential Family of MDPs: Frequentist Regret Bound with Tractable Exploration and Planning
Oct 05, 2022

We study the problem of episodic reinforcement learning in continuous state-action spaces with unknown rewards and transitions. Specifically, we consider the setting where the rewards and transitions are modeled using parametric bilinear exponential families. We propose an algorithm, BEF-RLSVI, that a) uses penalized maximum likelihood estimators to learn the unknown parameters, b) injects a calibrated Gaussian noise in the parameter of rewards to ensure exploration, and c) leverages linearity of the exponential family with respect to an underlying RKHS to perform tractable planning. We further provide a frequentist regret analysis of BEF-RLSVI that yields an upper bound of $\tilde{\mathcal{O}}(\sqrt{d^3H^3K})$, where $d$ is the dimension of the parameters, $H$ is the episode length, and $K$ is the number of episodes. Our analysis improves the existing bounds for the bilinear exponential family of MDPs by $\sqrt{H}$ and removes the handcrafted clipping deployed in existing \RLSVI-type algorithms. Our regret bound is order-optimal with respect to $H$ and $K$.
Risk-aware linear bandits with convex loss
Sep 15, 2022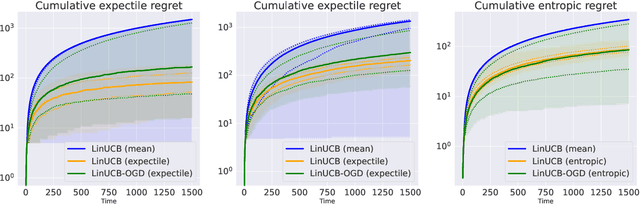

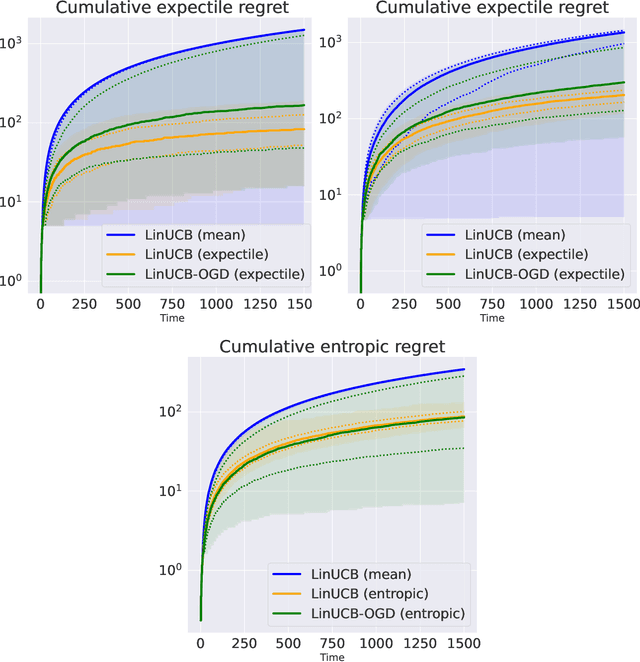

In decision-making problems such as the multi-armed bandit, an agent learns sequentially by optimizing a certain feedback. While the mean reward criterion has been extensively studied, other measures that reflect an aversion to adverse outcomes, such as mean-variance or conditional value-at-risk (CVaR), can be of interest for critical applications (healthcare, agriculture). Algorithms have been proposed for such risk-aware measures under bandit feedback without contextual information. In this work, we study contextual bandits where such risk measures can be elicited as linear functions of the contexts through the minimization of a convex loss. A typical example that fits within this framework is the expectile measure, which is obtained as the solution of an asymmetric least-square problem. Using the method of mixtures for supermartingales, we derive confidence sequences for the estimation of such risk measures. We then propose an optimistic UCB algorithm to learn optimal risk-aware actions, with regret guarantees similar to those of generalized linear bandits. This approach requires solving a convex problem at each round of the algorithm, which we can relax by allowing only approximated solution obtained by online gradient descent, at the cost of slightly higher regret. We conclude by evaluating the resulting algorithms on numerical experiments.
Collaborative Algorithms for Online Personalized Mean Estimation
Aug 24, 2022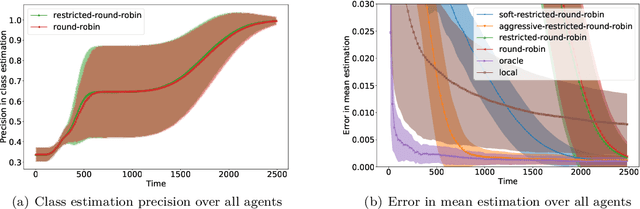

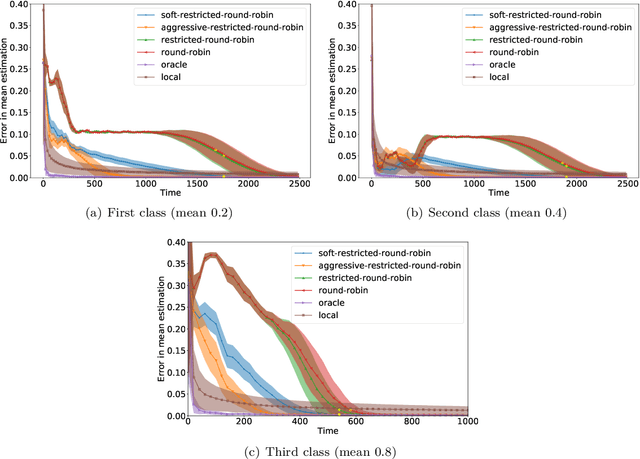
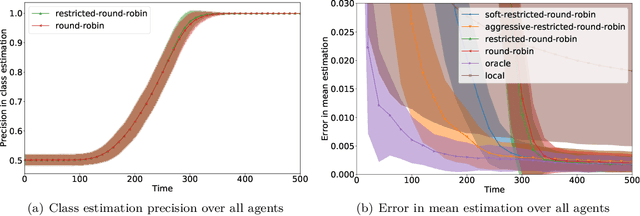
We consider an online estimation problem involving a set of agents. Each agent has access to a (personal) process that generates samples from a real-valued distribution and seeks to estimate its mean. We study the case where some of the distributions have the same mean, and the agents are allowed to actively query information from other agents. The goal is to design an algorithm that enables each agent to improve its mean estimate thanks to communication with other agents. The means as well as the number of distributions with same mean are unknown, which makes the task nontrivial. We introduce a novel collaborative strategy to solve this online personalized mean estimation problem. We analyze its time complexity and introduce variants that enjoy good performance in numerical experiments. We also extend our approach to the setting where clusters of agents with similar means seek to estimate the mean of their cluster.
Bandits Corrupted by Nature: Lower Bounds on Regret and Robust Optimistic Algorithm
Mar 07, 2022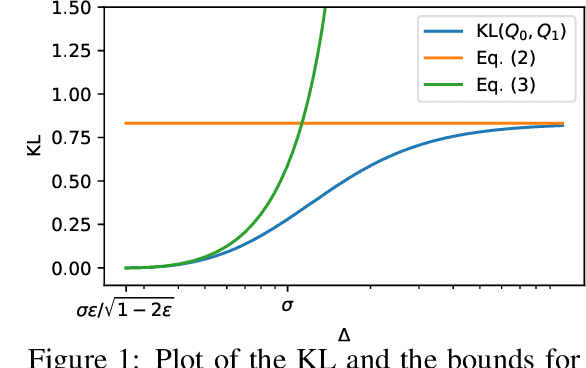


In this paper, we study the stochastic bandits problem with $k$ unknown heavy-tailed and corrupted reward distributions or arms with time-invariant corruption distributions. At each iteration, the player chooses an arm. Given the arm, the environment returns an uncorrupted reward with probability $1-\varepsilon$ and an arbitrarily corrupted reward with probability $\varepsilon$. In our setting, the uncorrupted reward might be heavy-tailed and the corrupted reward might be unbounded. We prove a lower bound on the regret indicating that the corrupted and heavy-tailed bandits are strictly harder than uncorrupted or light-tailed bandits. We observe that the environments can be categorised into hardness regimes depending on the suboptimality gap $\Delta$, variance $\sigma$, and corruption proportion $\epsilon$. Following this, we design a UCB-type algorithm, namely HuberUCB, that leverages Huber's estimator for robust mean estimation. HuberUCB leads to tight upper bounds on regret in the proposed corrupted and heavy-tailed setting. To derive the upper bound, we prove a novel concentration inequality for Huber's estimator, which might be of independent interest.
Bregman Deviations of Generic Exponential Families
Jan 18, 2022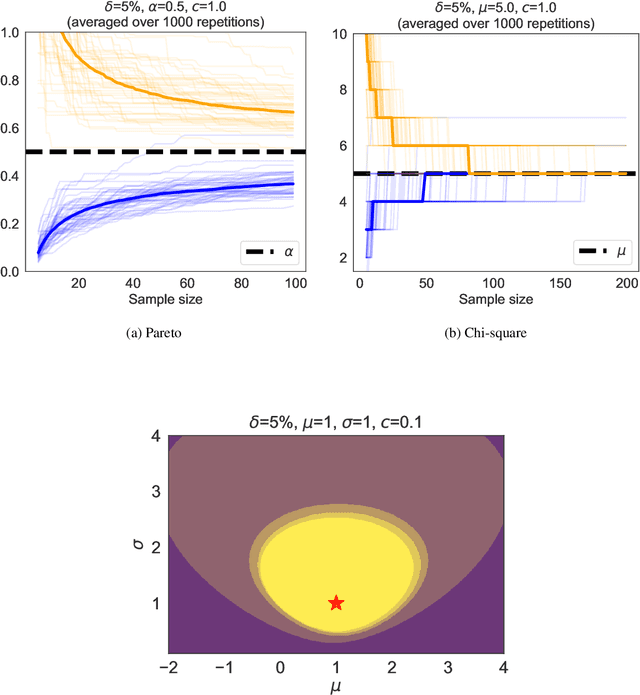
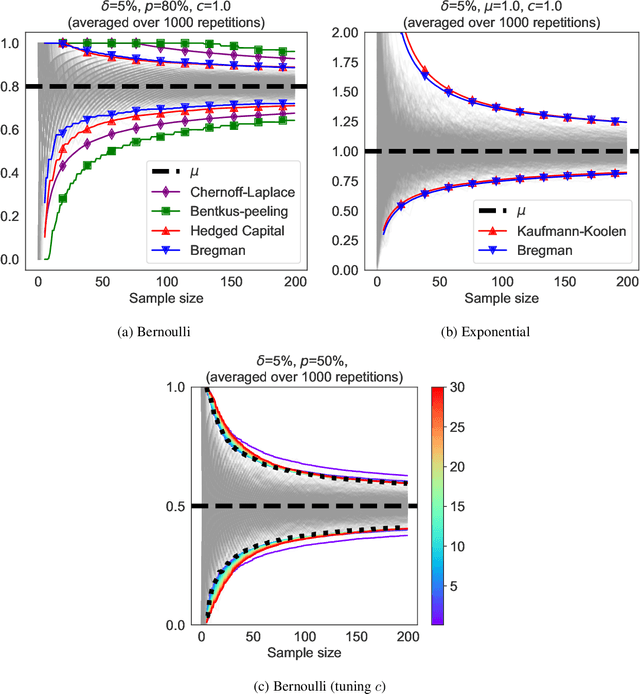


We revisit the method of mixture technique, also known as the Laplace method, to study the concentration phenomenon in generic exponential families. Combining the properties of Bregman divergence associated with log-partition function of the family with the method of mixtures for super-martingales, we establish a generic bound controlling the Bregman divergence between the parameter of the family and a finite sample estimate of the parameter. Our bound is time-uniform and makes appear a quantity extending the classical \textit{information gain} to exponential families, which we call the \textit{Bregman information gain}. For the practitioner, we instantiate this novel bound to several classical families, e.g., Gaussian, Bernoulli, Exponential and Chi-square yielding explicit forms of the confidence sets and the Bregman information gain. We further numerically compare the resulting confidence bounds to state-of-the-art alternatives for time-uniform concentration and show that this novel method yields competitive results. Finally, we highlight how our results can be applied in a linear contextual multi-armed bandit problem.
Indexed Minimum Empirical Divergence for Unimodal Bandits
Dec 02, 2021
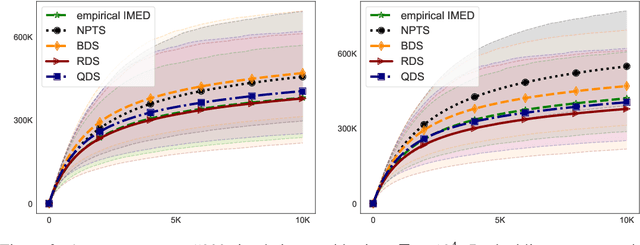
We consider a multi-armed bandit problem specified by a set of one-dimensional family exponential distributions endowed with a unimodal structure. We introduce IMED-UB, a algorithm that optimally exploits the unimodal-structure, by adapting to this setting the Indexed Minimum Empirical Divergence (IMED) algorithm introduced by Honda and Takemura [2015]. Owing to our proof technique, we are able to provide a concise finite-time analysis of IMED-UB algorithm. Numerical experiments show that IMED-UB competes with the state-of-the-art algorithms.
From Optimality to Robustness: Dirichlet Sampling Strategies in Stochastic Bandits
Nov 18, 2021


The stochastic multi-arm bandit problem has been extensively studied under standard assumptions on the arm's distribution (e.g bounded with known support, exponential family, etc). These assumptions are suitable for many real-world problems but sometimes they require knowledge (on tails for instance) that may not be precisely accessible to the practitioner, raising the question of the robustness of bandit algorithms to model misspecification. In this paper we study a generic Dirichlet Sampling (DS) algorithm, based on pairwise comparisons of empirical indices computed with re-sampling of the arms' observations and a data-dependent exploration bonus. We show that different variants of this strategy achieve provably optimal regret guarantees when the distributions are bounded and logarithmic regret for semi-bounded distributions with a mild quantile condition. We also show that a simple tuning achieve robustness with respect to a large class of unbounded distributions, at the cost of slightly worse than logarithmic asymptotic regret. We finally provide numerical experiments showing the merits of DS in a decision-making problem on synthetic agriculture data.